13 Lecciones del genoma
Tras la reñida carrera por descifrar el genoma humano, las partes en competición estaban de acuerdo al menos en una cosa: el «libro de la humanidad» contenía, con toda seguridad, una enorme cantidad de genes.
Craig Venter había demostrado que la mosca de la fruta poseía aproximadamente 13.500 genes. El proyecto de John Sulston para secuenciar el genoma de Caenorhabditis elegans (un gusano microscópico) había revelado alrededor de 19.000 genes. En aquel entonces, se consideraba que la vida humana era tan compleja que, para escribir las instrucciones del genoma humano, eran necesarios unos 100.000, e incluso una compañía de biotecnología señalaba haber caracterizado 300.000 genes humanos.
La publicación de los dos primeros borradores de la secuencia genómica en 2001 constituyó una gran sorpresa en este sentido. Los primeros análisis indicaban que contenía tan sólo entre 30.000 y 40.000 genes, y esta cifra ha disminuido desde entonces de manera constante. El último recuento es de aproximadamente 21.500 genes, es decir, una cifra algo mayor que la correspondiente al pez cebra y ligeramente inferior a la del ratón. Esto hace evidente la poca correlación entre la complejidad biológica de un organismo y su número de genes con capacidad de codificación en proteínas.
Un gen, muchas proteínas Desde que los experimentos de George Beadle y Edward Tatum en la década de 1940 demostraron que los genes elaboran proteínas, el concepto de que cada gen codificaba una sola proteína se convirtió en una especie de mantra de la biología molecular. No obstante, hoy sabemos que hay cientos de miles de proteínas y tan sólo unas pocas docenas de miles de genes humanos. Tanto los genes como las proteínas tienen una versatilidad mayor de la que se suponía en un principio.
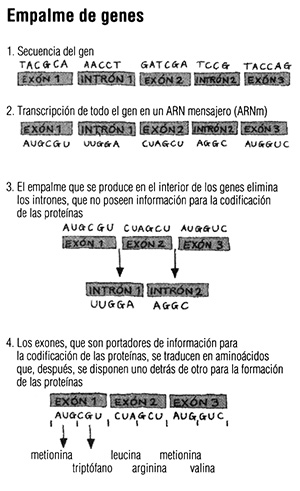
De hecho, cada gen puede contener la «receta» de muchas proteínas distintas, debido en parte a su estructura. Tal como se explica en el capítulo 9, solamente los exones son portadores de instrucciones para la síntesis proteica. Antes de la producción de las proteínas, la información de los intrones (que carecen de capacidad de codificación) se elimina del ARN mensajero y los exones quedan unidos entre sí.
Los exones se pueden empalmar de formas distintas, y este «empalme alternativo» significa que un único gen puede especificar múltiples proteínas. Además, algunos solamente producen fragmentos de proteínas que, a su vez, se pueden unir entre sí en órdenes diferentes para dar lugar a una gama aún mayor de enzimas. Las proteínas, una vez elaboradas, también pueden ser modificadas por las células. El resultado de todos estos procesos es la existencia de una población de proteínas, o «proteoma», mucho más diversa de lo que podría sugerir el recuento de los genes humanos.
El número sorprendentemente bajo de genes humanos también indica que el denominado «ADN basura» (junk DNA) (es decir, el 97-98% del genoma, sin capacidad para codificar proteínas) podría ser más importante de lo que se había supuesto. Algunas regiones sin capacidad de codificación producen mensajeros celulares distintos constituidos por formas especiales de ARN (véase el capítulo 48) que actúan como interruptores que activan y desactivan la actividad de los genes, o bien dirigen el proceso de empalme a modificaciones en la proteína elaborada por un gen. Actualmente se considera que una parte importante del denominado «ADN basura» es cualquier cosa menos «basura» (véase el capítulo 45): es clave para regular cómo se expresan los genes, y tiene tanta significación fisiológica como los genes en sí mismos.
Variación entre las especies Cuando se comparó el genoma humano con el de otras especies, quedó claro que la mayor parte se compartía con otros organismos. El genoma humano comparte, aproximadamente, un 99% con el del chimpancé y alrededor del 97,5% con el del ratón. La selección natural no premia los cambios en tanto que tales, y por ello la evolución tiende a «conservar» los genes que funcionan bien. Un código muy similar que elabore una proteína también muy similar lleva a cabo un trabajo muy parecido en especies relacionadas. No es frecuente que la evolución elimine genes o los cree completamente nuevos, de manera que no es extraño que la mayor parte de los mamíferos posea un número de genes comparable.
¿Está completo el genoma?
La mayoría de la gente piensa que la secuenciación del genoma humano ya se realizó en el año 2000, cuando en la conferencia de prensa de la Casa Blanca se anunció la hazaña, o bien en 2001, cuando los grupos rivales publicaron sus datos. Sin embargo, todo lo que se había conseguido hasta ese momento eran bocetos de trabajo plagados de lagunas: todavía no ha sido posible secuenciar casi el 20% del código. Incluso en la supuesta versión «completa», publicada en 2003, todavía faltaba aproximadamente el 1% de las regiones con capacidad de codificación de proteínas, además de una proporción incluso mayor del «ADN basura» sin capacidad de codificación. En este momento siguen activas las iniciativas para rellenar esas lagunas y todavía no se han cartografiado las secuencias de ciertos segmentos; por ejemplo, los centrómeros en la parte media de los cromosomas y los telómeros en sus extremos. Estas áreas contienen tanta cantidad de ADN repetitivo que la tecnología convencional tiene dificultades para leerlo.
Lo que sí suele ocurrir es que unos pocos genes se reúnen para llevar a cabo funciones nuevas. Muchos adquieren ligeras mutaciones peculiares de una especie concreta que les permiten desempeñar tareas nuevas.
Muchas de las diferencias entre el ser humano y otros animales se deben a que algunos de los genes compartidos han experimentado modificaciones que hacen que su funcionamiento sea ligeramente distinto. Otras diferencias parecen reflejar cambios en las regiones reguladoras del «ADN basura» y en los mensajes que envían a través del ARN.
No hay genoma humano
Cuando hablamos del genoma humano, estamos refiriéndonos, en cierto modo, a una entidad ficticia. Sólo los gemelos idénticos (monocigóticos) comparten absolutamente todas las letras del código genético y, excepto en este caso, podemos considerar que todas las demás personas son únicas. Lo que nos ofrece la secuencia del genoma humano es un promedio, es decir, un punto de referencia para comparar todas nuestras variaciones genéticas. Nos indica la localización de los genes más importantes que compartimos y facilita la investigación relativa a su función. Así, cuando los científicos encuentran SNP que parecen estar relacionados con una enfermedad, es posible localizarlos en sus genes y obtener información acerca de sus efectos.
Variaciones entre individuos Por supuesto, desde el punto de vista genético, las personas se parecen más unas a otras que el ser humano al chimpancé. Según los parámetros de medida estándar, el 99,9% de la secuencia del genoma es universal y compartido por todas las personas del planeta. Sin embargo, el 0,1% del ADN total, que no es compartido, ofrece amplias oportunidades para la variación: los 3.000 millones de pares de bases en el genoma hacen que haya 3.000 millones de posibilidades de que el ADN de dos individuos sea distinto.
Este tipo de variación conlleva la sustitución aleatoria de una letra del ADN por otra. Las localizaciones en las que tiene lugar se denominan polimorfismos de nucleótido único (SNP, single nucleotide polymorphisms). Muchos SNP no dan lugar a ningún efecto; tal como se expone en el capítulo 9, el código genético es redundante, de manera que algunas mutaciones no modifican la secuencia de aminoácidos de las proteínas. Sin embargo, otras mutaciones introducen diferencias importantes en las proteínas producidas por un gen o bien alteran la forma con la que el «ADN basura» controla la expresión genética.
Los SNP son uno de los elementos principales para que la genética haga que los individuos sean diferentes. Algunos de ellos inducen efectos triviales, modificando el color del pelo o de los ojos. Otros son perjudiciales debido a que causan directamente una enfermedad o bien alteran el metabolismo de manera que las personas que los presentan son más vulnerables a diversas enfermedades. Los SNP son los responsables de una parte importante de la variedad de la vida humana.
Cronología:
1941: Beadle y Tatum demuestran que los genes elaboran las proteínas
1961: Nirenberg descubre el primer código de tripletes para un aminoácido
Década de 1990: Se estima que el número de genes humanos es de 100.000 o más
2001: El Proyecto Genoma Humano demuestra que el número total de genes no es superior a 40.000
2008: La última estimación del recuento de genes humanos es de 21.500
La idea en síntesis: la variación genética no sólo se refiere a la aparición de genes nuevos