09 Craqueando el código de la vida
La doble hélice permitía explicar cómo se copian los genes y, así, la manera con la que la información genética se transmite fiablemente de una célula a otra y de una generación a la siguiente. También sugería que las mutaciones en las letras que constituyen el ADN podían ser hereditarias, siguiendo así la idea de Darwin acerca de las modificaciones en la descendencia. Sin embargo, lo que esta estructura no pudo determinar fue la forma con la que los genes llevan a cabo otras tareas vitales distintas del proceso de copia: la síntesis de las proteínas que representan el fundamento de la biología.
El código de la vida estaba claramente escrito en un alfabeto de cuatro letras —A, C, G y T— en el ADN, constituyendo así las instrucciones para la producción de los 20 aminoácidos de los que están formadas las proteínas. Sin embargo, hasta su descifre, el código carecía de sentido.
La clave provino de algunas propuestas teóricas de Francis Crick seguidas de los experimentos que llevaron a cabo el bioquímico norteamericano Marshall Nirenberg y el biólogo francés Jacques Monod, quienes obtuvieron diversos resultados concordantes. Poco más de 10 años después de su descubrimiento, escrito en la doble hélice, fue posible descifrar el código genético y establecer así un principio organizativo básico para la biología molecular.
La molécula adaptadora: el ARN mensajero Identificada la doble hélice del ADN, la siguiente genialidad de Francis Crick fue que el ADN se podía traducir en aminoácidos por medio de una «molécula adaptadora», es decir, un intérprete que transmitía las órdenes desde los genes hasta los órganos celulares que elaboran las proteínas.
En 1960 el equipo de Monod utilizaba bacterias y virus bacteriófagos que parasitan bacterias para demostrar que, en efecto, el ADN produce una molécula adaptadora constituida por un compuesto químico estrechamente relacionado con el ADN y denominado ácido ribonucleico (ARN).
El ARN es similar al ADN, pero presenta algunas diferencias estructurales. La más importante es la de que en vez de la base timina utiliza un nucleótido similar denominado uracilo (U). También es más inestable, presenta un ciclo vital más breve en la célula y forma muchos tipos diferentes de moléculas que desempeñan funciones especializadas. La molécula adaptadora de Crick es una forma denominada ARN mensajero (ARNm), una molécula de una sola cadena en la que se «transcriben» los genes. Este ARNm se utiliza para la elaboración de las proteínas mediante un proceso denominado traducción.
El dogma central
Otra de las contribuciones importantes de Francis Crick fue lo que él mismo denominó el «dogma central» de la biología, que indica que la información genética se desplaza generalmente a través de un sistema unidireccional. El ADN se puede copiar a sí mismo en ADN o bien se puede transcribir en ARNm, mientras que el ARNm puede dar lugar a la producción de una proteína; sin embargo, no es posible revertir el proceso.
Hay tres excepciones a esta norma. Algunos virus pueden replicarse a sí mismos mediante la copia directa del ARN en ARN, o bien pueden llevar a cabo una «transcripción inversa» desde el ARN hacia el ADN. También es posible la traducción directa del ADN en una proteína, aunque únicamente en el laboratorio. De todas formas, la información contenida en las proteínas nunca se puede convertir en ARN, ADN u otras proteínas: es imposible debido a la redundancia del código genético.
Al igual que en la replicación, la doble hélice se abre como una cremallera; después, una de las cadenas es leída para producir una cadena de ARNm que representa una imagen especular de la primera. En esta transcripción, las C de los genes se convierten en G en el ARNm; las T en A; las G en C, y las A en U; es decir, en la molécula de ARN, el uracilo sustituye a la timina del ADN. Estas señales genéticas migran después desde el núcleo de la célula hasta las estructuras celulares que elaboran las proteínas, denominadas ribosomas, en las que los aminoácidos se ensamblan en cadenas siguiendo un orden que viene especificado por el código genético. Otro tipo de ARN, el ARN de transferencia, recoge los aminoácidos y los alinea en la cadena proteica en fase de crecimiento. La inestabilidad del ARNm hace, como en Misión imposible, que los mensajes se autodestruyan cuando ya han realizado su función.
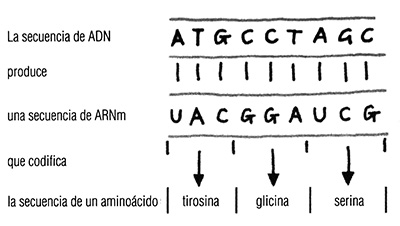
Tripletes Sin embargo, ¿cómo determinan los ribosomas el orden en el que se deben disponer los aminoácidos? Además, ¿cómo saben cuáles son los puntos de inicio y finalización de las cadenas proteicas? Las respuestas están en la secuencia de bases de los genes, a través de las cuales el ADN y el ARNm especifican los aminoácidos concretos. El código, propuesto inicialmente por Crick, es extremadamente sencillo y se fundamenta en combinaciones de tres letras del ADN denominadas «tripletes».
El significado de estos tripletes empezó a ser conocido gracias al trabajo de Nirenberg, un investigador que en 1961 mezcló ribosomas de la bacteria E. coli con aminoácidos y con bases de ARN. Al añadir uracilo puro, el resultado fue la aparición de largas cadenas similares a proteínas constituidas por el aminoácido fenilalanina. En ese momento se descifró el primer triplete, en el sentido de que el ARNm que lleva el mensaje «UUU» significa «coloca una molécula de fenilalanina en la cadena de la proteína». Al cabo de 5 años ya se había establecido el significado de las 64 combinaciones de las cuatro bases. El código había sido descifrado.
Exones e intrones
No todo el ADN de un gen se utiliza realmente para la producción de proteínas. Las partes fundamentales para esta función se denominan exones. Los exones están entremezclados con fragmentos de ADN sin capacidad de codificación denominados intrones, que carecen de relación con la información del gen que permite elaborar la proteína. Cuando todo el ADN se copia en ARNm, los intrones son modificados por enzimas especiales y los exones se empalman de manera conjunta para establecer el orden correspondiente a una proteína. Una buena analogía sería ver una película en la televisión: las escenas que nos interesan son los exones, pero éstos están fragmentados por los anuncios, los intrones, que no forman parte de la película. Si queremos ver toda la película seguida, podemos pasar con rapidez los anuncios para verlos de una sola vez, tal como hace el ribosoma en su lectura de las cadenas empalmadas correspondientes a los exones.
Hay 64 posibles tripletes o «codones», a pesar de que solamente existen 20 aminoácidos, lo cual quiere decir que algunos aminoácidos son especificados por más de un codón. Por ejemplo, la fenilalanina no solamente está codificada por el codón UUU, sino también por el codón UUC. Cada uno de los aminoácidos leucina, serina y arginina puede ser codificado por seis codones. Sólo dos de los 20 aminoácidos están codificados por un codón único: el triptófano (UGG) y la metionina (AUG). El codón AUG también se denomina «codón de inicio», debido a que indica a los ribosomas que comiencen a añadir aminoácidos; esto significa que, en la mayoría de las proteínas, el aminoácido inicial es la metionina. También existen «codones de interrupción» (UUA, UAG o UGA) cuyo mensaje al ribosoma es el siguiente: «la proteína ya está completa».
Este sistema no es tan sencillo como parece. El propio Crick propuso, en primer lugar, un código más elegante con 20 posibles tripletes o codones, uno por cada aminoácido. Sin embargo, lo que a la versión natural le falta de elegancia, lo tiene de sustancia, puesto que la redundancia ofrece ventajas considerables. El hecho de que los aminoácidos más importantes puedan ser generados por codones múltiples crea una resistencia ante las mutaciones. Por ejemplo, la glicina puede estar codificada por los codones GGA, GGC, GGG y GGU; si la última base presenta una mutación, el producto sigue siendo el mismo.
«Parece fuera de toda duda que una cadena única de ARN puede actuar como ARN mensajero.»
Francis Crick
Mediante este método disminuyen las posibilidades de que se produzcan errores catastróficos en el mecanismo de copia que podrían comprometer a todo un organismo. Aproximadamente la cuarta parte de todas las posibles mutaciones son «sinónimas» en este sentido, y el efecto de la selección natural implica que una proporción todavía mayor de las que sobreviven (alrededor del 75%) no tienen ningún efecto sobre la función de una proteína. El código genético constituye una especie de lenguaje «infantil» que permite un número de variaciones que no resultan excesivas ni escasas, sino las justas para la evolución.
Cronología:
1958: Crick propone un sistema de codificación mediante tripletes para el ADN, la existencia de una molécula adaptadora de ARN y el «dogma central»
1960: Jacques Monod (1910-1966) demuestra que el ARN mensajero es la molécula adaptadora
1961: Marshall Nirenberg (1927-2010) descubre el primer código de un triplete para un aminoácido
1966: Identificación del conjunto completo de los 64 tripletes.
La idea en síntesis: el código está escrito en tripletes