13
Non conta
Nel 1996, un gruppo di scienziati e ingegneri era pronto a lanciare quattro satelliti per studiare la magnetosfera terrestre. Il progetto aveva richiesto un decennio di lavoro di pianificazione, progettazione, test e costruzione. Si tratta di un processo lento perché, quando un satellite si trova nello spazio, condurre eventuali riparazioni è molto difficile; di conseguenza, gli errori vanno assolutamente evitati e ogni cosa dev’essere controllata tre volte. Appena fu terminata la loro costruzione, i satelliti di quella che oggi è nota come la missione Cluster furono caricati su un razzo Ariane 5 dell’Agenzia spaziale europea (ESA) nel giugno del 1996, pronti per essere lanciati in orbita dal Centro spaziale guyanese, nel Sudamerica.
Non sapremo mai se quei satelliti avrebbero funzionato come previsto, perché a meno di quaranta secondi dal decollo l’Ariane attivò il suo sistema di autodistruzione ed esplose in cielo. Le parti del razzo e del suo carico piovvero su un’area di 12 chilometri quadrati di savana e paludi di mangrovie nella Guyana francese.
Uno dei principali responsabili delle indagini sulla missione Cluster opera ancora al Mullard Space Science Laboratory (parte della University College di Londra), dove ora lavora mia moglie. Dopo il disastro, alcune parti dei satelliti vennero recuperate e rispedite all’UCL, dove gli investigatori aprirono il pacco per vedere anni di lavoro ora rappresentati da pezzi contorti di metallo con qualche traccia di palude ancora attaccata. Oggi sono in mostra nella sala comune del personale, per ricordare alle future generazioni di scienziati spaziali che stanno spendendo le loro carriere su idee che possono svanire in un soffio con l’esplosione del secondo stadio di un razzo.

Un decennio di duro lavoro ridotto a pezzi contorti di metallo e di apparecchiature elettroniche.
Per fortuna, l’ESA decise di non abbandonare la missione e di fare un altro tentativo. I satelliti Cluster II furono quindi messi in orbita nel 2000 da un razzo russo; e sebbene secondo il piano originale dovessero rimanere nello spazio per soli due anni, sono ormai quasi due decenni che operano con successo.
Che cosa andò storto, dunque, con il razzo Ariane 5? In breve, il computer di bordo cercò di copiare un numero a 64 bit in uno spazio di 16 bit. I rapporti che si leggono online parlano sbrigativamente di un errore di conti, ma resta il fatto che, perché ciò potesse accadere, il codice del computer doveva essere stato scritto in un determinato modo. La programmazione non è nient’altro che una formalizzazione di pensiero e processi matematici. Io volevo sapere quale fosse quel numero, perché era stato copiato in una posizione della memoria che era troppo piccola e perché aveva provocato la distruzione di un intero razzo… Così, scaricai il rapporto delle indagini pubblicato dalla commissione d’inchiesta dell’ESA e lo lessi attentamente da cima a fondo.
Il programmatore (o il team di programmatori) originale di quel codice aveva lavorato in modo brillante. Aveva messo insieme un Sistema di riferimento inerziale (SRI) perfettamente funzionante che permetteva al razzo di sapere sempre con esattezza dove si trovava e che cosa stava facendo. In sostanza, un SRI fa da interprete tra i sensori che tengono traccia della rotta del razzo e il computer che lo guida. L’SRI poteva essere collegato a diversi sensori posizionati in più punti del razzo, prendendo i dati grezzi provenienti da giroscopi e accelerometri e convertendoli in informazioni significative. L’SRI era inoltre collegato al principale computer di bordo, a cui passava tutti i dettagli riguardo alla direzione in cui era rivolto il razzo e alla velocità con cui si muoveva.
Nel corso di questo lavoro di traduzione, l’SRI convertiva ogni dato tra formati differenti, aspetto che costituisce l’habitat naturale degli errori di calcolo informatici. I programmatori identificarono sette casi in cui un valore in virgola mobile arrivava da un sensore e veniva convertito in un numero intero; esattamente il tipo di situazione nella quale un numero più lungo potrebbe essere inserito accidentalmente in uno spazio troppo piccolo, cosa che porterebbe il programma ad arrestarsi con un errore di operando.
Per evitarlo, era possibile aggiungere qualche altra riga di codice che esaminasse i valori in arrivo e si chiedesse: «Questo causerà un errore di operando se cercheremo di convertirlo?». Il ricorso generalizzato a questo processo potrebbe garantire una salvaguardia globale dagli errori di conversione; tuttavia, chiedere al programma di eseguire un controllo aggiuntivo ogni volta che sta per essere fatta una conversione comporta un pesante sforzo per il processore, e al team erano stati imposti severi limiti sulla quantità di potenza di calcolo che il loro codice avrebbe potuto usare.
Non c’è problema, pensarono: facciamo un passo indietro, guardando i sensori che stanno mandando i dati all’SRI, e vediamo che gamma di valori potrebbero produrre. Per tre dei sette casi, scoprirono che l’input non poteva mai essere abbastanza grande da causare un errore di operando, pertanto non venne aggiunta nessuna protezione. Le altre quattro variabili, invece, avrebbero potuto essere troppo grandi e quindi avrebbero sempre dovuto passare attraverso il controllo di sicurezza.
Era una soluzione perfetta… per il razzo Ariane 4, il precursore dell’Ariane 5. Dopo anni di fedele servizio, l’SRI venne estratto dall’Ariane 4 e usato nell’Ariane 5 senza che venisse fatto un adeguato controllo del codice. Solo che l’Ariane 5 era progettato per una traiettoria di decollo differente da quella dell’Ariane 4, che richiedeva velocità orizzontali più grandi nei primi momenti del lancio. Con la traiettoria dell’Ariane 4, la velocità orizzontale non sarebbe mai stata abbastanza grande da causare un problema; di conseguenza, non era tra le variabili controllate. Sull’Ariane 5, però, il valore superava in breve tempo lo spazio disponibile nell’SRI, e il sistema restituiva un errore di operando. Ma non fu soltanto questo a causare l’esplosione del razzo.
Se nel volo di un razzo tutto andava storto e la situazione sarebbe chiaramente finita in un disastro, l’SRI era stato programmato per svolgere alcuni compiti amministrativi negli ultimi momenti. La cosa più importante era che salvava in una posizione separata tutti i dati su quello che stava facendo; dati che sarebbero stati vitali nelle indagini successive e che quindi valeva la pena accertarsi che venissero messi al sicuro. Un po’ come chi grida come sua ultima frase: «Dite a mia moglie che l’amo!»; solo che, trattandosi di un processore, il suo ultimo grido era: «Dite al mio debugger i seguenti dati relativi al contesto del disastro!».
Nel sistema dell’Ariane 4, l’SRI scaricava i dati su un supporto di memoria esterno. Purtroppo, nell’Ariane 5 l’SRI mandava questo «rapporto sul crash» al computer di bordo attraverso la connessione principale. Il nuovo computer di bordo dell’Ariane 5 non era mai stato avvertito che avrebbe potuto ricevere un rapporto diagnostico qualora l’SRI si fosse preparato al peggio; così, assunse che si trattasse di altre informazioni di volo e cercò di interpretarle come tali, leggendo i dati come fossero angoli e velocità. È una situazione curiosamente simile a quella in cui Pac-Man ha un errore di overflow e tenta di decifrare i dati del gioco come se fossero dati della frutta; tranne che qui ci sono in ballo degli esplosivi.
Avendo assunto che il rapporto di errore erano informazioni di navigazione, l’interpretazione migliore trovata dal computer di bordo fu che il razzo aveva improvvisamente deviato di lato; e quindi, fece la cosa più logica in quella situazione: eseguì l’equivalente di una sterzata a tutta forza nella direzione opposta. Dato che i collegamenti tra il computer di bordo e i pistoni che orientavano i propulsori del razzo funzionavano alla perfezione, il comando del computer venne eseguito, facendo ironicamente sì che il razzo virasse bruscamente di lato.
Il destino dell’Ariane 5 era a questo punto segnato: in breve tempo, si sarebbe schiantato a terra. Alla fine, però, quella manovra ad alta velocità strappò in parte i propulsori ausiliari dal corpo principale del razzo, cosa universalmente considerata come piuttosto brutta. Così, il computer di bordo decise correttamente di farla finita e avviò il sistema di autodistruzione, generando una pioggia di frammenti dei quattro satelliti Cluster su tutta la sottostante palude di mangrovie.
L’ultimo buco allineato nel formaggio è che, durante il lancio, il sensore di velocità orizzontale non era neppure necessario; di fatto, veniva usato per calibrare la posizione del razzo prima del lancio e non era affatto richiesto durante il decollo. Sennonché, quando i lanci dell’Ariane 4 venivano abortiti prima del decollo, resettare ogni cosa una volta che i sensori si erano spenti era una gran fatica; si decise quindi di aspettare per circa cinquanta secondi di volo prima di spegnerli, in modo da essere sicuri che il lancio fosse davvero avvenuto. Tutto questo non era più necessario con l’Ariane 5, ma la procedura era rimasta nel codice come un vestigio del sistema precedente.
In generale, riutilizzare un codice senza testarlo nella nuova situazione è una cosa che può causare diversi problemi. Ricordate la macchina per la radioterapia Therac-25, che aveva un problema di roll-over-256 a causa del quale poteva sottoporre i pazienti a overdosi di radiazioni? Nel corso delle indagini, si scoprì che il modello precedente, la Therac-20, aveva i medesimi problemi nel suo software ma disponeva di blocchi fisici di sicurezza per impedire le overdosi, motivo per cui nessuno notò mai l’errore di programmazione. La Therac-25 riutilizzò quel codice senza però avere quei controlli fisici; di conseguenza, l’errore di roll-over si tradusse in un disastro.
Se c’è una morale in questa storia è che, quando scrivete un codice, dovete tenere a mente che magari, un giorno, qualcuno dovrà passarlo al vaglio e controllare ogni elemento al fine di riutilizzarlo per qualche altro scopo. Magari quel qualcuno sarete proprio voi, quando ormai vi sarete dimenticati da tempo la logica originale dietro al codice. Per questa ragione, i programmatori possono lasciare dei «commenti» nel loro codice, dei piccoli messaggi diretti a chiunque debba leggerlo. Il mantra dei programmatori dovrebbe essere «Commentate sempre il vostro codice». E scrivete dei commenti utili. Quando ho riletto un codice denso di comandi che avevo scritto anni prima, ho trovato un unico commento: «Buona fortuna, futuro Matt».
Invasori spaziali
Nella programmazione entra in gioco una grande combinazione di complessità e certezza assoluta. Ogni singola riga di codice è definita: un computer farà esattamente ciò che dice il codice. Ma determinare il risultato finale dell’interazione di innumerevoli righe di codice è piuttosto difficile, e questo può rendere il debugging dei programmi un’esperienza ricca di emozioni.
Sul piano più basso ci sono quelli che chiamo «errori di programmazione di livello zero». Si tratta dei casi in cui a essere sbagliata è la singola riga di codice. Qualche dettaglio in apparenza innocuo, come un punto e virgola dimenticato, può far bloccare un intero programma. Per indicare l’inizio e la fine delle affermazioni, i linguaggi di programmazione usano segni come punti e virgole, parentesi e interruzioni di riga, e se mancano vanno fuori di testa. Molti programmatori hanno speso ore a inveire contro gli schermi perché il loro codice non ne voleva sapere di funzionare, per poi scoprire che gli era sfuggito un invisibile spazio di tabulazione.
Questi sbagli sono l’equivalente informatico dei refusi. Nel 2006, un gruppo di biologi molecolari dovette ritrattare cinque articoli di ricerca, tra cui alcuni pubblicati su «Science» e uno su «Nature», per via di un errore nel loro codice. Avevano scritto un programma per analizzare i dati sulla struttura delle molecole biologiche, ma il codice cambiava accidentalmente alcuni valori positivi in negativi e viceversa; di conseguenza, quella parte della struttura da loro pubblicata era l’immagine speculare della configurazione corretta.
Questo programma, che non faceva parte di un pacchetto convenzionale per l’elaborazione dei dati, convertiva le coppie anomale (I+ e I-) in (F- e F+), introducendo così un cambiamento di segno.
– Ritrattazione di Structure of MsbA from E. coli
Un refuso in una singola riga di codice è in grado di fare danni enormi. Nel 2014, un programmatore stava facendo manutenzione su un server e voleva cancellare una vecchia directory di backup chiamata /docs/mybackup/ o qualcosa del genere, ma scrisse il nome inserendo per sbaglio uno spazio in più: /docs/mybackup /. Qui di seguito potete vedere l’intera riga digitata al computer. Non lo ripeterò mai abbastanza: non vi venga neppure in mente di scrivere una cosa del genere sul vostro computer, in quanto potrebbe cancellare tutte le cose che amate e che vi sono care.
sudo rm -rf --no-preserve-root /docs/mybackup /
sudo = super user do: dice al computer che siete un superutente (un amministratore del sistema) e che deve fare tutto quello che dite senza obiezioni
rm = remove: rimuovi, sinonimo di «cancella»
-rf = recursive, force: forza il comando a procedere ricorsivamente attraverso un’intera directory
--no-preserve-root = nulla va considerato sacro
Così ora, invece di cancellare una singola directory chiamata /docs/mybackup /, il computer ne avrebbe cancellate due: /docs/mybackup e /. La cosa divertente riguardo a / è che rappresenta la directory radice del sistema, quella di livello più basso che contiene tutte le altre cartelle: in sostanza, / rappresenta l’intero computer. Online circolano diverse storie su persone che, attraverso il comando rm -rf, hanno cancellato tutto quello che c’era sul loro computer o, in alcuni casi, su quelli di un’intera azienda. E tutto a causa di un solo refuso.
Considero come errori di livello zero anche quegli sbagli che non sono veri e propri refusi ma che sono più assimilabili a errori di traduzione. Un programmatore ha in mente i passaggi che vuole faccia il computer, ma deve tradurli dal pensiero umano a un linguaggio di programmazione che la macchina possa comprendere. Gli errori di traduzione possono rendere incomprensibile un’affermazione, come nel caso di quel piatto della cucina del Sichuan il cui nome viene talvolta tradotto sui menu come «saliva chicken». Nessuno lo ordinerà mai: il significato originale di «mouth-watering chicken» («pollo che fa venire l’acquolina in bocca») si è perso nella traduzione.
Il concetto di «uguali» può essere tradotto nel linguaggio dei computer come = o come ==. In molti linguaggi di programmazione, = è un comando per rendere le cose uguali, mentre == è una domanda che chiede se le cose sono uguali. Così, un’espressione come cat_name = Angus darà al vostro gatto il nome di Angus, mentre cat_name == Angus avrà in risposta True o False, a seconda di quale sia il nome del gatto che avete. Se usate il segno sbagliato, il codice entra in crisi.
Alcuni linguaggi di programmazione cercano di rendervi la vita il più facile possibile venendovi incontro a metà strada e sforzandosi di comprendere quello che state cercando di dire. È per questo che, come programmatore hobbista, uso Python, il più amichevole di tutti i linguaggi. Poi i linguaggi che non fanno nessuno sconto ai possibili errori commessi dal programmatore, ma che perlomeno non agiscono con perfidia. Rappresentano la stragrande maggioranza delle opzioni disponibili per chi programma: C++, Java, Ruby, PHP… e così via.
E poi, com’è ovvio, ci sono i linguaggi che odiano il concetto stesso di essere umano. Sono nati perché ci sono dei programmatori che pensano di essere spiritosi e che vedono la creazione di linguaggi di programmazione deliberatamente ostici quasi come uno sport. L’esempio classico è costituito da un linguaggio chiamato brainf_ck, che qui ho un po’ censurato.1 Penso che il nome ufficiale di «BF», che viene usato nella buona società, non gli renda giustizia. In brainf_ck ci sono solo otto possibili simboli: < > + – [ ] , e . Ciò significa che anche i programmi più semplici avranno un aspetto simile al seguente:
++++[>+++++<-]>-[<++++++>+++++>++<<<-
]>-----.>++.<+++++++..+++.>.<----.>>+.<++++.<-.>.
Anche se brainf_ck viene spesso liquidato come una sorta di scherzo, penso che di fatto valga la pena di impararlo, perché mostra direttamente il modo in cui un linguaggio di programmazione conserva e manipola i dati. È come interagire direttamente con l’hard disk. Immaginate un programma che considera un singolo byte di memoria alla volta: < e > muovono il puntatore a sinistra e a destra; + e – incrementano o decrementano il valore corrente; [ e ] vengono usati per eseguire dei cicli mentre . e , sono i comandi per leggere e scrivere. Che, in fondo, è tutto quello che fa qualunque programma informatico: è il cuore della programmazione, di solito nascosto sotto altri strati di traduzione.
Se siete alla ricerca di un linguaggio che sia il più disorientante possibile, Whitespace fa al caso vostro. Ignora tutti i caratteri visibili presenti nel codice ed elabora solo quelli invisibili; per scrivere in Whitespace potete quindi usare soltanto delle combinazioni di spazi, tabulazioni e ritorni a capo.2 E questo prima di arrivare ai linguaggi di programmazione in cui: potete usare soltanto la parola «chicken»; il codice dev’essere formattato come se steste ordinando a un drive-in; oppure, tutto viene scritto come se fosse uno spartito musicale. La bias del sopravvissuto mi induce a pensare che i programmatori tendano a essere un branco di sadici che amano la frustrazione.
Tralasciando i refusi e i linguaggi che vogliono deliberatamente farci male, c’è un’intera classe di errori di programmazione che considero come gli sbagli «classici» di chi scrive un codice. Sono più facili da individuare nei programmi più vecchi, che dovevano essere ultraefficienti per poter girare su un hardware dalla potenza limitata; i programmatori erano così costretti a essere un po’ creativi, cosa che portava a degli effetti a catena inattesi.
I programmatori del videogioco arcade Space Invaders erano talmente assillati dal problema del limitato spazio di memoria del loro chip ROM che cercarono di risparmiare ogni bit possibile. Questa massimizzazione dell’efficienza portò a numerose stranezze che potevano essere sfruttate dai giocatori; alcune, però, erano talmente particolari che penso non fossero conosciute – o tantomeno sfruttate – da nessuno. Sono il genere di cose che si trovano nell’area grigia tra l’errore di programmazione vero e proprio e le conseguenze inattese.
Durante una partita a Space Invaders, i giocatori potevano sparare agli alieni che scendevano dall’alto, alla misteriosa astronave che di tanto in tanto attraversava la sommità dello schermo e ai loro stessi scudi protettivi. Il programma doveva controllare se un colpo sparato centrava qualcosa di importante. La rilevazione delle collisioni può essere difficile da codificare, e i programmatori di Space Invaders, cercando dei modi per semplificare il processo, si resero conto che tutti i colpi o centravano qualcosa oppure proseguivano fino a uscire dalla sommità dello schermo.
Così, dopo ogni colpo il programma aspetta per vedere se il proiettile colpisce l’astronave misteriosa o esce dallo schermo. Se non si verifica nessuna di queste due ipotesi, controlla la coordinata y della collisione per verificare a che altezza è avvenuta. Se è più alta dell’alieno più basso, deve aver colpito un alieno; non ci sono altre possibilità. È solo a questo punto che entra in gioco la parte del codice che si chiede: «Quale alieno è stato centrato?». È un po’ come con il processore SRI dei razzi Ariane: si fanno delle assunzioni sul tipo di dati che possono arrivargli e i controlli vengono eseguiti solo quando ce n’è davvero bisogno.
Gli alieni sono disposti in una griglia di cinque righe per undici colonne. Per tener traccia di tutti i cinquantacinque alieni, il programma assegna loro un numero da 0 a 54 e usa la formula 11 × RIGA + COLONNA = ALIENO per prendere la riga della collisione (da 0 a 4) e la sua colonna (da 0 a 10) e convertirle nel numero dell’alieno che è stato colpito.
Questo processo funzionava bene finché il giocatore non decideva strategicamente di sparare a tutti gli alieni tranne a quello più in alto a sinistra. Era l’alieno nella riga 4, colonna 0, ossia il numero 11 × 4 + 0 = 44. Il giocatore osserva quindi l’alieno 44 muoversi da un lato all’altro, scendendo lentamente, fino a quando sta per toccare il lato sinistro dello schermo nel suo passaggio finale, appena sopra gli scudi protettivi; a quel punto, il giocatore spara al proprio scudo situato all’estrema destra.
Il gioco lo registra come un colpo all’interno della griglia degli alieni e assume quindi che un alieno sia stato centrato. Lo scudo è talmente a destra che dovrebbe corrispondere alla posizione di una dodicesima colonna, ma il codice non si ferma a controllare: converte invece la coordinata orizzontale in un numero di colonna e ottiene 11, al di fuori del normale campo da 0 a 10. Inserendo questo numero di colonna scorretto nella formula ottiene quindi 11 × 3 + 11 = 44, e l’alieno all’estrema sinistra dello schermo esplode.

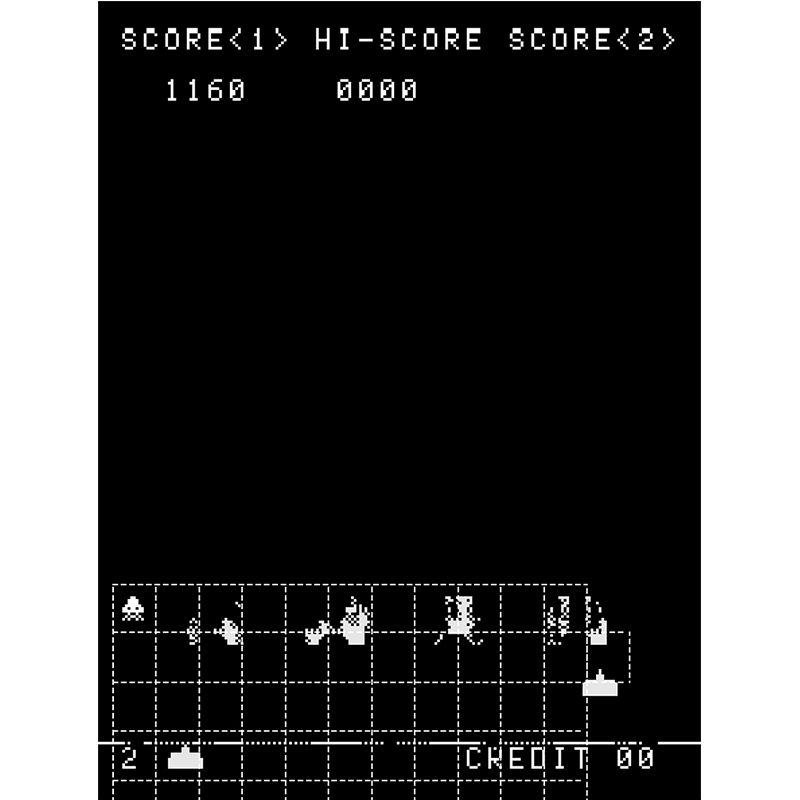
Una griglia di cinque-per-undici caselle sovrapposta alla formazione iniziale degli alieni. Un colpo sparato al momento giusto centra lo scudo dove ci dovrebbe essere una dodicesima colonna.
Ok, questo non sarà uno sbaglio clamoroso, ma serve a mostrarvi che anche un sistema semplice come quello di Space Invaders può finire in situazioni che i programmatori non avevano previsto. Il codice originale del videogioco non aveva commenti, ma al sito computerarcheology.com c’è un progetto online per analizzarlo e commentarlo interamente con note moderne. È una lettura divertente. Mi piacciono i codici con commenti del tipo «Controlla l’indicatore dello stato dell’alieno; è ancora vivo?». Qualunque commento che non sia del calibro di quelli scritti dal vecchio me, quando volevo fare lo stronzo, è gratificante.
L’e-mail con 800 chilometri di autonomia
Fare l’amministratore di sistema – o «sysadmin», come si dice – per una grossa rete di computer è già di per sé un lavoro ingrato; figuratevi poi quando la rete di computer in questione è quella di un’università sul finire degli anni Novanta. I dipartimenti universitari possono essere un po’ suscettibili in merito all’argomento autonomia; e se si considera anche l’aria da selvaggio West che caratterizzava ancora il web in quel periodo, abbiamo la ricetta per un disastro complicato.
Fu quindi con una certa trepidazione che, intorno al 1996, Trey Harris, un sysadmin dell’Università del North Carolina, rispose a una telefonata del preside del dipartimento di statistica. Avevano un problema con le e-mail. Alcuni dipartimenti, tra cui quello di statistica, avevano deciso di tenere dei server di e-mail privati, e Trey li aiutava informalmente a gestirli. Il che significava che questo era ora (informalmente) un suo problema.
«Abbiamo un problema con l’invio delle e-mail dal dipartimento.»
«Che problema?»
«Non riusciamo a mandarle a più di 800 chilometri di distanza.»
«Può ripetere?»
Il preside spiegò che nessuno nel dipartimento riusciva a mandare le e-mail a più di 840 chilometri. Con alcune di quelle spedite entro tale distanza l’invio falliva comunque, ma per tutte quelle mandate più lontano di 840 chilometri il sistema segnalava un errore. Il problema, a quanto pare, si trascinava da qualche giorno, ma non l’avevano riferito prima perché volevano raccogliere abbastanza dati per poter stabilire la distanza precisa. Uno dei loro geostatistici stava preparando una mappa molto accurata delle località dove le e-mail potevano o non potevano essere mandate.
Trey loggò incredulo nel loro sistema e mandò alcune e-mail di prova attraverso i loro server. Le e-mail locali e quelle inviate a Washington DC (390 chilometri), Atlanta (550 chilometri) e Princeton (640 chilometri) arrivarono ai destinatari, ma per tutte quelle mandate a Providence (930 chilometri), Memphis (965 chilometri) e Boston (1000 chilometri) l’invio non andò a buon fine.
Trey, alquanto agitato, provò quindi a mandare un’e-mail a un suo amico che viveva lì vicino, nel North Carolina, ma che utilizzava un server situato a Seattle (3770 chilometri). Per fortuna, l’invio fallì: se in qualche modo le e-mail avessero conosciuto la posizione geografica del destinatario a prescindere dal suo server, Trey sarebbe scoppiato a piangere. Perlomeno, ora sapeva che il problema aveva a che fare con la distanza del server ricevente. Tuttavia, nei protocolli delle e-mail non c’era nulla che dipendesse da quanta strada il segnale doveva percorrere.
Aprì quindi il file sendmail.cf, che contiene tutti i dettagli e le regole che governano l’invio delle e-mail. Ogni volta che un’e-mail viene spedita, passa da questo file per avere le istruzioni richieste per essere quindi girata al sistema di fatto responsabile dell’invio, Sendmail. Il file gli sembrava familiare, in quanto era stato lui a scriverlo. Non c’era niente che fosse fuori posto; avrebbe dovuto funzionare perfettamente con il sistema Sendmail.
Così, Trey controllò il sistema principale del dipartimento (collegandosi via telnet alla porta SMTP, per chi vuole avere tutti gli strazianti dettagli) e fu accolto dal sistema operativo Sun. Scavando un po’, scoprì che il dipartimento di statistica aveva da poco fatto aggiornare la copia di SunOS del suo server e che con l’aggiornamento era arrivata anche una versione di default di Sendmail 5. In precedenza, Trey aveva impostato il sistema per l’uso di Sendmail 8, ma ora la nuova versione di SunOS era subentrata con prepotenza e l’aveva declassato a Sendmail 5. Trey aveva scritto il file sendmail.cf assumendo che sarebbe stato sempre letto soltanto da Sendmail 8.
Ok, se nell’ultimo paragrafo vi siete appisolati, ora potete ridestarvi. Per farla breve, le istruzioni per l’invio delle e-mail erano state scritte per un sistema più recente e quando venivano inserite in uno più vecchio provocavano il classico problema di un programma che cerca di digerire dei dati che non erano stati pensati per lui. Una parte di quei dati consisteva nel tempo di «timeout», che in Sendmail 5 veniva digerito male e settato sul valore di default di zero.
Se un server manda un’e-mail e non riceve nessuna conferma della ricezione, deve decidere quando smettere di aspettare e considerare l’invio fallito, accettando il fatto che quell’e-mail sia ormai perduta per sempre. Ora che questo tempo di attesa era stato settato a zero, il server mandava l’e-mail e si arrendeva subito. Un po’ come quei genitori che hanno già convertito la cameretta del loro figlio in una stanza da cucito quando è ancora in viaggio per andare all’università.
In pratica non era esattamente pari a zero. Nel programma c’era ancora un ritardo di elaborazione di qualche millisecondo tra l’invio dell’e-mail e il momento in cui il sistema era in grado di darla ufficialmente per persa. Trey prese carta e matita e si mise a fare un po’ di calcoli approssimativi. Il college era direttamente connesso a Internet, così che le e-mail potevano lasciare il sistema in modo ultrarapido. Il primo ritardo si aveva quando il messaggio raggiungeva il router di destinazione, che inviava quindi una conferma di ricezione.
Se il server ricevente non era sotto un forte carico di lavoro e poteva mandare la risposta abbastanza in fretta, l’unico limite rimanente era quello della velocità del segnale. Trey usò il valore della velocità della luce nella fibra ottica per calcolare il tempo del viaggio di ritorno e, tenendo anche conto dei ritardi del router, vide che la distanza massima a cui un’e-mail poteva giungere era di circa 800 chilometri. In pratica, le e-mail avevano un’autonomia limitata dalla natura finita della velocità della luce.
Ciò spiegava pure il motivo per cui alcune e-mail venivano date per perse anche all’interno del raggio di 800 chilometri: i server di destinazione erano troppo lenti per far arrivare la conferma prima che il sistema d’invio smettesse di ascoltare. Bastò comunque reinstallare Sendmail 8, e il file di configurazione sendmail.cf ricominciò a essere letto correttamente dal server.
Tutto questo serve a mostrare che, per quanto alcuni sysadmin tendano a vedersi come dèi in Terra, anche loro devono obbedire alle leggi della fisica.
Interazioni umane
Nel 2001, stavo accendendo il computer che avevo assemblato e su cui avevo installato il sistema Windows, che mi aveva quasi accompagnato per tutti gli anni di università, quando sulla schermata di caricamento del BIOS apparve la seguente scritta in caratteri bianchi su sfondo nero:
Keyboard error or no keyboard present
Press F1 to continue, DEL to enter SETUP.
Avevo sentito della famiglia di messaggi di errore «Nessuna tastiera rilevata, premere un tasto qualunque per continuare», ma non ne avevo mai incontrato uno dal vivo. Corsi a chiamare il mio compagno d’appartamento in modo che anche lui potesse venire a vedere. A casa non si parlò d’altro per giorni (ok, forse la mia memoria ha gonfiato un po’ la portata dell’evento). I messaggi d’errore sono sempre una fonte di intrattenimento nel mondo della tecnologia.
Eppure, esistono per una ragione. Se un programma si blocca e c’è un messaggio d’errore che specifica nel dettaglio che cosa ha portato al disastro, la persona incaricata di sistemare il tutto può partire in quarta. Purtroppo, però, molti messaggi d’errore dei computer si riducono a un codice di cui occorre andare a cercare il significato. Alcuni di questi codici d’errore sono ormai talmente onnipresenti che anche il pubblico non specializzato è in grado di comprenderli. Se qualcosa va storto durante la navigazione sul web, molte persone sanno che un «errore 404» vuol dire che il sito non è stato trovato. Di fatto, ogni errore relativo ai siti web che inizia con un 4 significa che la colpa era dal lato dell’utente (l’errore 403, per esempio, indica che si è cercato di accedere a una pagina proibita), mentre i codici che iniziano con un 5 indicano che la colpa è del server (l’errore 503 vuol dire che il server non è disponibile, mentre l’errore 507 che il server non ha spazio sufficiente per gestire le informazioni necessarie a rispondere alla richiesta).
Gli ingegneri di Internet, sempre spiritosi, hanno designato il codice di errore 418 come «I’m a teapot» («Io sono una teiera»). È l’errore restituito da ogni teiera connessa a Internet a cui viene richiesto di preparare un caffè. È stato introdotto con le specifiche Hyper Text Coffee Pot Control Protocol (HTCPCP, protocollo di controllo ipertestuale per caffettiere) pubblicate nel 1998. Anche se era nato come un pesce d’aprile, le teiere connesse in rete realizzate in seguito sono state costruite e funzionano in accordo con l’HTCPCP. Un tentativo di rimuovere questo errore è stato respinto nel 2017 dal Save 418 Movement, che ha sostenuto l’importanza di mantenerlo come «un promemoria del fatto che i processi alla base dei computer sono ancora opera degli uomini».
Essendo destinati a essere usati dai tecnici, molti messaggi d’errore dei computer sono strettamente funzionali e di certo non intuitivi. Ma quando degli utenti privi di competenze tecniche si trovano davanti a un messaggio d’errore marcatamente tecnico, le conseguenze possono essere gravi. Questo era uno dei problemi della macchina per la radioterapia Therac-25. L’apparecchiatura produceva una quarantina di messaggi d’errore al giorno, con nomi che non dicevano nulla, e dato che molti di essi non erano importanti gli operatori avevano preso l’abitudine di adottare soluzioni rapide che permettevano loro di ignorarli e continuare con i trattamenti. Alcuni dei casi di overdose avrebbero potuto essere evitati se l’operatore non avesse liquidato i messaggi di errore come irrilevanti scegliendo di andare avanti lo stesso.
In un caso, nel marzo del 1986, la macchina smise di funzionare e sullo schermo apparve il messaggio d’errore «Malfunction 54». Molti degli errori erano indicati solo dalla parola «Malfunction» seguita da un numero. Cercando il significato del malfunzionamento 54, si scopriva che era un «dose input 2 error»; quindi, dopo un’ulteriore ricerca, si vedeva che quest’ultima espressione segnalava che la dose era troppo alta o troppo bassa.
Tutti questi codici e queste descrizioni indecifrabili sarebbero anche comici se non fosse per il fatto che il paziente, nel caso del «Malfunction 54», morì per la risultante sovraesposizione alle radiazioni. Quando si tratta di attrezzature mediche, i messaggi d’errore pensati male possono costare delle vite. Una delle modifiche raccomandate prima che le Therac-25 potessero rientrare in servizio era: «I messaggi di malfunzionamento criptici verranno sostituiti con messaggi significativi».
Nel 2009, un gruppo di università e ospedali del Regno Unito si unì per formare il progetto CHI+MED: Interazione tra uomo e computer per le strumentazioni mediche. La loro idea era che si sarebbe potuto fare di più per limitare gli effetti potenzialmente pericolosi degli errori matematici e tecnologici nella medicina; e, in linea con il modello del formaggio svizzero, ritenevano che, anziché cercare dei singoli individui su cui scaricare la colpa, occorresse attrezzare l’intero sistema per renderlo capace di evitare gli errori.
Nel campo medico c’è l’impressione generale che le persone valide non commettano sbagli; istintivamente, riteniamo che l’operatore che aveva ignorato il messaggio sul malfunzionamento 54 e aveva premuto P sulla tastiera per procedere con la dose sia responsabile della morte di quel paziente. Le cose, però, sono più complicate. Come ha sottolineato Harold Thimbleby di CHI+MED, limitarsi a rimuovere chiunque ammetta di aver commesso uno sbaglio non è un buon sistema.
Le persone che ammettono di aver fatto degli errori vengono nel migliore dei casi sospese o trasferite, lasciando così sul posto una squadra che «non fa errori» e non ha nessuna esperienza su come gestirli.
– H. Thimbleby, Errors + Bugs Needn’t Mean Death, in «Public Service Review: UK Science & Technology», n. 2, 2011, pp. 18-19.
Thimbleby fa notare che, in campo farmaceutico, è illegale dare a un paziente la medicina sbagliata. In questo modo, però, non si promuove lo sviluppo di un ambiente nel quale gli errori vengono ammessi e corretti. Chi commette uno sbaglio e lo riconosce potrebbe perdere il lavoro. Questa bias del sopravvissuto potrebbe far sì che le nuove generazioni di studenti di farmacia abbiano come professori dei farmacisti che «non hanno mai sbagliato». Si viene così a perpetuare l’impressione che gli sbagli siano eventi poco frequenti; in realtà, però, tutti ne facciamo.
Nell’agosto del 2006, in Canada un paziente malato di cancro venne sottoposto a un trattamento chemioterapico con il farmaco Fluorouracil, da somministrare attraverso una pompa ambulatoriale da infusione che avrebbe dovuto rilasciare gradualmente la sostanza nell’arco di quattro giorni. Purtroppo, a causa di un errore nell’impostazione della pompa, tutto il farmaco venne somministrato in quattro ore e il paziente morì di overdose. Il modo più semplice di affrontare questa situazione consiste nel dare la colpa all’infermiera che aveva impostato la pompa e magari a quella che aveva controllato il suo lavoro; ma, come sempre, le cose sono un po’ più complicate.
5-Fluorouracil 5.250mg (a 4.000mg/m2) intravenosa continua nell’arco di quattro giorni… Infusione continua attraverso una pompa ambulatoriale da infusione (Dose di base a regime = 1.000mg/m2/giorno = 4.000mg/m2/4 giorni).
– Ordine elettronico del Fluorouracil
L’ordine originale di Fluorouracil era già di per sé difficile da seguire, ma poi venne passato a un farmacista che preparò 130 millilitri di una soluzione di Fluorouracil a 45,57 mg/ml. Quando questa preparazione arrivò all’ospedale, un’infermiera dovette calcolare la velocità di rilascio a cui impostare la pompa. Dopo aver fatto qualche conto con una calcolatrice, arrivò al valore di 28,8 millilitri; e, controllando sull’etichetta della farmacia, vide che la dose riportata era effettivamente di 28,8 millilitri.
Nei suoi calcoli, però, l’infermiera si era dimenticata di dividere il risultato per le ventiquattr’ore di cui è composta una giornata: aveva calcolato 28,8 millilitri al giorno assumendo che fossero 28,8 millilitri all’ora. Di fatto, l’etichetta indicava prima il valore di 28,8 millilitri al giorno e quindi, tra parentesi, la quantità oraria (1,2 ml/h). Una seconda infermiera controllò il suo lavoro e, non avendo a portata di mano una calcolatrice, fece i conti su un pezzo di carta commettendo esattamente lo stesso sbaglio. Dato che il suo risultato corrispondeva a un numero riportato sul pacchetto, lo prese per buono. Il paziente venne mandato a casa e, dopo sole quattro ore, si sorprese che quella pompa che avrebbe dovuto durare per quattro giorni era già vuota e suonava per segnalarlo.
Questo episodio può insegnarci molte cose riguardo alla descrizione degli ordini delle dosi e all’etichettatura dei prodotti farmaceutici. Ci può insegnare qualcosa anche sulla varietà e la complessità dei compiti assegnati alle infermiere, sul supporto disponibile e sui controlli che vengono fatti. Tuttavia, i membri di CHI+MED erano interessati soprattutto alla tecnologia che aveva reso più facile il verificarsi di questi errori di calcolo.
L’interfaccia della pompa era complicata e non intuitiva. Inoltre, la pompa non aveva nessun meccanismo di controllo integrato ed era pronta a eseguire senza batter ciglio il comando di svuotarsi a una velocità che, per questo genere di farmaco, era di gran lunga superiore al normale. Una pompa da cui dipende la vita di un paziente dovrebbe sapere quale farmaco sta somministrando e dovrebbe eseguire un controllo finale sulla velocità a cui è stata impostata (e mostrare quindi un messaggio di errore in un linguaggio comprensibile).
Ai miei occhi, poi, è ancora più interessante l’osservazione di CHI+MED secondo la quale l’infermiera usava una «calcolatrice generica che non aveva nessuna idea di quale calcolo venisse fatto». Non mi ero mai soffermato a riflettere su come tutte le calcolatrici siano strumenti generici che si limitano a sputar fuori qualunque risposta corrisponda ai tasti che avete premuto. Pensandoci su, mi rendo conto che la maggior parte delle calcolatrici non ha nessun meccanismo integrato per il controllo degli errori e non dovrebbe quindi essere usata nelle situazioni di vita o di morte. Amo la mia Casio fx-39, ma non metterei la mia vita nelle sue mani.
CHI+MED ha in seguito sviluppato un’app calcolatrice che è consapevole di quale calcolo l’utente sta eseguendo e si blocca su trenta casi comuni di errori nei calcoli medici. Tra questi ci sono alcuni errori abituali che, penso, tutte le calcolatrici dovrebbero essere in grado di rilevare, come le virgole decimali fuori posto. Se volete scrivere 23,14 ma per sbaglio digitate 2,3,14, non si sa come la vostra calcolatrice interpreterà questo dato; la mia, per esempio, assume che io abbia scritto 2,314 e va avanti come niente fosse. Una buona calcolatrice medica segnalerà invece che i numeri inseriti sono ambigui; in caso contrario, c’è il rischio che si arrivi a somministrare una dose dieci volte superiore o inferiore al dovuto.
La programmazione ha senza dubbio portato enormi benefici all’umanità, ma sta ancora muovendo i suoi primi passi. Un codice complesso reagirà sempre in modi che i suoi sviluppatori non hanno previsto. Tuttavia, c’è la speranza che degli strumenti ben programmati possano aggiungere qualche fetta di formaggio in più nei nostri sistemi moderni.