En 1977, la NASA lanzó dos sondas espaciales, Voyager 1 y 2. Los planetas del Sistema Solar se habían colocado a sí mismos en posiciones favorables poco comunes, haciendo posible encontrar órbitas razonablemente eficientes que permitiesen a las sondas visitar varios planetas. El objetivo inicial era examinar Júpiter y Saturno, pero si las sondas resistían, sus trayectorias los harían pasar por Urano y Neptuno. Voyager 1 podría haber ido hasta Plutón (en esa época considerado un planeta, e igualmente interesante, de hecho sin ningún tipo de cambio, ahora no lo es), pero una alternativa, la misteriosa luna de Saturno, Titán, tuvo prioridad. Ambas sondas fueron espectacularmente exitosas y Voyager 1 es ahora el objeto hecho por el hombre más distante de la Tierra, a más de 16 mil millones de kilómetros y todavía enviando datos.
La fuerza de la señal decae con el cuadrado de la distancia, de modo que la señal recibida en la Tierra es del orden de 10−20 veces la fuerza con la que se recibiría si la distancia fuese un kilómetro, esto es, cien trillonésimas más débil. Voyager 1 debe tener un transmisor realmente potente… No, es una sonda espacial diminuta. Está propulsada por un isótopo radiactivo, plutonio-238, pero aun así la potencia total disponible es ahora alrededor de un octavo de la de un hervidor de agua eléctrico típico. Hay dos razones de por qué podemos todavía obtener información útil de la sonda: los potentes receptores en la Tierra, y los códigos especiales usados para proteger los datos de errores provocados por factores extraños como interferencias.
Voyager 1 puede enviar datos usando dos sistemas diferentes. Uno, el canal de baja velocidad, puede enviar 40 dígitos binarios, 0s o 1s, cada segundo, pero no permite codificar para tratar con errores potenciales. El otro, el canal de alta velocidad, puede transmitir hasta 120.000 dígitos binarios cada segundo, y estos están codificados de manera que los errores pueden descubrirse y corregirse siempre que no sean demasiado frecuentes. El precio pagado por esta habilidad es que los mensajes son el doble de largos de lo que serían de otro modo, de manera que solo llevan la mitad de datos de los que podrían llevar. Como los errores pueden arruinar los datos, este es un precio que merece la pena pagar.
Los códigos de este tipo son ampliamente usados en todas las comunicaciones modernas: misiones espaciales, teléfonos fijos, Internet, CD, DVD y Blue-ray, etcétera. Sin ellos, todas las comunicaciones serían propensas a errores, lo que no sería aceptable si, por ejemplo, estás usando Internet para pagar una factura. Si tu orden de pagar 20 € se recibe como 200 €, no sería agradable. Un reproductor de CD usa unas lentes diminutas, que enfocan un rayo láser sobre unas pistas muy finitas impresas en el material del disco. La lente se mantiene a una distancia pequeñísima sobre el disco que gira. Y aun así puedes escuchar un CD mientras conduces por una carretera llena de baches, porque la señal está codificada de un modo que permite al sistema electrónico encontrar los errores y corregirlos mientras el disco está sonando. Hay otros trucos, también, pero este es el fundamental.
Nuestra era de la información se sustenta en señales digitales, cadenas largas de 0s y 1s, pulsaciones y no pulsaciones de electricidad o radio. El equipamiento que envía, recibe y almacena las señales depende de circuitos electrónicos muy pequeños y muy precisos sobre láminas de silicio, «chips». A pesar de todo lo ingenioso del diseño y fabricación del circuito, ninguno funcionaría sin códigos de detección y corrección de errores. Y fue en este contexto donde el término «información» dejó de ser una palabra informal para «conocimientos» y se convirtió en una cantidad numérica medible. Y eso proporcionó limitaciones fundamentales en la eficiencia con la que los códigos pueden modificar mensajes para protegerlos contra errores. Conocer estas limitaciones ahorró a los ingenieros mucha pérdida de tiempo, tratando de inventar códigos que serían tan eficientes que serían imposibles. Proporcionó las bases para la cultura de la información actual.
Soy lo suficientemente mayor para recordar cuando el único modo de telefonear a alguien en otro país (¡horror de horrores!) era hacer una reserva por adelantado con la compañía telefónica —en Reino Unido solo había una, Post Office Telephones—, a una hora y de una duración concreta. Por ejemplo, diez minutos a las 3:45 pm el 11 de enero. Y valía una fortuna. Hace unas pocas semanas un amigo y yo hicimos una entrevista que duró una hora para una convención de ciencia ficción en Australia desde Reino Unido, usando Skype™. Fue gratis, y enviaba vídeo además de sonido. Han cambiado muchas cosas en cincuenta años. En la actualidad, intercambiamos información online con amigos, tanto los reales como los falsos que gran número de personas coleccionan como mariposas usando las redes sociales. Ya no compramos CD de música o DVD de películas, compramos la información que contienen, transferida a través de Internet. Los libros apuntan en la misma dirección. Las compañías de investigación de mercados amasan enormes cantidades de información sobre nuestros hábitos de consumo e intentan usarla para influenciar en lo que compramos. Incluso en medicina hay un énfasis creciente en la información que está contenida en nuestro ADN. Con frecuencia la actitud parece ser que si tienes la información necesaria para hacer algo, entonces eso solo es suficiente; no necesitas realmente hacerlo, o incluso saber cómo hacerlo.
No hay duda de que la revolución de la información ha transformado nuestras vidas, y pueden darse buenos argumentos de que en términos generales, los beneficios pesan más que las desventajas, incluso aunque las últimas incluyan la pérdida de privacidad, el potencial acceso fraudulento a nuestras cuentas bancarias desde cualquier lugar del mundo a un clic de un ratón y virus informáticos que pueden inutilizar un banco o una central nuclear.
¿Qué es información? ¿Por qué tiene tanto poder? Y ¿es realmente lo que dice ser?
El concepto de información como una cantidad medible surge a partir de los laboratorios de investigación de Bell Telephone Company, el principal proveedor de servicios telefónicos en Estados Unidos desde 1877 hasta su división en 1984 en base a las leyes antimonopolio. Entre sus ingenieros estaba Claude Shannon, un primo lejano del famoso inventor Edison. La asignatura que mejor se le daba a Shannon en la escuela eran las matemáticas, y tenía una gran aptitud para construir dispositivos mecánicos. En la época que estaba trabajando para Bell Labs, era matemático y criptógrafo, además de ingeniero electrónico. Fue uno de los primeros en aplicar la lógica matemática, denominada álgebra booleana, a circuitos informáticos. Usó esta técnica para simplificar el diseño de circuitos de conmutación usados por los sistemas telefónicos, y luego lo amplió a otros problemas en el diseño de circuitos.
Durante la Segunda Guerra Mundial trabajó en códigos y comunicaciones secretas y desarrolló algunas ideas fundamentales que se presentaron en un memorándum clasificado para Bell en 1945 bajo el título de «A mathematical theory of cryptography» (Una teoría matemática de la criptografía). En 1948, publicó parte de su trabajo en una publicación abierta y el artículo de 1945, desclasificado, se publicó poco después. Con material adicional de Warren Weaver, apareció en 1949 como The Mathematical Theory of Communication (La teoría matemática de la comunicación).
Shannon quería saber cómo transmitir mensajes de modo efectivo cuando el canal de transmisión estaba sujeto a errores aleatorios, «ruido» en la jerga de ingenieros. Todas las comunicaciones prácticas sufren de ruido, ya sea de un equipo defectuoso, de rayos cósmicos o variabilidad inevitable en los componentes de los circuitos. Una solución es reducir el ruido fabricando equipamiento mejor, si es posible. Una alternativa es codificar las señales usando procedimientos matemáticos que pueden detectar errores, e incluso corregirlos.
El código de detección de errores más simple es enviar el mismo mensaje dos veces. Si recibes:
el mismo masaje dos veces
el mismo mensaje dos veces
entonces hay claramente un error en la tercera palabra; pero sin entender español, no está claro qué versión es la correcta. Una tercera repetición decidiría el asunto por mayoría y se convertiría en un código de corrección de errores. Cómo de efectivos o precisos son dichos códigos depende de la probabilidad, y naturaleza, de los errores. Si el canal de comunicación es muy ruidoso, por ejemplo, entonces las tres versiones del mensaje podrían ser tan enrevesadas que sería imposible reconstruirlo.
En la práctica la mera repetición es demasiado simple: hay modos más eficientes de codificar mensajes para descubrir y corregir errores. El punto de arranque de Shannon era establecer con exactitud el significado de eficiencia. Todos esos códigos remplazan el mensaje original por uno más largo. Los dos códigos anteriores doblan o triplican la longitud. Mensajes más largos tardan más en enviarse, cuestan más, ocupan más memoria, y obstruyen el canal de comunicación. De manera que la eficiencia, para una tasa dada de detección o corrección de error, puede cuantificarse como la proporción de la longitud del mensaje codificado con respecto al original.
El asunto principal, para Shannon, era determinar las limitaciones inherentes de dichos códigos. Supón que un ingeniero ha creado un código nuevo. ¿Había algún modo de decidir si era lo mejor que podían obtener o sería posible alguna mejora? Shannon empezó cuantificando cuánta información contiene un mensaje. Haciendo eso, hizo que «información» pasase de ser una metáfora vaga a un concepto científico.
Hay dos modos distintos de representar un número. Puede definirse por una secuencia de símbolos, por ejemplo, sus dígitos decimales, o puede corresponderse con alguna cantidad física, como la longitud de una vara o el voltaje en un cable. Las representaciones del primer tipo son digitales, las del segundo son analógicas. En la tercera década del siglo XX, los cálculos de científicos e ingenieros con frecuencia se realizaban usando ordenadores analógicos, porque en esa época estos eran más fáciles de diseñar y construir. Circuitos electrónicos simples pueden, por ejemplo, sumar o multiplicar dos voltajes. Sin embargo, las máquinas de este tipo carecen de precisión y los ordenadores digitales empezaron a aparecer. Muy rápidamente estuvo claro que la representación más conveniente de números no era la decimal, la de base 10, sino la binaria, la de base 2. En la notación decimal, hay diez símbolos para los dígitos, 0-9, y cada dígito multiplica por diez su valor por cada paso que se mueve a la izquierda. De modo que 157 representa:
1 × 102 + 5 × 101 + 7 × 100
La notación binaria emplea el mismo principio básico, pero ahora hay solo dos dígitos, 0 y 1. Un número binario como 10011101 codifica, de forma simbólica, el número:
1 × 27 + 0 × 26 + 0 × 25 + 1 × 24 + 1 × 23 + 1 × 22 + 0 × 21 + 1 × 20
De modo que cada dígito dobla su valor por cada paso que se mueva a la izquierda. En decimales, este número es igual a 157, así que hemos escrito el mismo número de dos formas diferentes, usando dos tipos de notación diferentes.
La notación binaria es ideal para los sistemas electrónicos porque es mucho más fácil de distinguir entre dos posibles valores de una corriente, o un voltaje, o un campo magnético, de lo que es distinguir entre más de dos. En términos rudimentarios, 0 puede significar «no corriente eléctrica» y 1 puede significar «algo de corriente eléctrica», 0 puede significar «no campo magnético» y 1 puede significar «algo de campo magnético», etcétera. En la práctica los ingenieros fijan un valor umbral, y entonces 0 significa «bajo el umbral» y 1 significa «sobre el umbral». Manteniendo los valores reales usados para 0 y 1 suficientemente alejados, y fijando el umbral entre ellos, hay muy poco peligro de confundir 0 con 1. De modo que los dispositivos basados en notación binaria son robustos. Esto es lo que les hace digitales.
Con los primeros ordenadores, los ingenieros tuvieron que luchar por mantener las variables del circuito dentro de límites razonables, y el binario hizo sus vidas mucho más fáciles. Los circuitos modernos en chips de silicio son lo suficientemente precisos para permitir otras opciones, como base 3, pero el diseño de ordenadores digitales ha estado basado en notación binaria durante tanto tiempo que generalmente tiene sentido seguir con el binario, incluso si hay alternativas que podrían funcionar. Los circuitos modernos son también muy pequeños y muy rápidos. Sin dicho avance tecnológico en la fabricación de circuitos, el mundo tendría unos pocos miles de ordenadores, en vez de millardos. Thomas J. Watson, fundador de IBM, una vez dijo que no creía que hubiera mercado para más de cinco ordenadores en todo el mundo. En ese momento, parecía que estaba hablando con sensatez, porque en esa época los ordenadores más potentes eran más o menos del tamaño de una casa, consumían tanta electricidad como un pueblo pequeño, y costaban decenas de millones de dólares. Solo grandes organizaciones gubernamentales, como la armada de Estados Unidos, podían permitírselos, o hacer uso suficiente de ellos. Hoy en día un teléfono móvil básico anticuado contiene más potencia informática que cualquiera de los que estaban disponibles cuando Watson hizo su comentario.
La elección de la representación binaria para ordenadores digitales, por lo tanto también para los mensajes digitales transmitidos entre ordenadores, y más tarde entre casi cualquier par de aparatos electrónicos en el planeta, llevó a la unidad básica de información: el bit. El nombre es la abreviatura de «dígito binario», y un bit de información es un 0 o un 1. Es razonable definir la información «contenida en» una secuencia de dígitos binarios como el número total de dígitos en la secuencia. De modo que la secuencia de 8 dígitos 10011101 contiene 8 bits de información.
Shannon se dio cuenta de que el conteo sencillo de bits tiene sentido como una medida de información solo si ceros y unos son como caras y cruces con una moneda no trucada, esto es, hay la misma probabilidad de que ocurran. Supón que sabemos que en algunas circunstancias específicas el 0 se da nueve veces sobre diez, y el 1 solo una vez. Cuando leemos la cadena de dígitos, esperamos que la mayoría de dígitos sea 0. Si esa expectativa se confirma, no hemos recibido mucha información, porque esto es lo que esperamos de todos modos. Sin embargo, si vemos 1, eso expresa mucha más información, porque no esperábamos eso para nada.
Podemos sacar ventaja de esto codificando la misma información más eficientemente. Si 0 se da con probabilidad 9/10 y 1 con probabilidad 1/10, podemos definir un nuevo código como este:
000 → 00 (lo usamos siempre que sea posible)
00 → 01 (si no quedan 000)
0 → 10 (si no quedan 00)
1 → 11 (siempre)
Lo que quiero decir aquí es que en un mensaje como:
00000000100010000010000001000000000
primero se parte de izquierda a derecha en bloques que se leen como 000, 00, 0 o 1. Con cadenas consecutivas de ceros, usamos 000 siempre que podamos. Si no, lo que está a la izquierda es o 00 o 0, seguido por un 1. Así que aquí el mensaje se divide como:
000-000-00-1-000-1-000-00-1-000-000-1-000-000-000
Y la versión codificada es:
00-00-01-11-00-11-00-01-11-00-00-11-11-00-00-00
El mensaje original tiene 35 dígitos, pero la versión codificada solo 32. La cantidad de información parece haber decrecido.
A veces la versión codificada podría ser más larga, por ejemplo, 111 se convierte en 111111. Pero eso es raro porque 1 se da solo una vez cada diez de media. Habrá bastantes 000, que se reducen a 00. Cualquier resto 00 cambia a 01, la misma longitud, un resto 0 incrementa la longitud en uno al cambiarse a 00. El resultado es que a la larga, para mensajes escogidos aleatoriamente con las probabilidades dadas para 0 y 1, la versión codificada es más corta.
Mi código aquí es muy sencillo, y una elección más inteligente puede acortar el mensaje todavía más. Una de las muchas cuestiones que Shannon quería responder era: ¿cómo de eficiente pueden ser los códigos de este tipo? Si conoces la lista de símbolos que están siendo usados para crear un mensaje, y también sabes cómo de probable es cada símbolo, ¿cuánto puedes acortar el mensaje usando un código apropiado? Su solución era una ecuación, definiendo la cantidad de información en términos de estas probabilidades.
Supón, para simplificar, que el mensaje usa solo dos símbolos 0 y 1, pero ahora estos son como lanzamientos de una moneda trucada, de modo que 0 tiene probabilidad p de ocurrir, y 1 tiene probabilidad q = 1 − p. El análisis de Shannon le llevó a una fórmula para el contenido de la información: debería definirse como:
H = −p log2 p − q log2 q
donde log2 es el logaritmo de base 2.
A primera vista esto no parece demasiado intuitivo. Explicaré cómo Shannon llegó a ello en su momento, pero el tema principal que hay que apreciar en esta etapa es cómo H se comporta a medida que p varía de 0 a 1, tal como se muestra en la figura 56. El valor de H aumenta suavemente de 0 a 1 a medida que p crece de 0 a 1/2, y luego cae simétricamente de nuevo a 0 a medida que p va de 1/2 a 1.

FIGURA 56. Cómo la información H de Shannon depende de p. H avanza verticalmente y p horizontalmente.
Shannon señaló varias «propiedades interesantes» de H, así definidas:
•Si p = 0, en cuyo caso solo se dará el símbolo 1, la información H es cero. Esto es, si estamos seguros de qué símbolo se nos va a transmitir, recibirlo no expresa ninguna información en absoluto.
•Lo mismo aplica cuando p = 1. Solo se dará el símbolo 0 y, de nuevo, no recibiremos ninguna información.
•La cantidad de información es la mayor cuando p = q = 1/2, y corresponde al lanzamiento de una moneda no trucada. En este caso:
H = −1/2 log2 1/2 − 1/2 log2 1/2 = − log2 1/2 = 1
Esto es, un lanzamiento de una moneda no trucada transmite un bit de información, como estábamos originalmente asumiendo antes de empezar a preocuparnos por comprimir los mensajes codificados y las monedas trucadas.
•En todos los otros casos, recibir un símbolo transmite menos información que un bit.
•Cuanto más trucada está la moneda, menos información transmite el resultado de un lanzamiento.
•La fórmula trata los dos símbolos exactamente del mismo modo. Si intercambiamos p y q, entonces H se queda igual.
Todas estas propiedades corresponden a nuestro sentido intuitivo de cuánta información recibimos cuando se dice el resultado de un lanzamiento de moneda. Eso hace de la fórmula una definición razonable que funciona. Shannon proporcionó luego una fundación sólida para su definición haciendo una lista de varios principios básicos que cualquier medida de contenido de información debería obedecer, obteniendo una fórmula única que los satisfacía. Su sistema era muy general: el mensaje podía escoger entre un número diferente de símbolos, que se daban con probabilidades p1, p2,… pn, donde n es el número de símbolos. La información H transmitida por la elección de uno de estos símbolos debería satisfacer:
•H es una función continua de p1, p2,… pn. Esto es, cambios pequeños en las probabilidades deberían llevar a pequeños cambios en la cantidad de información.
•Si todas las probabilidades son iguales, lo que implica que son todas 1/n, entonces H debería aumentar si n se hace mayor. Esto es, si estás escogiendo entre 3 símbolos, todos igual de probables, entonces la información que recibes debería ser más que si la elección fuese entre dos símbolos igual de probables; una elección entre 4 símbolos debería transmitir más información que una elección entre 3 símbolos, y así sucesivamente.
•Si hay un modo natural de desglosar una elección en dos elecciones sucesivas, entonces el H original debería ser una combinación simple de los nuevos H.
Esta condición final se entiende mucho más fácilmente usando un ejemplo, y he puesto uno en las Notas[53]. Shannon probó que la única función H que obedece sus tres principios es:
H (p1, p2, …, pn) = −p1 log2 p1 − p2 log2 p2 − … − pn log2 pn
O una constante múltiplo de esta expresión, que básicamente solo cambia la unidad de información, como cambiar de pies a metros.
Hay una buena razón para tomar la constante como 1, y la ilustraré con un caso sencillo. Piensa en las cuatro cadenas binarias 00, 01, 10, 11 como símbolos por sí mismos. Si 0 y 1 son igualmente probables, cada cadena tiene la misma probabilidad, concretamente 1/4. La cantidad de información transmitida por una elección de una cadena es por lo tanto:
H(1/4, 1/4, 1/4, 1/4) = −1/4 log2 1/4 − 1/4 log2 1/4 − 1/4 log2 1/4 − 1/4 log2 1/4 = − log2 1/4 = 2
Esto es, 2 bits. Que es un número sensato para la información en una cadena binaria de longitud 2 cuando las elecciones 0 y 1 son igual de probables. Del mismo modo, si los símbolos son todos cadenas binarias de longitud n, y fijamos la constante en 1, entonces la información contenida es n bits. Observa que cuando n = 2, obtenemos la fórmula representada en la figura 56. La prueba del teorema de Shannon es demasiado complicada para ponerla aquí, pero muestra que si aceptas las tres condiciones de Shannon, entonces hay un único modo natural de cuantificar la información.[54] La ecuación en sí misma es meramente una definición: lo que cuenta es cómo responde en la práctica.
Shannon usó su ecuación para probar que hay un límite fundamental en cuánta información puede transmitir un canal de información. Supongamos que estás transmitiendo una señal digital a lo largo de una línea de teléfono, cuya capacidad para llevar un mensaje es como mucho C bits por segundo. Esta capacidad está determinada por el número de dígitos binarios que la línea de teléfonos puede transmitir, y no está relacionada con las probabilidades de varias señales. Supón que el mensaje está siendo generado a partir de símbolos con el contenido de información H, también medido en bits por segundo. El teorema de Shannon responde a la pregunta: si el canal es ruidoso, ¿puede la señal codificarse de modo que la proporción de errores sea tan pequeña como queramos? La respuesta es que esto es siempre posible, no importa cuál sea el nivel de ruido, si H es menor o igual que C. Esto no es posible si H es mayor que C. De hecho, la proporción de errores no puede reducirse por debajo de la diferencia H − C, no importa el código que se emplee, pero existen códigos que se acercan tanto como quieras a esa tasa de error.
La prueba de Shannon de su teorema demuestra que los códigos del tipo necesario existen, en cada uno de sus dos casos, pero la prueba no nos dice cuáles son esos códigos. Una rama entera de la ciencia de la información, una mezcla de matemáticas, computación e ingeniería electrónica, está dedicada a encontrar códigos eficientes para propósitos específicos. Se llama la teoría de códigos. Los métodos para dar con estos códigos son muy diversos, aprovechándose de muchas áreas de las matemáticas. Son estos métodos los que se incorporan en nuestros aparatos electrónicos, ya sea un smartphone o el transmisor de la Voyager 1. La gente lleva de un lado a otro cantidades significativas de sofisticada álgebra abstracta en sus bolsillos, en la forma de software que implementa códigos de detección de errores para teléfonos móviles.
Intentaré transmitir el sabor de la teoría de códigos sin enredarme mucho en las complejidades. Uno de los conceptos más influenciables en la teoría relaciona códigos con geometría multidimensional. Fue publicado por Richard Hamming en 1950 en un famoso artículo: «Error detecting and error correcting codes» (Códigos de detección y corrección de errores). En su forma más simple, proporciona una comparación entre cadenas de dígitos binarios. Considera dos de dichas cadenas, por ejemplo, 10011101 y 10110101. Compara los bits correspondientes y cuenta cuántas veces son diferentes, tal que así:
10011101
10110101
donde he marcado con negrita las diferencias. Aquí hay dos localizaciones en las que la cadena de bits difiere. Llamamos a este número la distancia de Hamming entre dos cadenas. Puede pensarse como el número más pequeño de errores de un bit que puede convertir una cadena en otra. De modo que está muy relacionado con el probable efecto de los errores, si estos se dan en una tasa media conocida. Lo que sugiere que podría proporcionar algo de comprensión sobre cómo detectar dichos errores y, quizá, cómo corregirlos.
La geometría multidimensional entra en juego porque las cadenas de una longitud fija pueden asociarse con los vértices de un «hipercubo» multidimensional. Riemann nos enseñó cómo pensar en dichos espacios pensando en una lista de números. Por ejemplo, un espacio de cuatro dimensiones consiste en todas las listas de cuatro números posibles: (x1, x2, x3, x4). Cada lista se considera que representa un punto en el espacio, y todas las listas posibles pueden, en principio, darse. Cada una de las x son las coordenadas del punto. Si el espacio tiene 157 dimensiones, tiene que usar listas de 157 números: (x1, x2, …, x157). Es con frecuencia útil especificar cuán separadas están estas listas. En la geometría «plana» de Euclides, esto se hacía usando una generalización simple del teorema de Pitágoras. Supón que tenemos un segundo punto (y1, y2, …, y157) en nuestro espacio 157-dimensional. Entonces la distancia entre los dos puntos es la raíz cuadrada de la suma de los cuadrados de las diferencias entre las coordenadas correspondientes. Esto es:

Si el espacio es curvado, se puede usar en su lugar la idea de Riemann de una métrica.
La idea de Hamming es hacer algo muy similar, pero los valores de las coordenadas se restringen solo a 0 y 1. Entonces (x1 − y1)2 es 0 si x1 e y1 son lo mismo, y 1 si no lo son, y lo mismo aplica para (x2 − y2)2, etcétera. También omitió la raíz cuadrada, la cual cambia la respuesta, pero en compensación el resultado es siempre un número natural, igual a la distancia de Hamming. Esta noción tiene todas las propiedades que hacen la «distancia» útil, como ser cero solo cuando las dos cadenas son idénticas, y asegurar que la longitud de cualquier lado de un «triángulo» (un conjunto de tres cadenas) es menor o igual que la suma de las longitudes de los otros dos lados.
Podemos dibujar imágenes de todas las cadenas de bits de longitudes 2, 3 y 4 (y con más esfuerzo y menos claridad, 5, 6 y posiblemente incluso 10, aunque nadie la encontraría útil). Los diagramas resultantes se muestran en la figura 57.
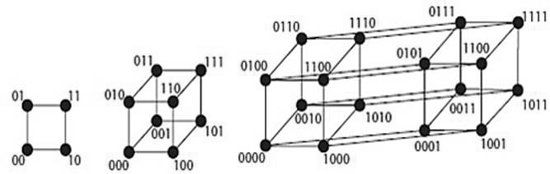
FIGURA 57. Los espacios de todas las cadenas de bits de longitudes 2, 3 y 4.
Los dos primeros son reconocibles como un cuadrado y un cubo (proyectado en un plano porque tiene que imprimirse en una hoja de papel). El tercero es un hipercubo, el análogo en 4 dimensiones y, de nuevo, tiene que proyectarse en un plano. Las líneas rectas uniendo los puntos tienen longitud de Hamming 1, las dos cadenas en cada extremo difieren en precisamente una localización, una coordenada. La distancia de Hamming entre dos cadenas cualesquiera es el número de dichas líneas en la ruta más corta que las conecta.
Supón que estamos pensando en cadenas de 3 bits, presentes en las esquinas de un cubo. Selecciona una de las cadenas, por ejemplo 101. Supón que la tasa de errores es como mucho un bit cada tres. Entonces esta cadena podría o bien transmitirse sin cambios, o bien podría acabar como cualquiera de estas: 001, 111 o 100. Cada una de estas difiere de la cadena original en tan solo una localización, de modo que su distancia de Hamming de la cadena original es 1. La esfera consiste en solo tres puntos, y si estuviésemos trabajando en un espacio de 157 dimensiones con un radio de 5, por ejemplo, ni siquiera parecería demasiado esférica. Pero juega un rol similar a una esfera ordinaria: tiene una forma bastante compacta, y contiene exactamente los puntos cuya distancia desde el centro es menor o igual que el radio.
Supón que usamos las esferas para construir un código, de modo que cada esfera se corresponde con un símbolo nuevo, y ese símbolo está codificado con las coordenadas del centro de la esfera. Supón además que estas esferas no se superponen. Por ejemplo, podría introducir un símbolo a para la esfera con centro en 1010. Esta esfera contiene cuatro cadenas: 101, 001, 111 y 100. Si recibo cualquiera de estas cuatro cadenas, sé que el símbolo era originalmente a. Al menos, eso es cierto siempre que mis otros símbolos se correspondan de un modo similar a las esferas que no tienen ningún punto en común con esta.
Ahora la geometría comienza a hacerse útil. En el cubo hay ocho puntos (cadenas) y cada esfera contiene cuatro de ellos. Si intento encajar las esferas en el cubo, sin que se superpongan, el mejor resultado que puedo lograr es con dos de ellas, porque 8/4 = 2. Realmente puedo encontrar otra, concretamente la esfera centrada en 010. Esta contiene 010, 110, 000, 011, ninguno de los cuales está en la primera esfera. De manera que se puede introducir un segundo símbolo b asociado con esta esfera. Mi código de corrección de errores escrito con los símbolos a y b ahora remplaza todo a con 101, y todo b con 010. Si recibo, digamos:
101-010-100-101-000
entonces puedo decodificar el mensaje original como:
a-b-a-a-b
a pesar de los errores en la tercera y la quinta cadena. Acabo de ver cuáles de mis dos esferas pertenecen las cadenas erróneas.
Todo está muy bien, pero esto multiplica la longitud del mensaje por 3, y ya sabemos un modo más fácil de lograr el mismo resultado: repetir el mensaje tres veces. Pero la misma idea adquiere un nuevo significado si trabajamos en espacios de dimensiones mayores. Con cadenas de longitud 4, el hipercubo, hay 16 cadenas, y cada esfera contiene 5 puntos. De modo que podría ser posible encajar tres esferas sin que se solapen. Si lo intentas, resulta que no es posible realmente, dos encajan pero el hueco que queda tiene la forma equivocada. Pero cada vez más números funcionan a nuestro favor. El espacio de cadenas de longitud 5 contiene 32 cadenas, y cada esfera usa solo 6 de ellas, posiblemente haya hueco para 5, y si no, una posibilidad mejor de encajar 4. Longitud 6 nos da 64 puntos y esferas que usan 7, de modo que pueden encajar hasta 9 esferas.
A partir de este punto son necesarios muchos detalles complicados para averiguar solo qué es lo que es posible, y ayuda a desarrollar métodos más sofisticados. Pero lo que estamos observando es análogo, en el espacio de cadenas, a las maneras más eficientes de agrupar esferas unas con otras. Y esto es una vieja área de las matemáticas, sobre la que se conoce bastante. Algunas de esas técnicas pueden transferirse de la geometría euclídea a las distancias de Hammings, y cuando eso no funciona, podemos inventar nuevos métodos más apropiados para la geometría de cadenas. Como ejemplo, Hamming inventó un código nuevo, más eficiente que cualquiera conocido en la época, el cual codifica cadenas de 4 bits, convirtiéndolas en cadenas de 7 bits. Puede detectarse y corregirse cualquier error de un único bit. Modificado a un código de 8 bits, puede detectarse, pero no corregirse, cualquier error de 2 bits.
Este código se llama el código de Hamming. No lo describiré, pero hagamos las operaciones para ver si podría ser posible. Hay 16 cadenas de longitud 4, y 128 de longitud 7. Las esferas de radio 1 en el hipercupo de 7 dimensiones contienen 8 puntos. Y 128/8 = 16. De modo que con suficiente ingenio, podría ser posible meter las 16 esferas necesarias en el hipercubo de 7 dimensiones. Tendrían que encajar exactamente, porque no queda hueco libre. Al parecer, existe dicha colocación, y Hamming la encontró. Sin la geometría multidimensional como ayuda, sería difícil adivinar que existe, por no hablar de encontrarla. Posible, pero duro. Incluso con la geometría no es obvio.
El concepto de Shannon de información proporciona un límite en cómo de eficientes pueden ser los códigos. La teoría de códigos hace la otra mitad del trabajo: encontrar códigos que sean lo más eficientes posible. Las herramientas más importante aquí vienen del álgebra abstracta. Este es el estudio de las estructuras matemáticas que comparten las características aritméticas básicas de los números enteros o reales, pero difieren de ellos de maneras significativas. En aritmética, podemos sumar números, restarlos y multiplicarlos, para obtener números del mismo tipo. Para los números reales, podemos también dividir por cualquier cosa diferente de cero para obtener un número real. Esto no es posible para los enteros, porque por ejemplo 1/2 no es un entero. Sin embargo, las fracciones son posibles si pasamos al sistema más grande de los números racionales. En los sistemas numéricos habituales, se soportan varias leyes algebraicas, por ejemplo, la propiedad conmutativa de la adición, que afirma que 2 + 3 = 3 + 2 y lo mismo aplica para cualquier par de números.
Los sistemas comunes comparten estas propiedades algebraicas con los menos comunes. El ejemplo más simple usa solo dos números, 0 y 1. Las sumas y los productos están definidos solo como para los enteros, con una excepción: insistimos en que 1 + 1 = 0, no 2. A pesar de esta modificación, todas las leyes habituales del álgebra sobreviven. El sistema tiene solo dos «elementos», dos objetos como los números. Hay exactamente uno de dichos sistemas siempre que el número de elementos sea una potencia de cualquier número primo: 2, 3, 4, 5, 7, 8, 9, 11, 13, 16, etcétera. Dichos sistemas se llaman cuerpos finitos o campos de Galois, por el matemático francés Évariste Galois, que los clasificó alrededor de 1830. Porque tienen un número finito de elementos, son adecuados para las comunicaciones digitales, y las potencias de 2 son especialmente convenientes debido a la notación binaria.
Los cuerpos finitos llevan a sistemas codificados llamados códigos de Reed-Solomon, por Irving Reed y Gustave Solomon, quienes los inventaron en 1960. Se usan en los aparatos electrónicos de consumo, especialmente en CDs y DVDs. Son códigos de corrección de errores basados en propiedades algebraicas de polinomios, cuyos coeficientes se toman de los cuerpos finitos. La señal una vez codificada, audio o vídeo, se usa para construir un polinomio. Si el polinomio tienen grado n, esto es, si la mayor potencia que aparece es xn, entonces el polinomio puede reconstruirse a partir de sus valores en n puntos cualquiera. Si especificamos los valores en más de n puntos, podemos perder o modificar algunos de los valores sin perder la pista de qué polinomio es. Si el número de errores no es demasiado grande, es todavía posible averiguar qué polinomio es, y decodificarlo para obtener los datos originales.
En la práctica la señal se representa como una serie de bloques de dígitos binarios. Una elección popular usa 255 bytes (una cadena de 8 bits) por bloque. De estos, 223 bytes codifican la señal, mientras los restantes 32 bytes son los «símbolos de paridad», que nos dicen si varias combinaciones de dígitos en los datos incorruptos son pares o impares. Este código de Reed-Solomon en concreto puede corregir hasta 16 errores por bloque, una tasa de error menor del 1%.
Siempre que conduces a lo largo de una carretera llena de baches con un CD en el reproductor del coche, estás usando álgebra abstracta, en la forma del código de Reed-Solomon, para asegurarte de que la música se escucha limpia y clara, en lugar de entrecortada y chirriante, quizá saltándose algunas partes.
La teoría de la información se usa ampliamente en criptografía y criptoanálisis, códigos secretos y métodos para descifrarlos. El propio Shannon la usó para estimar la cantidad de mensajes codificados que deben ser interceptados para tener alguna posibilidad de descifrar el código. Mantener la información secreta resulta ser más difícil de lo que se esperaba, y la teoría de la información arroja luz sobre este problema, tanto desde el punto de vista de la gente que quiere mantenerla en secreto como del de aquellos que quieren averiguar qué es. El asunto es importante no solo en el ejército, sino para cualquiera que use Internet para comprar o contrate la banca telefónica.
La teoría de la información ahora juega un rol importante en biología, particularmente en el análisis de la secuencia del ADN. La molécula del ADN es una doble hélice, formada por dos hebras que se enroscan una alrededor de la otra. Cada hebra es una secuencia de bases, moléculas especiales que se dan en cuatro tipos: adenina, guanina, timina y citosina. De modo que el ADN es como un mensaje codificado escrito usando los cuatro símbolos posibles: A, G, T y C. El genoma humano, por ejemplo, tiene una longitud de 3.000 millones de bases. Los biólogos pueden ahora encontrar las secuencias del ADN de innumerables organismos a una velocidad cada vez más rápida, llevando a una nueva área de la informática: la bioinformática. Esta se centra en métodos para manejar los datos biológicos de manera eficiente y efectiva, y una de sus herramientas básicas es la teoría de la información.
Un asunto más complicado es la calidad de la información, más que la cantidad. Los mensajes «dos más dos son cuatro» y «dos más dos son cinco» contienen exactamente la misma cantidad de información, pero uno es cierto y el otro es falso. Los cantos de alabanza por la era de la información ignoran la verdad incómoda de que mucha de la información merodeando en Internet es desinformación. Hay websites que las llevan criminales que quieren robar tu dinero, o negacionistas que quieren remplazar la ciencia sólida por lo que sea que tienen metido entre ceja y ceja.
El concepto vital aquí no es la información como tal, sino el significado. Tres mil millones de bases de ADN de la información del ADN humano carecen, literalmente, de significado a menos que puedas averiguar cómo afectan a nuestro cuerpo y comportamiento. En el décimo aniversario de la finalización del Proyecto Genoma Humano, varias publicaciones científicas destacadas examinaron los progresos médicos resultantes, hasta el momento, de la enumeración de las bases del ADN humano. El tono general fue silenciado: se habían encontrado unas pocas nuevas curas para enfermedades, pero no en la cantidad originalmente predicha. Extraer significado de la información del ADN ha resultado ser más duro de lo que los biólogos habían esperado. El Proyecto Genoma Humano era un primer paso necesario, pero, más que resolverlos, solo ha revelado lo difíciles que son dichos problemas.
La noción de la información ha escapado de la ingeniería electrónica y ha invadido muchas otras áreas de la ciencia, ambas tanto como una metáfora y como un concepto técnico. La fórmula para la información se parece mucho a la de la entropía en la aproximación de Boltzmann a la termodinámica, las principales diferencias son los logaritmos de base 2 en lugar de los logaritmos neperianos, y un cambio en el signo. Se puede formalizar esta similitud, y la entropía se puede interpretar como «información perdida». De modo que la entropía de un gas aumenta porque perdemos la noción de dónde están las moléculas exactamente, y con qué rapidez se mueven. La relación entre la entropía y la información tiene que fijarse con mucho cuidado; aunque las fórmulas son muy parecidas, el contexto en el que se aplican es diferente. La entropía de la termodinámica es una propiedad a gran escala del estado de un gas, pero la información es una propiedad de una fuente que produce señales, no de una señal como tal. En 1957, el físico americano Edwin Jaynes, un experto en mecánica estadística, resumió la relación: la entropía de la termodinámica puede verse como una aplicación de la información de Shannon, pero la entropía en sí misma no debería identificarse con información perdida sin especificar el contexto correcto. Si esta distinción se tiene en mente, hay varios contextos válidos en los que la entropía puede verse como una pérdida de información. Justo como el incremento de entropía pone límites en la eficiencia de los motores a vapor, la interpretación entrópica de la información pone límites a la eficiencia de los cómputos. Por ejemplo, se necesitan al menos 5,8 × 10−23 julios de energía para convertir un bit de 0 a 1 o viceversa a la temperatura del helio líquido, cualquiera que sea el método que se utilice.
Los problemas surgen cuando las palabras «información» y «entropía» se usan en un sentido más metafórico. Los biólogos con frecuencia dicen que el ADN determina «la información» necesaria para formar un organismo. Hay un sentido en el que esto es casi correcto: elimina el «la». Sin embargo, la interpretación metafórica de información sugiere que una vez que conoces el ADN, entonces lo conoces todo sobre ese organismo. Después de todo, tienes la información, ¿no? Y durante un tiempo muchos biólogos pensaron que esta afirmación era cercana a la verdad. Sin embargo, ahora sabemos que es demasiado optimista. Incluso aunque la información en el ADN realmente especificase al organismo de manera única, todavía necesitaría averiguar cómo crece y qué hace el ADN. Pero se necesita mucho más que una lista de código de ADN para crear un organismo, los conocidos como factores epigenéticos deben, también, tenerse en cuenta. Estos incluyen «cambios» químicos que hacen activo o inactivo un segmento de código de ADN, pero también factores totalmente diferentes que se transmiten de padres a hijos. Para los seres humanos, estos factores incluyen la cultura en la que crecen. De modo que no resulta ser tan superficial el uso de términos técnicos como «información».