FÓSFORO
Cuando, en 1944, el ácido nucleico entró en su apogeo, hacía aproximadamente tres cuartos de siglo que se había descubierto. Durante este tiempo, sólo unos cuantos hombres lo habían estudiado. Fue la cenicienta de los compuestos hasta que, de la noche a la mañana, se calzó el zapatito de cristal.
De todos modos, los pioneros que habían trabajado con él durante sus días de anonimato, habían conseguido deducir los principios básicos de su estructura. Por ejemplo, poco después de ser descubierto, se averiguó que contenía fósforo.
Esto era extraño. Desde luego, se sabía que algunas proteínas contenían fósforo, pero en pequeña cantidad. La caseína, la principal proteína de la leche, contiene un 1 por ciento de fósforo. La lecitina, una sustancia grasa que se encuentra en la yema de huevo, contiene un 3 por ciento de fósforo. Pero el ácido nucleico es más rico en este elemento que cualquier otra de las sustancias importantes del cuerpo, ya que contiene un 9 por ciento de fósforo.
Por lo tanto, ha llegado el momento de examinar atentamente el fósforo. Como se indica en el capítulo III, su símbolo es P. Por sus propiedades químicas, el fósforo se parece un poco al nitrógeno. Al igual que éste, el fósforo puede combinarse con tres átomos diferentes. En ocasiones, también puede agregarse un cuarto átomo (generalmente, oxígeno) mediante un tipo especial de enlace que se representa con una pequeña flecha en lugar del guión[15].
Por ejemplo, la figura 35 indica la fórmula estructural del ácido fosfórico, importante producto químico industrial. Su fórmula empírica es, como puede verse: H3PO4 Obsérvese también que, mientras un átomo de oxígeno puede formar dos enlaces del tipo corriente de «guión», forma una solo del tipo de «flecha».
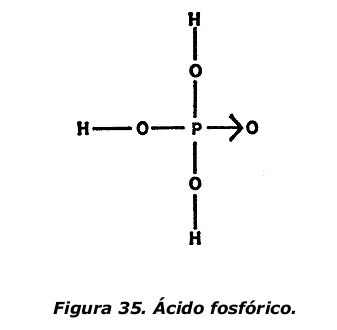
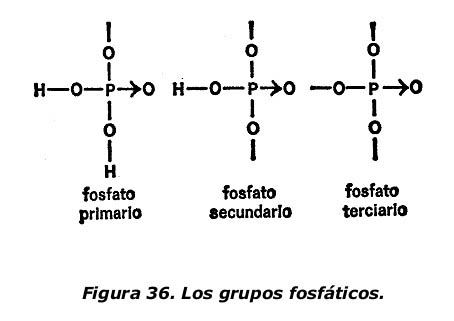
Los enlaces existentes entre el átomo de fósforo y los átomos de oxígeno del ácido fosfórico son fuertes. No obstante, los átomos de hidrógeno pueden extraerse del compuesto con bastante facilidad. Cuando se quita uno, queda una abertura que sirve para unir lo que resta del ácido fosfórico a otros átomos o grupos de átomos. Si se extraen dos átomos de hidrógeno quedan dos aberturas y, si se extraen todos, tres. El ácido fosfórico menos uno o más de sus hidrógenos es un grupo fos/ático: el fosfato será primario, secundario o terciario según se haya extraído uno, dos o tres átomos de hidrógeno, dejando una, dos o tres aberturas para otras combinaciones, como se indica en la figura 36.
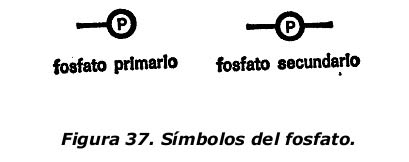
En los tejidos vivos, el átomo de fosfato siempre está integrado en un fosfato primario o secundario. Para simplificar, se puede adoptar una forma convencional para indicar estos dos grupos, sin reparar en su configuración atómica interna. Por ejemplo, se puede indicar, no ya el fósforo sino el grupo fosfático por la P rodeada de un círculo. Para distinguir entre los fosfatos primario y secundario, se señalarán uno o dos enlaces en el símbolo, como se indica en la figura 37.
A modo de ejemplo de la forma en la que un grupo de fosfatos puede darse entre los compuestos ya mencionado, tomemos el aminoácido serina. Un grupo fosfático puede agregarse a la serina en el lugar de la cadena secundaria correspondiente al oxígeno. Así se forma la fosfoserina, como indica la figura 38.

En las proteínas puede darse la fosfoserina en lugar de la serina y cuando esto ocurre el resultado es una proteína que contiene fósforo, lo que se llama fosfoproteína. Ejemplo de ello es la caseína, que menciono al principio de este capítulo.
Así pues, podemos considerar los grupos fosfáticos como un componente del ácido nucleico, el componente que le da sus propiedades ácidas. Desde luego, tiene también otros componentes.
LAS DOS VARIEDADES
Pronto se observaron indicaciones de que el ácido nucleico contiene en su estructura grupos de azúcar, pero durante décadas la naturaleza del azúcar fue una incógnita.
El azúcar simple más corriente que se da en la Naturaleza es la glucosa, unidad a base de la cual se fabrican el almidón y la celulosa. La molécula de glucosa es una cadena de seis átomos de carbono. A cinco de ellos está unido un grupo hidroxilo, mientras que el sexto átomo de carbono forma parte de un grupo carbonilo. (La característica de la estructura de la molécula de azúcar es precisamente la posesión de un grupo carbonilo y de numerosos grupos hidroxilos).
Otros dos azúcares corrientes son la fructosa y la galactosa.
Al igual que la glucosa, cada uno de ellos tiene seis átomos de carbono, uno de los cuales forma parte de un grupo carbonilo, mientras que los otros están unidos a grupos hidroxilos. No obstante la orientación relativa de los grupos hidroxilos en el espacio es distinta en cada caso. (Esta diferencia de orientación basta para producir distintos compuestos, de propiedades diferentes).
Dos azúcares simples pueden combinarse entre sí (al igual que los aminoácidos) eliminando el agua. La glucosa y la fructosa combinadas forman una molécula de sacarosa, el azúcar de mesa «corriente», que utilizamos para endulzar el café. El azúcar de caña, el de remolacha y el de arce son todo sacarosa. La glucosa también puede combinarse con la galactosa para formar lactosa, un azúcar casi insípido que sólo se encuentra en la leche. Por último, ciertas moléculas de glucosa pueden combinarse para formar moléculas de almidón o celulosa.
Existen otros muchos azúcares y combinaciones de azúcares. También hay algunas moléculas de azúcar ligeramente modificadas: son aquéllas a las que se han agregado grupos de nitrógeno, azufre o fósforo. Algunos de estos compuestos no se dan en la Naturaleza, sino que se han obtenido por síntesis en el laboratorio.
Todos estos compuestos —simples, combinados o modificados, naturales o sintéticos— llevan el nombre de hidratos de carbono o carbohidratos; como queda dicho en el capítulo II, componen uno de los tres grandes grupos de materia orgánica de los tejidos.

Pero ¿qué carbohidrato es el del ácido nucleico? La respuesta a esta pregunta no se halló hasta 1910, en que el bioquímico norteamericano de origen ruso Phoebus A. T. Levene identificó la ribosa, uno de los componentes del ácido nucleico. Con anterioridad, se ignoraba que la ribosa se diera en la Naturaleza. Fue obtenida por síntesis en 1911 por Emil Fischer (el hombre que descubrió la estructura de los péptidos), pero se consideraba puramente como una curiosidad científica, carente de valor práctico. Su mismo nombre fue inventado por Fischer sin pretender otorgarle un significado especial. Sin embargo, debía ser considerada al fin como uno de los dos carbohidratos más importantes para la vida. (En la Ciencia, al igual que en la vida diaria, también hay patitos feos qué se convierten en cisnes).
La ribosa se diferencia del la glucosa, la fructosa y la galactosa en que tiene cinco carbonos en lugar de seis. Esta cadena de cinco carbonos tiende a formar un anillo con un átomo de oxígeno de uno de los grupos hidroxilos. El resultado es un anillo de cuatro carbonos y un oxígeno que viene a ser como un anillo de furano sin los enlaces dobles. Ello se indica en la figura 39, que muestra la ribosa al completo y en zigzag.
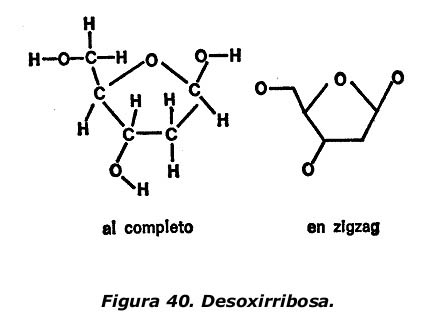
Más adelante, Levene descubrió que no todas las moléculas de ácido nucleico contienen ribosa. Algunas muestras contienen un azúcar afín que se diferencia sólo por la carencia de uno de los átomos de oxígeno de la ribosa. Su nombre, por lo tanto, es desoxirribosa y en la figura 40 se indica su estructura. La desoxirribosa, al igual que la ribosa, había sido sintetizada por Fischer años antes de que se descubriera su existencia en la Naturaleza.
En función de estos dos azúcares, el ácido nucleico se dividió en dos tipos: ácido ribonucleico, que contiene ribosa, y ácido desoxirribonucleico, que contiene desoxirribosa. Dado que estos nombres han venido usándose con creciente frecuencia y dado que los bioquímicos son tan alérgicos a los polisílabos como el que más, no tardó en implantarse la costumbre de utilizar iniciales para referirse a estas sustancias. El ácido ribonucleico es ARN y el ácido desoxirribonucleico, ADN. Casi nadie los nombra ya de otro modo.
En los ácidos nucleicos no se habían encontrado más azúcares que la ribosa y la desoxirribosa y hacia 1950 los bioquímicos asumían, con más o menos firmeza, que no se encontrarían ya y que la ribosa y la desoxirribosa eran los únicos azúcares del ácido nucleico. Además, no se ha encontrado ningún ácido nucleico que contenga ribosa y desoxirribosa, sino sólo una u otra.
Uno y otro tipo de ácido nucleico se dan en distintos lugares de la célula. El ADN se presenta sólo en el núcleo y, concretamente, en los cromosomas. En el interior del núcleo puede encontrarse también algo de ARN; pero éste acostumbra a estar en su mayor parte fuera, en el citoplasma. Por lo que ha podido averiguarse hasta ahora, todas las células completas contienen tanto ADN como ARN.
Por lo que respecta a los virus, los más complicados contienen, al igual que las células, ADN y ARN. No obstante, muchos contienen únicamente ADN. Los más simples, como el del mosaico del tabaco, contienen sólo ARN.
PURINAS Y PIRIMIDINAS
Pudo averiguarse que los ácidos nucleicos contienen, además de grupos fosfáticos y azúcares, combinaciones de átomos construidas en tomo a anillos con parte de nitrógeno. Ello fue descubierto hacia 1880 y con posterioridad por Kossel (el hombre que más adelante trabajaría con protaminas). Todos los compuestos con parte de nitrógeno que fueron aislados resultaron estar construidos alrededor de uno o dos sistemas de anillos, el de purina y el de pirimidina, los cuales quedan indicados en la figura 15. Por lo tanto, los compuestos con parte de nitrógeno aislados del ácido nucleico se agrupan en purinas y pirimidinas[16].
Dos purinas y tres pirimidinas se han aislado de los ácidos nucleicos en cantidades considerables. Las dos purinas son: adenina y guanina y las tres pirimidinas: citosina, timina y uracilo. Las cinco se presentan en la figura 41, en forma completa y en zigzag.
De las cinco, le adenina, la guanina y la citosina se dan tanto en el ADN como en el ARN. La timina se encuentra sólo en el ADN y el uracilo, sólo en el ARN. La timina y el uracilo no son muy diferentes. En realidad, la única diferencia consiste en que la timina posee un grupo metilo del que carece el uracilo. En la fórmula de zigzag, la molécula de timina muestra un pequeño guión que no se observa en el uracilo, lo cual sitúa la diferencia en su justa perspectiva. Por lo que se refiere al código genético (para adelantar acontecimientos momentáneamente) la timina del ADN es equivalente al uracilo del ARN.
Otra observación respecto a las fórmulas. En determinados compuestos orgánicos, es posible que un átomo de hidrógeno circule por los mismos con cierta libertad, enganchándose unas veces a un átomo y otras, a otro. Esto ocurre cuando existen enlaces dobles, y el salto del átomo de hidrógeno acarrea una conmutación de los enlaces dobles.

En el uracilo, por ejemplo, los átomos de hidrógeno de los grupos hidroxilos pueden conmutar fácilmente con los átomos de nitrógeno que se encuentran contiguos a ellos en el anillo. En realidad, suelen estar con mayor frecuencia con los átomos de nitrógeno que en los grupos hidroxilos. Este fenómeno del desplazamiento de un átomo de hidrógeno se llama tautomerismo. En la figura 42 se indica la forma tautómera del uracilo. Si se compara con la fórmula del uracilo de la figura 41, se observará que, por lo menos en las fórmulas de zigzag, sólo cambia la situación de los enlaces dobles.

(En realidad, no es necesario que nos extendamos más sobre el fenómeno del tautomerismo. Si lo he mencionado es porque, a veces, es necesario enunciar la fórmula de un compuesto como el uracilo en una u otra fórmula tautómera. A falta de una explicación, el lector podría sentirse desconcertado al observar una diferencia inesperada en la distribución de los enlaces dobles de una fórmula a otra).
En muy contadas muestras de ácido nucleico se han detectado un par de pirimidinas menores que presentaban modificaciones de la estructura de citosina. Puesto que por lo que se refiere al código genético, todas ellas se consideran equivalentes de la citosina, no es preciso que el lector se preocupe por ellas. Lo único que necesitamos son las dos purinas y las tres pirimidinas que se detallan en este apartado.
ENSAMBLADURA DE LAS PIEZAS
La lista está ya completa. Los componentes de los ácidos nucleicos con el grupo fosfático, la ribosa, la desoxirribosa, las dos purinas y las tres pirimidinas. En total, ocho «palabras», frente a las veintidós que componen las proteínas.
Esto parece sorprendente, y es que los compuestos que contienen el código genético deberían ser, por lo menos, tan complejos como las proteínas. En realidad, las cosas son aún más sencillas. De las ocho «palabras», al ADN le faltan la ribosa y el uracilo, mientras que el ARN carece de la desoxirribosa y la timina. Por lo que cada una de las variedades de ácido nucleico se compone sólo de seis «palabras».
Pero ¿cómo están unidas estas «palabras»? Levene, el primer hombre que identificó la ribosa y la desoxirribosa en los ácidos nucleicos atacó también este problema. Descompuso el ácido nucleico en grandes fragmentos, cada uno de los cuales contenía varias de las unidades básicas. Operando con estos fragmentos, pudo deducir su estructura.
A principios de la década de los 50, el químico inglés Sir Alexander R. Todd obtuvo por síntesis estructuras a base de las fórmulas propuestas por Levene y averiguó que poseían realmente las propiedades del material obtenido del ácido nucleico. Esto corroboró las hipótesis que, a decir verdad, habían sido aceptadas por los bioquímicos sin demasiados reparos[17].

Levene mantenía que cada parte de ribosa (o desoxirribosa) de la molécula de ácido nucleico tiene un grupo fosfático enganchado en un extremo y una purina o pirimidina en el otro. Esta combinación de grupos se llama nucleótido.
Desde luego, todos los nucleótidos del ARN contienen un grupo de ribosa y, además, una adenina, una guanina, una citosina o un uracil. Por lo tanto, pueden darse cuatro nucleótidos distintos: ácido adenílico, ácido guanílico, ácido citidílico y ácido uridílico. Nuevamente, es la presencia del grupo fosfático lo que da a cada uno de ellos sus propiedades ácidas y agrega la palabra «ácido» a su nombre. Y, por supuesto, por el nombre del nucleótido se sabe qué purina o qué pirimidina contiene.
Dado que estos nucleótidos son de importancia primordial para el código genético, en la figura 43 doy las fórmulas de cada uno de ellos, aunque sólo en forma de zigzag.
Los nucleótidos del ADN se distinguen de los anteriores en que, en lugar de ribosa, contienen desoxirribosa. Por ello, podemos hablar del ácido desoxiadenílico, ácido desoxiguanílico y desoxicitidílico. En el ADN no existe el ácido desoxiuridílico; pero, dado que el lugar del uracil está ocupado por la timina, tenemos el ácido desoxitimidílico, según se indica en la figura 44. Como pueden observar, la diferencia entre éste y el ácido uridílico se reduce a la falta del grupo hidroxilo en el azúcar. El ácido desoxiadenílico se diferencia del adenílico en lo mismo e idéntica diferencia se observa al comparar el ácido desoxiguanílico y el ácido desoxicitidílico con el ácido guanílico y el ácido citidílico respectivamente.
Las variaciones de la disposición de los nucleótidos son sumamente importantes para la química del cuerpo. Hay nucleótidos como los presentados en la figura 43, pero en lugar del único grupo fosfático llevan dos y hasta tres, dispuestos en tándem. Son compuestos clave para el almacenamiento y suministro de energía, siendo el más conocido de ellos el trifosfato de adenosina, que suele abreviarse ATP. Su molécula es como la del ácido adenílico, pero (como indica el nombre del compuesto) lleva tres grupos fosfáticos en lugar del único que posee el ácido adenílico.

Existen también compuestos semejantes a los nucleótidos que actúan en colaboración con ciertas enzimas, por lo que se denominan coenzimas. En ellos, la parte de ribosa se sustituye a veces por una glucosa o algún carbohidrato, mientras que en lugar de la purina o pirimidina puede haber otros tipos de anillos que contengan nitrógeno.
Sin embargo, nosotros no vamos a ocupamos más que de los nucleótidos obtenidos de los ácidos nucleicos de los que en cualquier molécula de ácido existen sólo cuatro variedades. La pregunta que ahora se suscita es cómo se combinan los nucleótidos para formar los ácidos nucleicos propiamente dichos. También esto fue averiguado por Levene y corroborado por Todd.
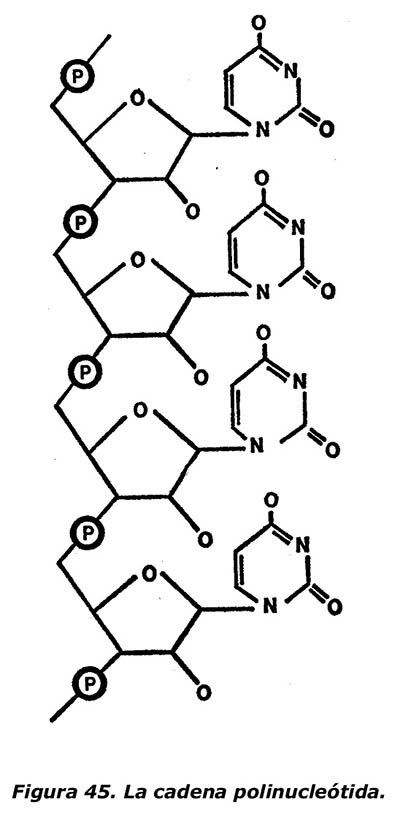
El secreto está en el grupo fosfático. En los nucleótidos unitarios, consiste generalmente en un fosfato primario con un enlace, aunque también puede ser un fosfato secundario con dos enlaces, el segundo de los cuales está unido a un segundo nucleótido. Toda una serie de nucleótidos puede enlazarse mediante fosfatos secundarios, como puede verse en la serie de ácidos uridílicos de la figura 45.
Los nucleótidos unidos de la figura 45 forman una cadena polinucleótida. Cuando el polinucleótido está compuesto por nucleótidos de ribosa (como en la figura 45), cada grupo de azúcar tiene un grupo hidroxilo que sobresale. (Está representado por la O que sale de cada anillo de azúcar).
Si el polinucleótido está formado por nucleótidos de desoxirribosa, no se da este grupo hidroxilo libre. (Compárense figuras 44 y 43). De ello se deduce, pues, que el ARN está compuesto por una cadena polinucleótida de cuya parte de azúcar sobresalen grupos hidroxilos, mientras que el ADN está formado por una cadena polinucleótida sin grupos hidroxilos.
La cadena polinucleótida tiene cierta similitud con la cadena polipéptida de las proteínas. La cadena polipéptida está formada por una «columna vertebral» de poliglicina que discurre a lo largo de toda la cadena, dándole unidad; de ella parten las diferentes cadenas secundarias que dan diversidad a la molécula. Análogamente, la estructura polinucleótida tiene una «columna vertebral» de azúcar y fosfato que discurre a todo lo largo de la cadena y de la que parten las diferentes purinas y pirimidinas. En la figura 46 se muestra una comparación esquemática.
En la molécula de proteína sólo varían las cadenas secundarias y en la molécula de ácido nucleico, sólo las purinas y las pirimidinas.
Aquí se plantea lo que parece una curiosa paradoja. En la columna vertebral de poliglicina puede haber hasta veintidós cadenas secundarias diferentes (contando como uno de los elementos la falta de una cadena secundaria para una glicina); pero en la columna vertebral de azúcar y fosfato sólo hay cuatro purinas o pirimidinas diferentes.

¿Cómo con sólo cuatro «palabras» para determinar el código puede el ácido nucleico suministrar la información necesaria para fabricar una molécula que puede contener hasta veintidós «palabras»?
Oportunamente nos ocuparemos de esta pregunta clave y hallaremos la respuesta, pero no sin antes examinar más detenidamente la molécula de ácido nucleico propiamente dicha.