MOLÉCULAS GIGANTES
A principios del siglo XIX, cuando los químicos descubrieron la existencia del átomo, las primeras moléculas que estudiaron eran pequeñas, las «palabras monosílabas» que mencionamos al principio del capítulo anterior. Pero era imposible tratar las sustancias orgánicas sin tropezarse con moléculas realmente gigantes.
Afortunadamente, las moléculas gigantes debían su gran tamaño únicamente a la circunstancia de estar formadas por numerosas moléculas pequeñas unidas entre sí como las cuentas de un rosario. Fue posible tratar la molécula grande liberando las pequeñas moléculas al disociarlas de las unidades contiguas. Esta operación suele realizarse calentando la molécula grande en una solución ácida.
Si bien la molécula grande, intacta, es difícil de estudiar, las unidades pequeñas, una vez disueltas, se manejan con facilidad. Los conocimientos recogidos mediante el estudio de la estructura de las distintas piezas, permitieron deducir la estructura de la molécula gigante en su estado original.
Si consideramos las pequeñas unidades como «palabras» y la molécula grande, una «frase», la situación es parecida a la del que tiene que descifrar una inscripción en un idioma extranjero del que sólo posee nociones. Si ha de leer una frase de carrerilla, puede que no capte el significado; pero si va descifrando palabra por palabra con ayuda de un diccionario, tal vez llegue a enterarse.
La primera gran molécula, o macromolécula, estudiada por este sistema resultó sorprendentemente simple. Ya en 1814 se descubrió que el almidón, calentado en una solución ácida durante un tiempo suficiente, se descomponía en unidades de estructura idéntica. La estructura era glucosa, un tipo de azúcar cuya molécula tiene un tamaño que es la mitad del del azúcar corriente. Su fórmula empírica es C6H12O6, o sea que esta molécula contiene sólo veinticuatro átomos. Sin embargo, cientos y hasta miles de estas unidades unidas forman una sola molécula de almidón, compuesta, por lo tanto, por cientos de miles de átomos.
La celulosa, la sustancia endurecedora de la madera, también se descompone en glucosa, la misma glucosa que se encuentra en el almidón. Pero en la celulosa, las unidades de glucosa están unidas de un modo distinto a como lo están las del almidón.
Con el tiempo, se observó que otras macromoléculas estaban formadas por largas cadenas de una sola unidad. El caucho es buen ejemplo de ello, ya que está compuesto por moléculas de isopreno, un hidrocarburo de cinco carbonos, relativamente simple.
En el siglo XX, los químicos descubrieron la forma de fabricar macromoléculas que no se dan en la Naturaleza. Idearon métodos para unir muchas moléculas de una unidad determinada (en algunos casos, de dos unidades) para producir caucho y fibras sintéticas y gran variedad de plásticos.
Todas estas macromoléculas, naturales y sintéticas, tenían en común su gran tamaño y su composición, formada por miles de unidades. Pero, aunque grandes, estas moléculas carecen de complejidad. Comprenderán lo que quiero decir si piensan que un largo hilo de cuentas, de idéntico color y tamaño, no tiene nada de complejo. No requiere la menor creatividad enhebrar cuentas; la tira puede ser más larga o más corta, de una sola vuelta o de dos; pero no puede haber más diferencia.

El tamaño tiene sus ventajas, desde luego. Los miles de unidades de glucosa que se agrupan para formar la celulosa producen una sustancia dura y fuerte que permite al árbol resistir la acometida del vendaval y nos proporciona un material nada desdeñable para construir nuestros refugios. Por otra parte, la macromolécula del almidón es un excelente medio para almacenar la energía que contiene la molécula de glucosa con perfecta estabilidad hasta el momento de utilizarla. Entonces, las moléculas de almidón pueden descomponerse fácilmente y las unidades de glucosa, introducirse en la corriente sanguínea.
No obstante, las macromoléculas del orden del almidón y la celulosa no desempeñan una función auténticamente activa en el proceso de la vida. Son materiales pasivos que no actúan sino que reciben la acción de otros.
Con la proteína ocurre algo distinto. Ésta es una macromolécula que, al igual que el almidón y la celulosa, posee gran tamaño y está formada también por pequeñas unidades unidas como las cuentas de un collar. Ahora bien, las moléculas de proteína presentan, además, cierta complejidad. Veamos en qué consiste, en la figura 16.
AMINOÁCIDOS
Hacia 1820, H. Braconnot, químico francés, calentó la gelatina de proteína en ácido y obtuvo cristales de un compuesto de sabor dulce. Con el tiempo, éste recibió el nombre de glicina, derivado de la palabra griega que significa «dulce».
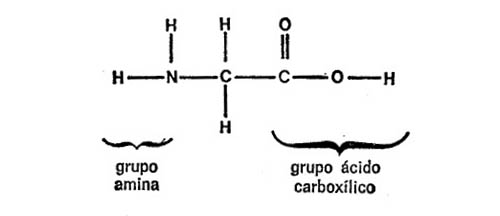
Cuando se estudió la estructura de la molécula de glicina se vio que era simple. Estaba compuesta sólo de diez átomos, menos de la mitad de los que forman la glucosa. En la figura 16 se indica la fórmula de la glicina.
Como puede observarse, la molécula consiste en un átomo de carbono central, enlazado con un grupo de aminas[5] por un lado y con un grupo de ácido carboxílico por otro. Los dos enlaces restantes están ocupados por átomos de hidrógeno. Naturalmente, un compuesto que contiene un grupo de aminas y un grupo de ácido carboxílico puede considerarse un aminácido y lo es. En realidad, la glicina es un ejemplo de aminoácido eminentemente simple.
Si todo hubiese terminado aquí, la macromolécula de proteína no se consideraría más compleja que la del almidón o cualquier otra. Pero Braconnot fue más allá, y de los productos de descomposición de la proteína obtuvo un segundo aminoácido al que llamó leucina (de la palabra griega que significa «blanco») porque blancos eran los cristales que obtuvo.
A medida que iban pasando las décadas, otros investigadores descubrían más aminoácidos. Ya en 1935 se halló un nuevo e importante aminoácido cuya existencia no se sospechaba, entre los productos de la descomposición de las moléculas de proteína. Estos aminoácidos son, pues, las piezas de construcción que componen las moléculas de proteína.
El número de diferentes aminoácidos hallados en los tejidos vivos es bastante grande. Algunos de ellos, no obstante, no se encuentran en las moléculas de proteína sino que se dan en otros elementos. Otros se encuentran en las moléculas de proteína, pero sólo en uno o dos casos extraordinarios.
Si nos limitamos a los aminoácidos que se encuentran en todas o casi todas las moléculas de proteína, su número es bastante manejable: 21. Añádase a éstos otro aminoácido que se encuentra principalmente en sólo una molécula de proteína (aunque muy importante) y tenemos un total de 22.
Una de las características que distinguen a la molécula de proteína es la de que ninguna otra macromolécula, natural o sintética, está formada por tantas unidades diferentes, ni siquiera por la cuarta parte.
Para demostrar la importancia de esta característica, volvamos al ejemplo de la tira de cuentas. Imaginen que, en lugar de una serie de cuentas idénticas les presentan veintidós juegos, todos distintos entre sí por color, forma y tamaño. En este caso, se puede producir una gran variedad de fantásticos dibujos, simetrías insospechadas y agradables gradaciones que, de otro modo, hubieran sido imposibles.
Es lo que ocurre con la molécula de proteína.
Pero observemos más detenidamente los aminoácidos, para ver cómo aparecen estas diferencias, en qué modo imprimen su sello en la molécula de proteína y crean la posibilidad de obtener una variedad prácticamente infinita.
Para una mayor claridad, voy a permitirme una forma esquemática para el manejo de las fórmulas estructurales. Se trata de ampliar el principio geométrico que sirve para representar los anillos de átomos, a átomos que no forman parte de anillos. (Ello supone ir más allá de lo que suelen ir los químicos profesionales en la simplificación de fórmulas, pero no importa. Este libro no está dirigido a los químicos profesionales. Su única finalidad es la de explicar la base química de la herencia en la forma más simple y directa y si para eso se requiere un poco de innovación… pues ¡adelante!).
Al explicar la formación de las figuras geométricas indicadas en la figura 15 dije que en cada ángulo desocupado hay un átomo de carbono. Análogamente, todo enlace de carbono que no se indica se supone conectado a un átomo de hidrógeno.
Ampliemos ahora este principio trazando una línea en zigzag para los átomos que no forman anillo. Podemos seguir suponiendo que en todos los ángulos (y extremos) no ocupados hay un átomo de carbono. Además, podemos aplicar también la regla del «hidrógeno existente aunque no aparente» a átomos que no sean de carbono.
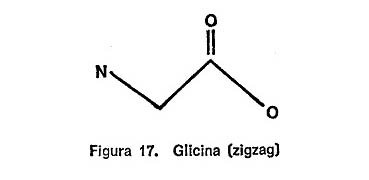
Por ejemplo, en la figura 17 represento la «fórmula en zigzag» de la glicina que el lector puede comparar con la fórmula completa de la figura 16.
El paso siguiente es averiguar en qué se diferencian de la glicina los otros aminoácidos que componen la molécula de proteína. En general, puede decirse que todos poseen un átomo de carbono central al que están unidos por un enlace un grupo amino y, por otro, un grupo de ácido carboxílico.
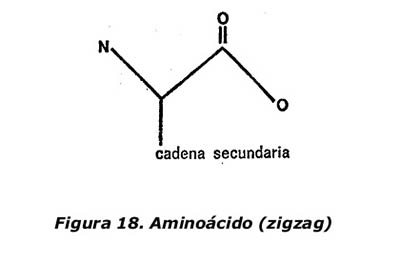
Las diferencias se producen de la siguiente forma: en la glicina, el tercer y cuarto enlace del átomo de carbono central están unidos a átomos de hidrógeno. En los demás aminoácidos el tercer enlace está unido a un átomo de hidrógeno, pero el cuarto está unido a un átomo de carbono que, a su vez, forma parte de un grupo de átomos más o menos complicado llamado cadena secundaria.
La diferencia se aprecia claramente comparando la fórmula general de los aminoácidos en forma de zigzag que se indica en la figura 18 con la fórmula en zigzag de la glicina representada en la figura 17.
Cada aminoácido tiene su propia cadena secundaria característica, y la diferencia esencial entre los aminoácidos radica en la naturaleza de esta cadena secundaria.
CADENAS SECUNDARIAS
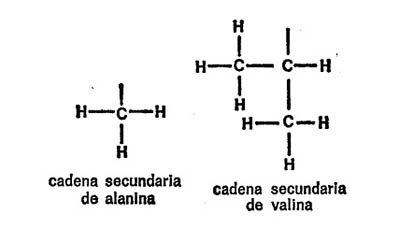
Vamos a examinar ahora cada uno de los veintiún aminoácidos que nos ocupan, además de la glicina, con sus respectivas cadenas secundarias, para hacemos una idea de las diferencias existentes. Para empezar, presentaré cada cadena secundaria al completo, indicando todos los átomos, para que quede constancia. Primeramente, hay cuatro aminoácidos cuya cadena secundaria es un grupo hidrocarburo. Uno es la leucina, ya mencionada. Los otros tres son: alanina, valina e isoleucina. Sus cadenas secundarias se indican en la figura 19.

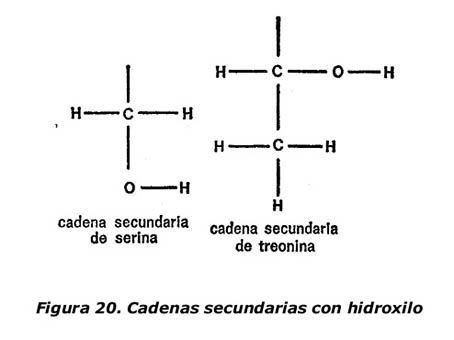
Dos aminoácidos tienen grupos hidroxilos en las cadenas secundarias. Son: serina y treonina, y sus cadenas secundarias aparecen en la figura 20. La treonina fue, precisamente, el último grupo que se descubrió, en 1935. Los químicos están casi seguros de que no queda ya ningún otro aminoácido importante por descubrir (es decir, un aminoácido que se dé en todas o casi todas las proteínas).
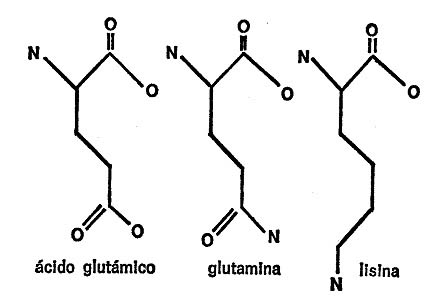
Dos aminoácidos contienen grupos de ácido carboxílico en la cadena secundaria. Son el ácido aspártico y el ácido glutámico. Otros dos aminoácidos, muy parecidos a los anteriores tanto por el nombre como por la estructura, tienen un grupo amida en lugar del grupo carboxil y son la asparagina y la glutamina. Las cuatro cadenas secundarias se indican en la figura 21.

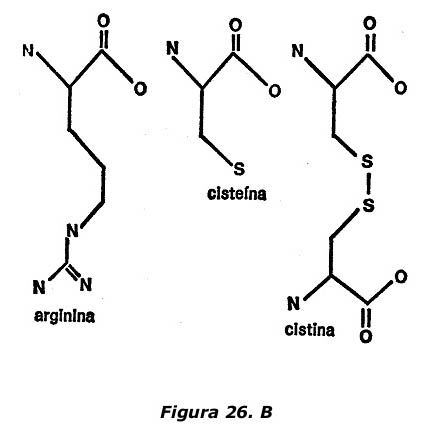
Dos aminoácidos contienen grupos amina en la cadena secundaria; uno es la lisina y el otro, la arginina[6]. Ambas cadenas secundarias se indican en la figura 22.

Tres aminoácidos contienen átomos de azufre en la cadena secundaria. Uno es la metionina, que tiene un solo átomo de sulfuro entre dos átomos de carbono (combinación que en ocasiones recibe el nombre de tio-éter. Otro, la cisteína, posee un grupo de tiol, mientras que un tercero, la cistina, tiene un grupo bisulfuro. Las tres cadenas secundarias se indican en la figura 23.

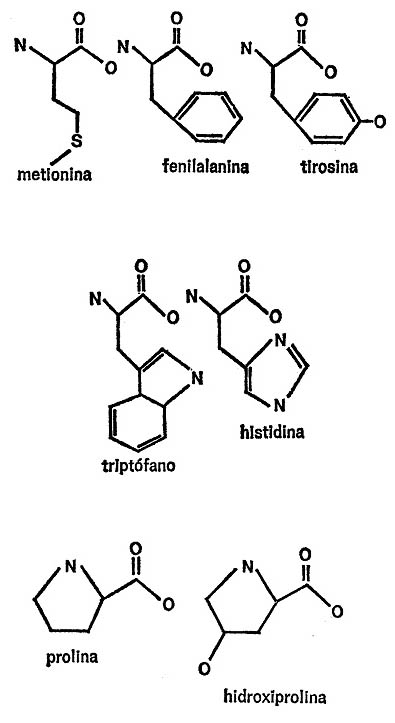
Obsérvese que en el extremo de la cadena secundaria de la molécula de cistina existe una formación de aminoácidos. Si las moléculas se enunciaran completamente, la figura resultante sería la de dos moléculas de cistina conectadas entre sí por el grupo de bisulfuro. La molécula de cistina se descompone fácilmente en dos moléculas de cisteína y con igual facilidad se pueden unir dos moléculas de cisteína para formar una molécula de cistina. (Ello explica la similitud de nombres que, por otra parte, es un inconveniente, ya que si la letra «e» se omite o se añade accidentalmente, o si no se pronuncian los nombres correctamente, estos dos aminoácidos se confunden). Nada menos que cuatro aminoácidos tienen anillos en las cadenas secundarias. Dos, fenilalanina y tirosina, tienen anillos de benceno; uno, el triptófano, tiene un anillo de indol y el cuarto, histidina, tiene un anillo de amidazol. Las cadenas secundarias se indican en la figura 24.

Por último, hay dos aminoácidos cuyas cadenas secundarias presentan una peculiaridad. Giran sobre sí mismas y se unen al grupo amino conectado al átomo de carbono central.
Por ello, en la figura 25, se indican completas las fórmulas de estos dos aminoácidos, prolina e hidroxiprolina. Obsérvese que cada compuesto (pirrol) adopta la disposición de un anillo de pirrol (sin los enlaces dobles) a causa de esta extraña formación de la cadena secundaria. (Por cierto que el nombre «prolina» se deriva de «pirrol»).
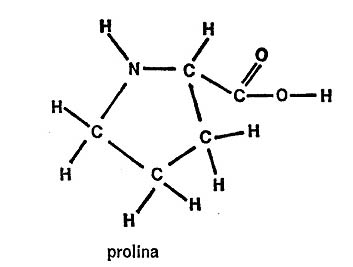

A propósito, la hidroxiprolina es el aminoácido que sólo se encuentra en una proteína. Ésta es el colágeno, que forma buena parte del tejido conjuntivo de los cuerpos animales, incluido el nuestro, por supuesto. Se halla en la piel, en el cartílago, en ligamentos y tendones, en los huesos, cascos y cuernos. Si se hierve prolongadamente, el colágeno se descompone en una proteína familiar, la gelatina, por lo que en ésta aparece también la hidroxiprolina.
La lista está completa. Ya tenemos los veintidós aminoácidos, las veintidós «palabras» que componen la «frase» de la molécula de proteína[7]. Ahora me parece conveniente dar, a modo de resumen, una lista de todos los aminoácidos con fórmula de zigzag, tal como aparecen en la figura 26. En ella se aprecian las diferencias estructurales y las afinidades familiares. Aplicando las reglas que se dan unas cuantas páginas atrás, el lector puede, si lo desea, convertir cada uno de estos zigzags en fórmula completa.



DE LA PALABRA A LA FRASE
Puesto que ya conocemos las «palabras», veamos cómo podemos unirlas para formar una «frase». Este problema no fue resuelto hasta la primera década del siglo XX, con la primera demostración satisfactoria de esta operación, hecha por el químico alemán Emil Fischer.
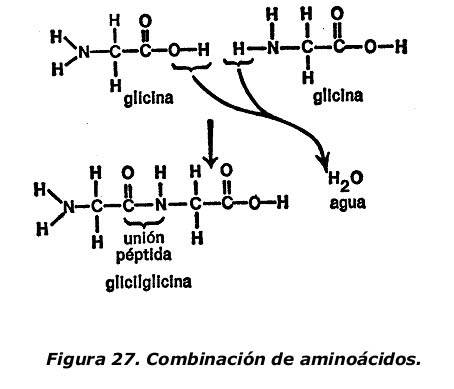
Fischer demostró que dos aminoácidos se combinan al unirse el grupo de ácido carboxílico de uno con el grupo amino del otro y que, en el proceso, se pierde una molécula de agua. Si, a fin de simplificar, utilizamos dos moléculas de glicina, la unión se produce tal como se indica en la figura 27, en la que se muestra la posición de cada átomo.

Como puede verse, el grupo hidroxilo que forma parte del grupo de ácido carboxílico se combina con uno de los átomos de hidrógeno del grupo amino. El grupo hidroxilo y el átomo de hidrógeno juntos forman una molécula de agua, H2O, que se elimina. Con la eliminación del grupo hidroxilo y del átomo de hidrógeno, a cada molécula de glicina le queda un enlace libre y éstos se unen para formar la glicilglicina.
Estas combinaciones de aminoácidos se llaman péptidos, nombre derivado de la palabra griega que significa «digerir», por haber sido obtenidos por primera vez de proteína semidigerida. La combinación de átomos que forma la unión entre los aminoácidos es -CONH- (en la que pueden verse los restos del grupo de ácido carboxílico y del grupo amino originales) y se llama conexión péptida.
La glicilglicina es un péptido compuesto por dos aminoácidos, por lo que recibe el nombre de bipéptido. (Es lo que podríamos llamar una «frase» de dos palabras). Pero la glicilglicina todavía tiene un grupo amino en un extremo y un grupo de ácido carboxílico en el otro, por lo que puede combinarse con otros aminoácidos por uno o por ambos extremos. De este modo pueden construirse tripéptidos, tetrapéptidos, pentapéptidos, etcétera[8].
No hay límite en el número de aminoácidos que pueden unirse por conexión péptida. Un péptido compuesto de un número de aminoácidos no determinado se llama polipéptido, ya que el prefijo «poli» se deriva de la palabra griega que significa «muchos».
Supongamos que deseamos enunciar un gran número de moléculas de glicina unidas por conexiones péptidas. La figura en zigzag que obtenemos es la que se indica en la figura 28.
Este polipéptido, formado únicamente por unidades de glicina, es la poliglicina. Una molécula de poliglicina no es más compleja ni tiene mayor versatilidad de tipo proteínico que cualquier otra macromolécula formada únicamente por unidades de una o dos variedades. Un polipéptido natural formado en su mayor parte por glicina y alanina es la seda, cuya falta de complejidad es evidente. La seda es utilizada por los organismos que la forman únicamente para aprovechar la fuerza de su fibra. Es poco más que una especie de versión animal de la celulosa.
Otro ejemplo es la fibra artificial nilón. Ésta está formada por dos unidades, una es un ácido bicarboxílico (una cadena de carbono con un grupo de ácido carboxílico en cada extremo) y la otra, una biamina (cadena de carbono con un grupo amino en cada extremo). Las unidades están unidas por conexiones péptidas y lo que se aprecia del nilón es, también, principalmente, su resistencia.
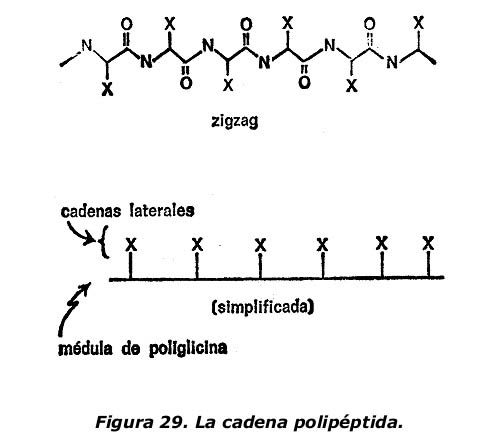
Por lo que se refiere a la versatilidad, hemos de tener en cuenta que una cadena polipéptida natural casi siempre está formada por 22 unidades diferentes. Esta cadena polipéptida difiere de la poliglicina en que las cadenas secundarias aparecen a intervalos periódicos. Como puede verse en la figura 29 que representa esta cadena polipéptida en zigzag, las cadenas secundarias (que llevan el símbolo X) parten alternativamente en sentidos opuestos.
La cadena polipéptida consta, pues, de dos partes: 1) una médula de glicina que recorre la cadena en toda su longitud, y 2) varias cadenas secundarias que parten de dicha médula.
Puesto que lo único que nos interesa son las características de la molécula de proteínas que le dan su versatilidad, pasaremos por alto el rasgo común y nos concentraremos en las cadenas secundarias. Los detalles de la médula de poliglicina (ahora que ya los conocemos) carecen de importancia y, para nuestro objetivo, podemos representarlos perfectamente por una simple línea recta. Para una mayor simplificación, haremos partir todas las cadenas secundarias de un mismo lado. La figura 29, que muestra la cadena de polipéptidos en forma de zigzag, también ha sido simplificada de este modo para facilitar la comparación.
A menudo, la molécula de proteína consiste sólo en una cadena de polipéptidos. Pero también puede tener dos o tres cadenas de polipéptidos, unidas por moléculas de cistina. Si observan la fórmula de la cistina de la figura 23 verán que en ambos extremos hay sendas combinaciones de aminoácidos. Esto quiere decir que un extremo aminoácido puede formar parte de una cadena polipéptida y el otro, formar parte de otra, como puede verse en la fórmula simplificada en la figura 30. En este caso, las cadenas polipéptidas están unidas por una conexión de bisulfuro.

La conexión de bisulfuro se disuelve fácilmente mediante tratamientos químicos que dejan intactas las cadenas polipéptidas en sí, de manera que los químicos pueden estudiarlas por separado. Una vez Fischer hubo determinado la naturaleza de la médula de poliglicina y resuelto esta parte del problema, los químicos pudieron concentrarse en la disposición de las cadenas secundarias, aspecto del que también nosotros nos ocuparemos a continuación.