Capitolo 11
La libreria standard
La specifica del linguaggio C non si limita a illustrare la sintassi e la semantica del linguaggio, ma fornisce anche una corposa e dettagliata descrizione di quella che è la sua libreria, ossia di quelle che sono le facilities o funzionalità che un programmatore può impiegare per compiere operazioni di gestione della memoria, di manipolazione di caratteri e stringhe, di gestione di file, di diagnostica, di gestione degli errori e così via.
In linea generale, una suite di compilazione fornisce gli strumenti necessari per compilare e linkare un programma scritto in C e può fornire (è il caso di MinGW) oppure può non fornire (è il caso di GCC) anche un’implementazione completa della libreria standard così come altre librerie specifiche di un particolare hardware o sistema operativo.
Un esempio di libreria molto impiegata, soprattutto nei sistemi GNU/Linux, è quello dato dalla libreria GNU C Library (libc), la quale definisce non solo tutte le funzionalità così come specificate dallo standard ISO di C ma anche feature aggiuntive specifiche allo standard POSIX, ad altri sistemi Unix, al sistema GNU e così via discorrendo.
ATTENZIONE
Se si desidera scrivere programmi in C portabili tra sistemi e piattaforme diverse bisogna solo utilizzare le funzionalità della libreria standard.
DETTAGLIO
POSIX (Portable Operating System Interface for Computer Environments), il cui nome è stato ideato da Richard Stallman, è uno standard (ISO/IEC 9945) che definisce, tra le altre cose, una serie di funzionalità o API sviluppate con l’intento di garantire una compatibilità tra le diverse varianti di Unix e altri sistemi operativi aderenti. In pratica quando si scrive un programma che aderisce allo standard POSIX si può essere certi che lo stesso sarà portabile tra le diverse famiglie di Unix (Solaris, MAC OS X, BSD e così via), GNU/Linux incluso.
Ritornando alla libreria di C, oggetto di questa trattazione, essa è formalmente costituita da ben 29 header (Tabella 11.1), ciascuno dei quali dichiara un insieme di funzioni correlate unitamente a definizioni di tipi e macro necessari per facilitarne l’uso.
<assert.h> |
<inttypes.h> |
<signal.h> |
<stdint.h> |
<threads.h>* |
<complex.h>* |
<iso646.h> |
<stdalign.h> |
<stdio.h> |
<time.h> |
<ctype.h> |
<limits.h> |
<stdarg.h> |
<stdlib.h> |
<uchar.h> |
<errno.h> |
<locale.h> |
<stdatomic.h>* |
<stdnoreturn.h> |
<wchar.h> |
<fenv.h> |
<math.h> |
<stdbool.h> |
<string.h> |
<wctype.h> |
<float.h> |
<setjmp.h> |
<stddef.h> |
<tgmath.h> |
|
* Gli header complex.h,
stdatomic.h e threads.h sono opzionali,
ossia un’implementazione può decidere di non supportarli. |
||||
Principi generali
Una qualsiasi libreria standard del linguaggio C è costituita nella sostanza da due parti: un insieme di file header, come quelli indicati nella Tabella 11.1, che definiscono tipi e macro e dichiarano variabili e funzioni (ne forniscono il prototipo); un insieme di file oggetto che contengono sia l’implementazione effettiva delle funzioni sia la definizione delle variabili così come sono stati dichiarati nei citati file header.
Ciò detto, per poter utilizzare una particolare facility della
libreria, come per esempio quella che consente la manipolazione
delle stringhe, è sufficiente includere nel file sorgente in uso,
tramite la direttiva del preprocessore #include, il
file header relativo come può essere, ritornando all’esempio
descritto, il file string.h.
In più, è possibile includere i file header in qualsiasi ordine
si preferisce, anche più volte (sono protetti da apposite guard
macro), e la prassi detta che le stesse inclusioni avvengano
scrivendo le direttive #include come prime istruzioni
di un file di codice sorgente e subito dopo un commento che indica
lo scopo di tale file di codice (in ogni caso, lo standard dice
anche che un header deve essere incluso al di fuori di qualsiasi
definizione esterna di una funzione e prima dell’uso di un
identificatore che si riferisca a un oggetto, funzione, tipo o
macro il cui header medesimo dichiara o definisce).
NOTA
A voler essere pignoli è possibile usare una funzione dichiarata in un file header anche senza includere quel file; è sufficiente, infatti, scrivere la dichiarazione di quella funzione nell’esatto modo com’è è il suo prototipo indicato dallo standard. Tuttavia, si sconsiglia questa pratica, perché il file header può definire tipi e macro utilizzabili per operare correttamente con la facility dell’header relativo e perché abbiamo la certezza che quella dichiarazione è di sicuro scritta in conformità con lo standard.
Dopo l’inclusione del file header desiderato è quindi possibile impiegare all’interno del codice sorgente i tipi lì dichiarati ed essere certi che il compilatore durante la fase di compilazione compili correttamente il programma. Nel contempo si può essere certi che il linker, durante la fase di linking, risolva correttamente quei riferimenti con le reali definizioni fornite nei file oggetto collegati.
Infine vi sono una serie di regole o restrizioni che è doveroso seguire quando si include un file header e che riguardano le modalità di denominazione dei propri identificatori.
- Gli identificatori che iniziano con un carattere underscore
(
_) cui segue una lettera maiuscola oppure un altro carattere underscore sono riservati per qualsiasi uso. Un programma non deve dunque mai usare nomi scritti con questa convenzione. - Gli identificatori che iniziano con un carattere underscore sono riservati per definire nomi con scope a livello di file sia nello spazio dei nomi dei tag sia in quello degli identificatori ordinari. Un programma non deve dunque mai usare nomi scritti con questa convenzione eccetto se sono scritti all’interno delle funzioni.
- Gli identificatori dichiarati con linkage esterno sono riservati come identificatori con linkage esterno. Un programma non deve dunque mai dichiarare identificatori di funzioni o oggetti riservati come propri identificatori con linkage esterno.
- Gli identificatori dichiarati con scope a livello di file sono riservati nell’ambito del rispettivo spazio dei nomi. Un programma non deve dunque mai dichiarare identificatori riservati come propri identificatori se include il file header relativo.
- I nomi di macro impiegati nei file header standard sono riservati. Un programma non deve dunque mai definire un nome di una macro uguale a uno di quelli specificati nei file header che include.
NOTA
Nel documento degli standard di C vi è anche un
apposito paragrafo, denominato “Future library directions”, che
indica una serie di nomi che iniziano con determinati caratteri che
sono altresì riservati per usi futuri e che dunque non dovrebbero
essere impiegati come propri identificatori in un programma. Per
esempio, per l’header <ctype.h> è stabilito che
tutti i nomi che iniziano con i caratteri is o
to seguiti da una lettera scritta in minuscolo sono
riservati per future estensioni.
A parte gli identificatori indicati nei rispettivi file header e nell’apposita sezione “Future library directions”, nessun altro identificatore è riservato. Se quindi un programma dichiara o definisce un identificatore in un contesto dove è riservato o definisce un identificatore come un altro nome di macro riservato, il comportamento è non definito.
Infine è utile sapere che lo standard permette agli implementatori della libreria di C di definire, eventualmente, delle macro parametriche con lo stesso nome delle funzioni e ciò per le consuete ragioni di migliorare le performance di un programma (come già detto, un’espansione inline del codice di una macro è considerata più veloce di un’invocazione di una corrispettiva funzione).
In ogni caso è sempre possibile evitare che venga usata la macro parametrica al posto della reale funzione perché, per esempio, alla supposta migliore velocità di esecuzione preferiamo una minore dimensione del codice eseguibile.
Per far ciò possiamo adottare una delle due tecniche seguenti (Snippet 11.1 e 11.2) laddove:
- la prima consiste nel rimuovere la definizione della macro
parametrica usando la direttiva del preprocessore
#undef; - la seconda consiste nel racchiudere il nome della funzione tra
una coppia di parentesi tonde
( )perché così quel nome non sarà riconosciuto nell’ambito di un valido contesto sintattico di invocazione di macro (il preprocessore, infatti, non riconosce quel nome come un nome di una macro parametrica perché il suo nome non è subito seguito da una parentesi tonda sinistra).
Gli Snippet 11.1 e 11.2 mostrano, rispettivamente, come
utilizzare le due tecniche citate nel caso un’implementazione
avesse scelto di implementare la funzionalità valore assoluto
di un numero come una funzione ordinaria e come una macro
parametrica, entrambe denominate abs, e presenti nel
file header <stdlib.h>.
Snippet 11.1 Utilizzo esplicito di una funzione al posto di una macro parametrica: I tecnica.
#include <stdlib.h>
...
int main(void)
{
#undef abs
int res = abs(-5);
...
}
Snippet 11.2 Utilizzo esplicito di una funzione al posto di una macro parametrica: II tecnica.
#include <stdlib.h>
...
int main(void)
{
int res = (abs) (-5);
...
}
Gestione dei caratteri: <ctype.h>
L’header <ctype.h> dichiara una serie di
funzioni utili sia per classificare un carattere (per esempio per
dire se è alfabetico, se è un numero, se è uno spazio e così via)
sia per effettuare delle conversioni (per esempio per convertire un
carattere da minuscolo a maiuscolo).
Le funzioni qui dichiarate godono delle seguenti proprietà: il
loro comportamento è dipendente dal sistema locale corrente;
l’argomento fornito deve essere di un tipo intero con un valore
però incluso tra 0 e 255 (rappresentabile
cioè come un tipo unsigned char) oppure con un valore
così come ritornato dalla macro semplice EOF definita
nel file header <stdio.h> (in caso contrario il
comportamento non sarà definito); quelle di classificazione
ritornano tutte un valore di tipo int diverso da 0
(true), per indicare che il valore dell’argomento è
conforme con quanto indicato da ciascuna, uguale a 0
(false) nel caso contrario; quelle di conversione
ritornano un valore di tipo int che indica il valore
dell’argomento convertito in minuscolo oppure in maiuscolo.
Nel contesto di utilizzo delle funzioni dichiarate nell’header
<ctype.h> è anche importante comprendere bene il
significato di carattere visualizzabile (printing
character) e di carattere di controllo (control
character).
Nel primo caso esso si riferisce a un membro del corrente set di caratteri locali che occupa una posizione visualizzabile sul display di un device (tutte le lettere e i numeri sono caratteri visualizzabili); nel secondo caso esso si riferisce a un membro del corrente set di caratteri locali che non è visualizzabile.
Così, se un’implementazione usa il set di caratteri US-ASCII a 7
bit avremo che i caratteri nel range di valori da 0x20
(space) a 0x7e (tilde) saranno
considerati come caratteri stampabili, mentre i caratteri nel range
di valori da 0x0 (null) a 0x1f
(unit separator) e il carattere con il valore
0x7f (delete) saranno considerati come
caratteri di controllo non stampabili.
Listato 11.1 CharacterHandling.c (CharacterHandling).
/* CharacterHandling.c :: Un caso d'uso dell'header <ctype.h> :: */
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#define SIZE 12
// typedef per una funzione di tipo (int) -> int
// di fatto tutte le funzioni di classificazione in <ctype.h> hanno questa segnatura
typedef int (*ch)(int);
int main(void)
{
ch c[] = // array di puntatori a ch
{
isalnum, isalpha, isblank, iscntrl, isdigit, isgraph, islower,
isprint, ispunct, isspace, isupper, isxdigit
};
char *desc[] = // array di puntatori a carattere
{
"e' un carattere alfanumerico?", "e' un carattere alfabetico?",
"e' un carattere vuoto?", "e' un carattere di controllo?",
"e' una cifra decimale?",
"e' un carattere stampabile eccetto lo spazio ' '?",
"e' un carattere minuscolo?",
"e' un carattere stampabile incluso lo spazio ' '?",
"e' un segno di punteggiatura?", "e' un carattere di spazio bianco?",
"e' un carattere maiuscolo?", "e' una cifra esadecimale?"
};
char chars[] = "aj\t\r9Xl ;\nUf"; // stringa da controllare...
for (int i = 0; i < SIZE; i++)
{
int res = c[i](chars[i]); // invoca la corretta funzione di classificazione
if (isblank(chars[i]) || iscntrl(chars[i]) || isspace(chars[i]))
printf("\\x%02x\t-> %-50s [%s]\n",
chars[i], desc[i], res ? "true" : "false");
else
printf("%c\t-> %-50s [%s]\n", chars[i], desc[i], res ? "true" : "false");
}
return (EXIT_SUCCESS);
}
Output 11.1 Dal Listato 11.1 CharacterHandling.c.
a -> e' un carattere alfanumerico? [true]
j -> e' un carattere alfabetico? [true]
\x09 -> e' un carattere vuoto? [true]
\x0d -> e' un carattere di controllo? [true]
9 -> e' una cifra decimale? [true]
X -> e' un carattere stampabile eccetto lo spazio ' '? [true]
l -> e' un carattere minuscolo? [true]
\x20 -> e' un carattere stampabile incluso lo spazio ' '? [true]
; -> e' un segno di punteggiatura? [true]
\x0a -> e' un carattere di spazio bianco? [true]
U -> e' un carattere maiuscolo? [true]
f -> e' una cifra esadecimale? [true]
Il Listato 11.1, data la stringa chars, che
contiene una serie di caratteri, invoca una precisa funzione di
controllo dichiarata nell’header <ctype.h> al
fine di mostrare se il corrente carattere processato è
alfanumerico, è alfabetico, è vuoto, è di controllo e così via.
In dettaglio avremo che la funzione:
isalnumtesta se un carattere è una lettera dell’alfabeto oppure è una cifra numerica, ossia se è alfanumerico. Nel nostro caso il carattere'a'corrisponde a quanto detto;isalphatesta se un carattere è una lettera dell’alfabeto. Nel nostro caso il carattere'j'corrisponde a quanto detto;isblanktesta se un carattere è un carattere vuoto standard, ossia un carattere spazio' 'oppure un carattere di tabulazione orizzontale'\t'. Nel nostro caso il carattere'\t'corrisponde a quanto detto e infatti ne viene stampato il codice esadecimale che è0x09nel sistema corrente che fa uso del set di caratteri US-ASCII a 7 bit;iscntrltesta se un carattere è un carattere di controllo. Nel nostro caso il carattere'\r'(carriage return) corrisponde a quanto detto, e infatti ne viene stampato il codice esadecimale che è0x0dnel sistema corrente che fa uso del set di caratteri US-ASCII a 7 bit;isdigittesta se un carattere è una cifra numerica, ossia un carattere con un valore tra'0'a'9'inclusivi. Nel nostro caso il carattere'9'corrisponde a quanto detto;isgraphtesta se un carattere è un carattere grafico, ossia un carattere effettivamente visualizzabile (esclude, quindi, il carattere spazio' 'che è considerato “stampabile” ma non grafico). Nel nostro caso il carattere'X'corrisponde a quanto detto;islowertesta se un carattere è una lettera minuscola. Nel nostro caso il carattere'l'corrisponde a quanto detto;isprinttesta se un carattere è un carattere visualizzabile, ossia se occupa uno spazio nel display del device relativo e indipendentemente se quello spazio non è occupato da un glifo cioè da un simbolo grafico (include, quindi, il carattere spazio' 'che è considerato “stampabile” ancorché non grafico). Nel nostro caso il carattere' 'corrisponde a quanto detto;ispuncttesta se un carattere è un carattere di punteggiatura. Nel nostro caso il carattere';'corrisponde a quanto detto;isspacetesta se un carattere è uno dei seguenti caratteri di spazio bianco:' '(space),'\f'(form feed),'\n'(new line),'\r'(carriage return),'\t'(horizontal tab) e'\v'(vertical tab). Nel nostro caso il carattere'\n'corrisponde a quanto detto;isuppertesta se un carattere è una lettera maiuscola. Nel nostro caso il carattere'U'corrisponde a quanto detto;isxdigittesta se un carattere è una cifra numerica esadecimale, ossia un carattere con un valore tra'0'a'9'inclusivi, oppure tra'A'e'F'inclusivi oppure tra'a'e'f'inclusivi. Nel nostro caso il carattere'f'corrisponde a quanto detto.
Lo Snippet 11.3 mostra invece l’utilizzo delle funzioni
tolower e toupper che, rispettivamente,
convertono una lettera minuscola in una lettera maiuscola e una
lettera maiuscola in una lettera minuscola.
Snippet 11.3 Uso di tolower e di toupper.
...
#include <ctype.h>
int main(void)
{
int a = 'A';
int b = 'b';
int c = '3';
// in entrambi i casi il valore della variabile argomento rimane immutato
int toA = tolower(a); // 97 ossia 'a' in US-ASCII 7 bit
int toB = toupper(b); // 66 ossia 'B' in US-ASCII 7 bit
// nessuna conversione; toC avrà lo stesso valore di c
int toC = tolower(c); // 51 ossia '3' in US-ASCII 7 bit
...
}
Gestione delle stringhe: <string.h>
L’header <string.h> dichiara una molteplicità
di funzioni in grado di compiere diverse operazioni sulle stringe
categorizzate dallo standard nel seguente modo: funzioni di
copia; funzioni di concatenazione; funzioni di
comparazione; funzioni di ricerca; funzioni
varie.
Sono altresì definiti il tipo size_t e la macro
NULL con la stessa semantica già illustrata in altre
unità didattiche ossia, per rammentarle: l’uno è utilizzato per
indicare il risultato dell’operatore sizeof, l’altra
per indicare una costante di tipo puntatore nullo.
Concetti propedeutici
Una sequenza di zero o più caratteri scritti nel codice sorgente
in accordo con la Sintassi 11.1, ossia tra una coppia di doppi
apici "", è definito dallo standard come letterale di
tipo stringa (string literal). I caratteri lì inseribili
direttamente possono essere parte di qualsiasi membro del corrente
set di caratteri eccetto, però, il carattere doppio apice
", il carattere backslash \ e il
carattere new line.
Sintassi 11.1 Letterale di tipo stringa.
"[s_char_sequence]"
Snippet 11.4 Alcuni esempi di letterali stringa.
// è possibile usare le stesse sequenze di controllo viste per i letterali carattere
printf("\tNel mezzo del cammin di nostra vita\nmi ritrovai per una selva oscura,");
// è possibile "spezzare" una stringa su più righe usando
// il carattere backslash
printf("\nche' la diritta via era smarrita.\n\n \
\tAhi quanto a dir qual era e' cosa dura\n");
// è possibile scrivere due stringhe separandole da caratteri di spazio bianco
printf("esta selva selvaggia e aspra e forte\n"
"che nel pensier rinova la paura!\n");
Lo Snippet 11.4 mostra la scrittura di alcuni letterali stringa evidenziando anche alcune tecniche utili che consentono, in un caso, di dividere senza alcun problema sintattico un letterale stringa nel “mezzo” separandolo tra più righe, e, nell’altro caso, di unire due letterali stringa a formare un unico letterale stringa.
Nel primo caso si utilizza il backslash \ come
ultimo carattere di una sequenza di caratteri di una riga e poi,
sulla riga successiva, si continuano a scrivere i rimanenti
caratteri fino al successivo backslash \ oppure al
doppio apice " di chiusura del relativo letterale
stringa (in questo caso ricordiamo che durante la fase 2 di
traduzione del codice sorgente il compilatore congiungerà [line
splicing] tutte le righe fisiche separate da un carattere
backslash \ in un’unica riga logica, e pertanto il
letterale stringa diviso apparirà essere un unico letterale
stringa).
Nel secondo caso si utilizzano degli spazi bianchi per separare due letterali stringa adiacenti (in questo caso ricordiamo che durante la fase 6 di traduzione del codice sorgente il compilatore concatenerà quei letterali stringa adiacenti a formare un unico letterale stringa).
Solitamente, comunque, entrambe le tecniche permettono di “spezzare” letterali stringa particolarmente lunghi in modo da distribuirli su più righe di testo, e ciò al fine di rendere più leggibile o gradevole la formattazione del codice sorgente.
ATTENZIONE
Nel primo caso, ossia se si utilizza il carattere
\, detto anche in questo contesto di continuazione
di riga, bisogna prestare attenzione al fatto che, se quando
si va a capo si scrivono degli spazi bianchi, gli stessi faranno
parte dell’output del letterale stringa, e ciò potrà o
meno essere un effetto desiderato (Listato 11.2).
Listato 11.2 StringLiterals.c (StringLiterals).
/* StringLiterals.c :: Alcuni letterali stringa :: */
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
printf("\tNel mezzo del cammin di nostra vita\nmi ritrovai per una selva oscura,");
printf("\nche' la diritta via era smarrita.\n\n \
\tAhi quanto a dir qual era e' cosa dura\n");
// in questo caso gli spazi bianchi dopo il carattere backslash e nella
// seconda riga "rovinano" la formattazione della seconda terzina
// del Canto I della Divina Commedia di Dante Alighieri
printf("esta selva selvaggia e aspra e forte\n \
che nel pensier rinova la paura!\n");
return (EXIT_SUCCESS);
}
Output 11.2 Dal Listato 11.2 StringLiterals.
Nel mezzo del cammin di nostra vita
mi ritrovai per una selva oscura,
che' la diritta via era smarrita.
Ahi quanto a dir qual era e' cosa dura
esta selva selvaggia e aspra e forte
che nel pensier rinova la paura!
Dal punto di vista prettamente tecnico un letterale stringa è un
array di caratteri, dove ogni elemento ha il tipo
char, e ha le seguenti caratteristiche: ha una classe
di memorizzazione statica e dunque permane in memoria per tutta la
durata del programma; il compilatore vi pone in automatico, come
ulteriore e ultimo carattere, un carattere definito nullo
(null character) che serve come indicatore o marcatore di
“fine” stringa.
Questo carattere nullo, espresso dalla sequenza di escape
'\0', è nella pratica un byte con tutti i suoi bit a 0
e ha il valore 0 nel set di caratteri US-ASCII a 7
bit.
ATTENZIONE
Il carattere zero '0' non è
la stessa cosa del carattere nullo '\0'.
Infatti, nel set di caratteri US-ASCII a 7 bit, il suo valore è
48 in base decimale o 30 in base
esadecimale.
L’apposizione del carattere nullo fa sì che l’array di caratteri “utilizzato” per memorizzare un letterale stringa sia di dimensione pari alla quantità dei caratteri del letterale più uno (il carattere nullo); la “lunghezza” del letterale stringa, però, sarà data sempre da quella dei caratteri effettivi meno quel carattere nullo.
IMPORTANTE
Bisogna quindi rammentare che quando si parla di
“dimensione” di un letterale stringa (o dell’equivalente
variabile stringa) si fa riferimento alla quantità di
memoria utilizzabile per rappresentarla nel corrispettivo array di
caratteri, e ciò include sempre anche il carattere nullo
'\0'. Viceversa, quando si parla di “lunghezza” di un
letterale stringa (o dell’equivalente variabile stringa)
si fa riferimento alla quantità di caratteri che la costituiscono
eccetto sempre il carattere nullo '\0'.
Snippet 11.5 Dimensione in memoria e lunghezza di caratteri di un letterale stringa.
// sz varrà 4 perché saranno 4 i byte utilizzati per memorizzare:
// 'd', 'u', 'e' e '\0'
size_t sz = sizeof "due";
// len varrà 3 perché il letterale stringa "due" è costituito, in effetti, da 3 caratteri
size_t len = strlen("due");

Figura 11.1 Il letterale stringa “due” rappresentato in memoria come array di caratteri.
Array e stringhe
Un letterale stringa può essere assegnato come valore a un array di caratteri durante la sua fase di inizializzazione (Snippet 11.6), e ciò comporta la “copia” di quei caratteri in quell’array (avremo in memoria due copie della stringa di cui una rappresentata dal letterale stringa e l’altra dall’array di caratteri che ne contiene i caratteri).
Snippet 11.6 Array e stringhe.
...
#define LEN 10
#define MIN_LEN 5
#define MAX_LEN 25
int main(void)
{
// in questo caso la dimensione di name è uguale alla lunghezza del letterale
// stringa più 1 per il carattere '\0'
char name[LEN + 1] = "Pellegrino";
// in questo caso la dimensione di city è rilevata automaticamente dal compilatore...
char city[] = "Roma";
// in questo caso la dimensione di job è superiore rispetto alla lunghezza
// del letterale stringa
char job[MAX_LEN] = "Software Developer";
// in questo caso la dimensione di last_name è inferiore rispetto alla lunghezza
// del letterale stringa
char last_name[MIN_LEN] = "Principe";
// in questo caso la dimensione di preferred_color è uguale alla lunghezza
// del letterale stringa ma non tiene conto del carattere '\0'
char preferred_color[3] = "RED";
// nation è esplicitamente inizializzato con un array di caratteri...
char nation[] = {'i', 't', 'a', 'l', 'y'};
nation[0] = 'I'; // OK, nessun problema si può modificare un elemento dell'array
// error: incompatible types when assigning to type 'char[5]' from type 'char *'
nation = "Italia";
...
}
Lo Snippet 11.6 dichiara una serie di array di caratteri che inizializza con dei letterali stringa appropriati; per ognuno di essi è importante dire quanto segue.
- Per l’array
name, dato che il letterale"Pellegrino"è lungo 10 caratteri, esplicitiamo la sua grandezza tramite la macroLEN, che vale10, più il valore esplicito1occorrente per considerare l’apposizione del carattere nullo'\0'. Così facendo garantiamo che l’array di caratteri sia considerato una stringa valida e possa essere usata senza problemi dalle funzioni della libreria standard del linguaggio C che assumono che le stringhe siano sempre null-terminated. - Per l’array
citynon indichiamo alcuna dimensione e lasciamo al compilatore l’onere di determinarla in base al numero di caratteri del letterale"Roma". In questo caso la dimensione sarà però pari a5byte e non4byte perché, ribadiamo, vi è considerato anche il carattere nullo'\0'. - Per l’array
jobla dimensione fornita dalla macroMAX_LEN, ossia25, è superiore rispetto ai caratteri del letterale"Software developer"(18+1per il carattere nullo'\0'). In questo caso non vi è alcun problema ma, in accordo con la regola generale degli inizializzatori di un array secondo la quale se il numero di inizializzatori è inferiore alla dimensione indicata i restanti elementi dell’array saranno inizializzati con il valore0, il compilatore pone per gli elementi con indice da19a24altri caratteri nulli'\0'. - Per l’array
last_namela dimensione fornita dalla macroMIN_LEN, ossia5, è inferiore rispetto ai caratteri del letterale"Principe"(8+1per il carattere nullo'\0'). In questo caso ciò potrebbe causare dei problemi; infatti, in accordo con la regola generale degli inizializzatori di un array, se il numero di inizializzatori è superiore alla dimensione indicata un compilatore dovrebbe riportarlo come un errore (GCC, comunque, riporta il messaggio di diagnosticawarning: initializer-string for array of chars is too long, consentendo altresì la compilazione del programma). - Per l’array
preferred_colorla dimensione fornita, ossia3, è capace di contenere tutti e 3 i caratteri del letterale “RED” ma non il carattere nullo'\0'. In questo caso, quantunque il compilatore non segnali nulla di anomalo, l’arraypreferred_colornon è una stringa valida così come indicata dallo standard ma un semplice array di caratteri e dunque non dovrebbe essere usato con le funzioni della libreria standard che si attendono come argomento, per l’appunto, una stringa valida.
TERMINOLOGIA
Per lo standard una stringa è una sequenza contigua di caratteri terminata da un carattere nullo.
- Per l’array
nationnon indichiamo alcuna dimensione ma lo inizializziamo con la sintassi propria degli array di qualsiasi altro tipo, ossia fornendogli una lista di inizializzatori. In questo caso è importante anche dire che l’array di caratteri, mancando del carattere nullo'\0', non è propriamente una stringa nel senso tecnico appena evidenziato. In definitiva, quindi, un array di caratteri è l’unico caso in cui i suoi elementi possono essere forniti usando un letterale stringa oppure una lista di inizializzatori formata da letterali carattere. Notiamo inoltre come sia possibile cambiare il valore di un elemento dell’array di caratteri usando la consueta notazione che impiega l’operatore di subscript[ ](infatti,nation[0]modifica il primo carattere di nation daiaI). Allo stesso tempo, però, non è possibile assegnare a un array di caratteri un altro letterale stringa dopo che è stato già inizializzato, come nel caso dination = "Italia", e ciò perché, ricordiamo, il nome di un array è un lvalue non modificabile, ossia un oggetto che dovrà far riferimento sempre alla stessa zona di memoria.
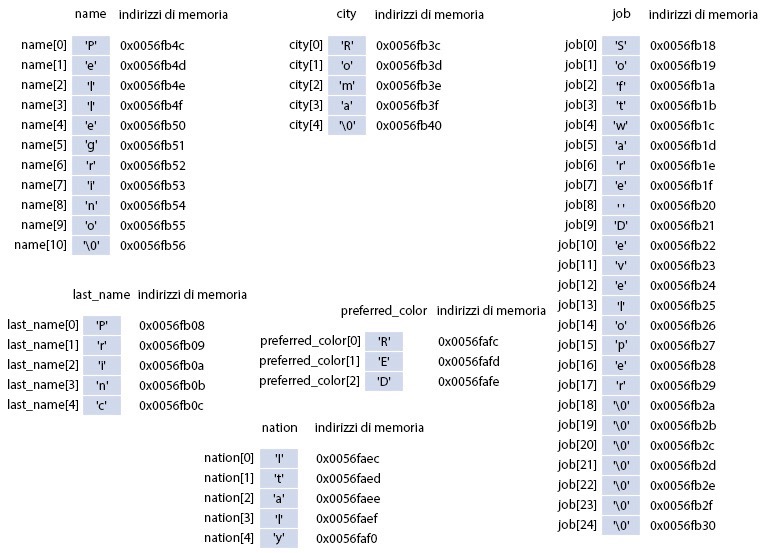
Figura 11.2 Disposizione in memoria degli array di caratteri di cui lo Snippet 11.6.
Puntatori e stringhe
Un letterale stringa può essere assegnato come valore a un puntatore a carattere durante la sua fase di inizializzazione (Snippet 11.7), e ciò comporta che quel puntatore conterrà come valore l’indirizzo di memoria del primo carattere di quel letterale (avremo in memoria una sola copia della stringa rappresentata dal letterale stringa).
Snippet 11.7 Puntatori e stringhe.
...
#define NAME "Pellegrino"
int main(void)
{
// in questo caso name punta all'indirizzo di memoria usato per memorizzare
// il letterale "Pellegrino"; punta al suo primo carattere
char *name = "Pellegrino";
printf("Indirizzo contenuto in name %#p\n", name); // 0x0040a064
printf("Indirizzo di \"Pellegrino\" %#p\n", "Pellegrino"); // 0x0040a064
printf("Indirizzo di \"Pellegrino\" espanso da NAME %#p\n", NAME); // 0x0040a064
// in questo caso è lecito far puntare name a un altro letterale stringa
name = "armando";
// è anche possibile cambiare il valore di un carattere ma in questo caso
// il comportamento sarà non definito
*name = 'A';
...
}
Lo Snippet 11.7 definisce una serie di letterali stringa
"Pellegrino" che sono assegnati come valore,
rispettivamente, alla macro semplice NAME, al
puntatore a carattere name e al secondo parametro
dell’istruzione printf.
In questi casi e in accordo con lo standard, è discrezione del
compilatore in uso se memorizzare i letterali stringa con gli
stessi caratteri in locazioni di memoria differenti oppure
utilizzare sempre le stesse locazioni; nel caso di GCC, l’indirizzo
di memoria scelto sarà sempre il medesimo ossia, nel nostro
sistema, 0xd76940.
Per quanto riguarda il puntatore name notiamo come
esso al principio contenga l’indirizzo del primo carattere del
letterale "Pellegrino" (0xd76940) e poi,
in modo del tutto lecito, contenga l’indirizzo del primo carattere
del letterale "Armando" (0xd76a5c)
successivamente assegnatogli (in questo caso, a differenza del nome
di un array di caratteri, il nome di un puntatore a caratteri è un
lvalue modificabile).
DETTAGLIO
Un letterale stringa è comunque un’espressione
primaria che, come detto, in origine è di tipo array di
char ma, in accordo con la regola generale di
generazione dei puntatori, è abitualmente “modificato” in un tipo
puntatore a char (in un puntatore al primo carattere
di una stringa). Ciò spiega perché il puntatore name
contenga legittimamente un indirizzo di memoria che è quello del
primo elemento dell’array di caratteri (poi puntatore a
char) cui il letterale stringa
"Pellegrino" (name punterà, cioè, al
carattere 'P').
Vediamo, infine, come un’istruzione come *name =
'A', quantunque non faccia generare da parte del compilatore
alcun messaggio diagnostico, è foriera, invece, di un comportamento
non definito (GCC fa terminare bruscamente il programma).
Quanto detto avviene perché un letterale stringa è considerato un dato costante, ossia una sorta di costante di tipo stringa che deve essere posta, perciò, in un’area di memoria che non dovrebbe essere manipolata.
Per evitare quel comportamento non definito è infatti buona
prassi di programmazione dichiarare un puntatore a
char con il qualificatore const (per
esempio const char *name = "Pellegrino";).
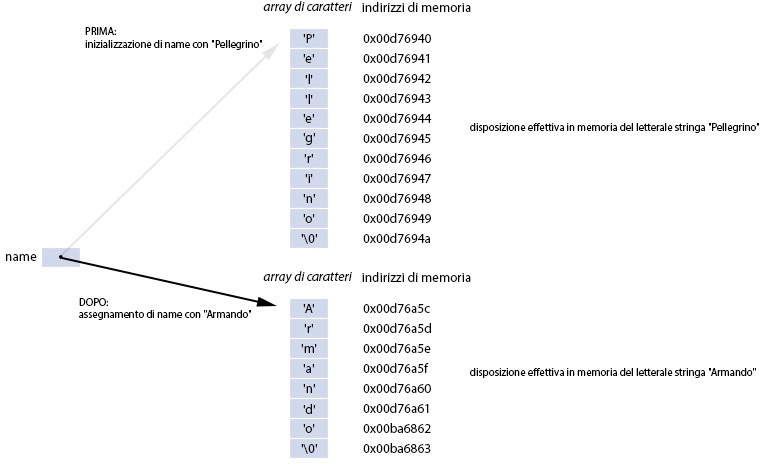
Figura 11.3 Disposizione in memoria del puntatore name e dei letterali stringa di cui lo Snippet 11.7.
Array di stringhe
In C, è possibile costruire un array i cui elementi sono stringhe, in due modi diversi, laddove il primo richiede la dichiarazione di un array bidimensionale mentre il secondo richiede la dichiarazione di un array di puntatori (Snippet 11.8).
Snippet 11.8 Array di stringhe.
...
#define ROWS 5
#define COLS 20
int main(void)
{
// array di array di caratteri (array bidimensionale o matrice)
char a_names[ROWS][COLS] = {"Pellegrino", "Andrea", "Marco", "Luca", "Paolo"};
printf("%zu\n", sizeof a_names); // 100 byte
printf("%s\n", a_names[0]); // Pellegrino
printf("%c\n", a_names[0][3]); // l
// array di puntatori a char
char *p_names[ROWS] = {"Pellegrino", "Andrea", "Marco", "Luca", "Paolo"};
printf("%zu\n", sizeof p_names); // 20 byte
printf("%s\n", p_names[0]); // Pellegrino
printf("%c\n", p_names[0][3]); // l
...
}
Nello Snippet 11.8 l’array a_names è un array di
array di caratteri (cioè un array bidimensionale o matrice) per il
quale il compilatore alloca 100 byte dati dal numero
di righe espresse dalla macro ROWS (vale
5) per il numero di colonne espresse dalla macro
COLS (vale 20) e considerando la
dimensione del tipo char che è di 1
byte.
In questo caso appare evidente come sia stato sprecato prezioso
spazio di memoria perché il compilatore ha allocato per ogni
letterale stringa fornito 20 byte, e ciò indipendentemente dalla
loro lunghezza effettiva ("Luca" ha di sicuro meno
caratteri di "Pellegrino" così come
"Paolo" e via discorrendo).

Figura 11.4 Disposizione tabellare in memoria degli array a_names e p_names di cui lo Snippet 11.8.
L’array p_names, invece, è un array di puntatori a
caratteri (o a stringhe) per il quale il compilatore alloca in
totale solo 20 byte, il cui valore è dato dai 5
puntatori a caratteri (la macro ROWS vale
5) per la loro dimensione che sul nostro sistema a 32
bit è di 4 byte.
In questo caso, quindi, appare evidente come l’utilizzo di un array di puntatori abbia ridotto drasticamente il consumo di memoria; in fondo, ogni elemento di quell’array è solamente un puntatore al primo carattere di ciascun letterale stringa fornito e dunque contiene un mero indirizzo di memoria del “peso” di 4 byte.
A parte, comunque, l’importante differenza in merito alla
quantità di memoria allocata, entrambi gli array possono essere
usati allo stesso modo per recuperare una determinata stringa
oppure per accedere a un singolo carattere; infatti, sia
a_names[0] sia p_names[0] ritornano
entrambi la loro prima stringa ("Pellegrino"), mentre
sia a_names[0][3] sia p_names[0][3]
ritornano entrambi il 4 carattere della prima stringa (il carattere
'l').
Copia di stringhe
La copia di stringhe è un’operazione per effetto della quale
data una stringa, diciamo A, è possibile copiarne i
caratteri, o parte di essi, in un apposito array di caratteri.
Tuttavia, come più volte detto, in C non è possibile usare
direttamente l’operatore di assegnamento = per
assegnare un letterale stringa oppure una stringa a un tipo array
di caratteri dopo che esso è stato dichiarato ed eventualmente
anche inizializzato con valori specifici (Snippet 11.9).
Snippet 11.9 Operatore di assegnamento e array di caratteri.
...
#define LEN 10
int main(void)
{
// operatore di assegnamento durante la fase di assegnamento
// ILLEGALE!!!
char name[LEN + 1];
name = "Pellegrino"; // un nome di un array è un lvalue non modificabile
// non può comparire a sinistra dell'operatore di assegnamento
// operatore di assegnamento durante la fase di inizializzazione
// LEGALE!!!
char city[LEN + 1] = "Roma";
char another_city[LEN + 1] = "Napoli";
// la copia tra array di caratteri è ILLEGALE!
// city è un nome di un array e dunque un lvalue non modificabile
city = another_city;
...
}
Lo stesso non si può dire se usiamo i puntatori a
char laddove l’operatore di assegnamento è usabile
durante la mera fase di assegnamento, ricordando però che l’unica
cosa che è copiata è l’indirizzo di memoria del primo carattere
della relativa stringa (Snippet 11.10).
Snippet 11.10 Operatore di assegnamento e puntatori a caratteri.
// operatore di assegnamento durante la fase di assegnamento
// LEGALE!!!
char *name;
name = "Pellegrino"; // un nome di un puntatore è un lvalue modificabile
// può comparire a sinistra dell'operatore di assegnamento
// name punta al carattere 'P'
// operatore di assegnamento durante la fase di inizializzazione
// LEGALE!!!
char *city = "Roma"; // city punta al carattere 'R'
char *another_city = "Napoli";
// la copia tra puntatori a char è LEGALE!
// tuttavia city non conterrà "Napoli" ma conterrà l'indirizzo
// di memoria dove si troverà il carattere 'N' che sarà anche lo stesso
// indirizzo di memoria contenuto in another_city
// city e another_city punteranno quindi entrambi al carattere 'N'
city = another_city;
Al fine dunque di consentire copie effettive di caratteri tra stringhe è possibile usare una delle due seguenti funzioni:
char *strcpy(char * restrict s1, const char * restrict s2)copia la stringa puntata das2, con annesso carattere nullo, nell’array puntato das1. Ritorna il valore dis1;char *strncpy(char * restrict s1, const char * restrict s2, size_t n)copia non più dincaratteri dall’array puntato das2nell’array puntato das1. Se, tuttavia, l’array puntato das2è una stringa più corta del numero di caratteri indicati dan, alloras1conterrà quella stringa più tanti caratteri nulli quanti servono per “raggiungere” il valore din. Ritorna il valore dis1.
Snippet 11.11 La funzione strcpy.
...
#define LEN 10
#define O_LEN 5
int main(void)
{
char destination[LEN + 1];
char *source = "Pellegrino";
// destination conterrà "Pellegrino" e res punterà a 'P'
char *res = strcpy(destination, source);
// array di massimo 6 caratteri incluso il carattere '\0'
char city[O_LEN + 1];
// ATTENZIONE; comportamento non definito perché city è capace di contenere
// solo 6 caratteri mentre "Napoli" ne contiene 7 incluso '\0'
strcpy(city, "Napoli");
...
}
Snippet 11.12 La funzione strncpy.
...
#define LEN 10
#define O_LEN 5
int main(void)
{
// array di massimo 6 caratteri incluso il carattere '\0'
char city[O_LEN + 1];
// garantiamo che city possa contenere al massimo 5 caratteri validi
// eccetto il carattere '\0' che viene manualmente apposto per i casi
// in cui la stringa da copiare abbia più caratteri del valore massimo
// di caratteri inseribili così come espresso dal terzo argomento
strncpy(city, "Napoli", sizeof city - 1); // 'N' 'a' 'p' 'o' 'l' ?
// apponiamo il carattere '\0' come ultimo carattere dell'array city
// in modo che possa rappresentare una valida stringa
city[sizeof city - 1] = '\0'; // 'N' 'a' 'p' 'o' 'l' '\0'
char name[LEN + 1];
// in questo caso poiché "Paolo" contiene meno caratteri di quelli indicati
// da sizeof name, allora name conterrà "Paolo" e tanti caratteri nulli fino
// alla dimensione espressa da sizeof name o fino a qualsiasi altra dimensione
// espressa; per esempio, se al posto di sizeof name avessimo indicato 7, allora
// name avrebbe contenuto 'P' 'a' 'o' 'l' 'o' '\0' '\0' '\0' ? ? ?, laddove ? ? ?
// indicano i rimanenti 3 caratteri che conterranno valori arbitrari
strncpy(name, "Paolo", sizeof name);
...
}
Concatenazione di stringhe
La concatenazione di stringhe è un’operazione per effetto della
quale date due stringhe, diciamo A e B,
B è aggiunta apposta alla fine di A, e
A conterrà i suoi caratteri più i caratteri di
B.
Per compiere con le stringhe la predetta operazione possiamo utilizzare una delle due seguenti funzioni:
char *strcat(char * restrict s1, const char * restrict s2)appende una copia della stringa puntata das2, con annesso carattere nullo, alla fine della stringa puntata das1. Il primo carattere dis2sovrascrive il carattere nullo alla fine dis1. Ritorna il valore dis1;char *strncat(char * restrict s1, const char * restrict s2, size_t n)appende non più dincaratteri dall’array puntato das2alla fine della stringa puntata das1. Il primo carattere dis2sovrascrive il carattere nullo alla fine dis1e un carattere nullo è sempre appeso al risultato finale. Ritorna il valore dis1.
Snippet 11.13 La funzione strcat.
...
#define LEN 10
#define O_LEN 5
int main(void)
{
char name[LEN + 1] = "Pelle";
char append[] = {'g', 'r', 'i', 'n', 'o', '\0'};
// name conterrà "Pellegrino\0" e res punterà a 'P'
char *res = strcat(name, append);
// array di massimo 6 caratteri incluso il carattere '\0'
char city[O_LEN + 1] = "Na";
// ATTENZIONE; comportamento non definito perché city è capace di contenere
// solo 6 caratteri di cui 2 già inseriti non considerando il carattere nullo
// "poli" porrà invece 5 caratteri (uno in più) considerando anche il carattere '\0'
strcat(city, "poli"); 'N' 'a' 'p' 'o' 'l' 'i'
...
}
Snippet 11.14 La funzione strncat.
...
define O_LEN 5
int main(void)
{
// array di massimo 6 caratteri incluso il carattere '\0'
char city[O_LEN + 1] = "Na";
// in questo caso, per evitare possibili comportamenti non definiti,
// limitiamo il numero di caratteri inseribili in city con quelli
// ancora disponibili; ricordiamo che strlen ritorna il numero di caratteri
// di una stringa meno il carattere nullo;
// nel nostro caso l'espressione cui il terzo argomento darà come valore 3
// ed è scritta così, senza considerare il carattere nullo, perché strncat lo
// porrà in automatico alla fine della stringa che concatena
strncat(city, "poli", sizeof city - 1 - strlen(city)); // 'N' 'a' 'p' 'o' 'l' '\0'
...
}
NOTA
Per concordanza con lo Snippet 11.13, nello
Snippet 11.4 è chiaramente voluto che city non
contenga il nome completo di "Napoli".
Comparazione di stringhe
La comparazione di stringhe è un’operazione per effetto della
quale date due stringhe, diciamo A e B,
possiamo sapere se A è minore di B,
oppure minore o uguale di B, oppure maggiore di
B, oppure maggiore o uguale di B, oppure
uguale a B, oppure diversa da B.
Questa operazione, nel determinare il risultato relativo, fa affidamento su un algoritmo che si basa su un ordinamento lessicografico dei caratteri costituenti le stringhe, ossia determina alfabeticamente se un carattere viene prima o dopo di un altro.
Ma come fa a dire se un carattere è alfabeticamente precedente o successivo rispetto a un altro? Guarda, semplicemente, al suo corrispondente codice numerico così com’è formalizzato nel corrente set di caratteri in uso.
Così, dato il set di caratteri US-ASCII a 7 bit, una
comparazione tra la lettera j e la lettera
k darà come risultato che j è minore di
k perché il valore numerico di j, ossia
106 in base decimale, è inferiore al valore numerico
di k, ossia 107 in base decimale.
Per comparare delle stringhe, in accordo con quanto detto, possiamo usare:
int strcmp(const char *s1, const char *s2), che compara la stringa puntata das1con la stringa puntata das2. Ritorna un intero più grande di, uguale a o minore di0se la stringa puntata das1è più grande della, uguale alla o minore della stringa puntata das2;int strncmp(const char *s1, const char *s2, size_t n), che compara non più dincaratteri dell’array puntato das1con l’array puntato das2. Ritorna un intero più grande di, uguale a o minore di0, se l’array puntato das1è più grande del, uguale al o minore dell’array puntato das2.
Snippet 11.15 La funzione strcmp.
char name_1[] = "Pelle";
char name_2[] = "Pollo";
// name_1 è più piccola di name_2
// res contiene -1 perché, dopo il carattere 'P' che è uguale in ambedue le stringhe,
// il carattere 'e' (codice ASCII 101) viene prima del carattere 'o' (codice ASCII 111)
int res = strcmp(name_1, name_2);
char name_3[] = "Aldo";
char name_4[] = "Aldo";
// name_3 è uguale a name_4
// res contiene 0 perché tutti i valori numerici di ambedue le stringhe sono uguali
res = strcmp(name_3, name_4);
char name_5[] = "Marco";
char name_6[] = "Marc";
// name_5 è più grande di name_6
// res contiene 1 perché, dopo i caratteri 'M', 'a', 'r' e 'c' che sono uguali,
// in ambedue le stringhe il carattere 'o' (codice ASCII 111) viene dopo
// il carattere '\0' (codice ASCII 0)
res = strcmp(name_5, name_6);
NOTA
Lo standard di C asserisce che se due stringhe
non sono uguali, per esempio perché una è minore di un’altra, la
funzione di comparazione deve ritornare un valore minore di
0. Questo valore può essere semplicemente
-1 come è il caso dello Snippet 11.15 prodotto da GCC,
ma potrebbe essere anche un valore negativo che esprime la
“distanza” tra i codici numerici dei caratteri che differiscono.
Per esempio, un’implementazione che decidesse di scegliere
quest’ultima modalità per rappresentare un risultato di una
comparazione ritornerebbe il valore -10 se comparasse
le stringhe poste in name_1 e name_2.
Snippet 11.16 La funzione strncmp.
...
#define SIZE 6
int main(void)
{
int found = 0;
char *names[SIZE] = {"Aldo", "Paolo", "Marco", "Marcello", "Luca", "Mario"};
for(int i=0; i< SIZE; i++)
{
// se la corrente stringa inizia con "Mar" incrementa found
// di fatto saranno comparati solo 3 caratteri tra "Mar" e le stringhe processate
if(strncmp(names[i], "Mar", 3) == 0)
found++; // al termine del ciclo found conterrà il valore 3
// perché "Marco", "Marcello" e "Mario" iniziano tutte con "Mar"
}
...
}
Ricerca nelle stringhe
La ricerca in una stringa è un’operazione per effetto della quale, dato per esempio un carattere oppure una stringa, si verifica se quel carattere oppure quella stringa è presente nella stringa oggetto della ricerca.
Possiamo, a tal fine, utilizzare le seguenti funzioni.
char *strchr(const char *s, int c)ricerca la prima occorrenza dic(convertito inchar), nella stringa puntata das. Ritorna un puntatore al carattere trovato oppure un puntatore nullo se il carattere non è stato trovato.char *strrchr(const char *s, int c)ricerca l’ultima occorrenza dic(convertito inchar), nella stringa puntata das. Ritorna un puntatore al carattere trovato oppure un puntatore nullo se il carattere non è stato trovato.char *strstr(const char *s1, const char *s2)ricerca la prima occorrenza della sequenza di caratteri della stringa puntata das2nella stringa puntata das1. Ritorna un puntatore alla stringa trovata oppure un puntatore nullo se la stringa non è stata trovata (ses2punta a una stringa di lunghezza 0 la funzione ritorneràs1).
Snippet 11.17 La funzione strchr.
char *name = "Pellegrino";
// res contiene l'indirizzo 0x0, un puntatore nullo perché 'z'
// non è presente nella stringa puntata da name
char *res = strchr(name, 'z');
// res contiene un puntatore al primo carattere 'e' trovato in "Pellegrino"
// per esempio, se 'P' è all'indirizzo 0x405064, allora res avrà come valore
// l'indirizzo 0x405065
res = strchr(name, 'e');
Snippet 11.18 La funzione strrchr.
char *name = "Pellegrino";
// res contiene un puntatore all'ultimo carattere 'e' trovato in "Pellegrino"
// per esempio, se 'P' è all'indirizzo 0x405064, allora res avrà come valore
// l'indirizzo 0x405068
char *res = strrchr(name, 'e');
Snippet 11.19 La funzione strstr.
char *name = "Pellegrino";
// res contiene un puntatore alla prima occorrenza di "rino" trovata in "Pellegrino"
// ritorna, comunque, l'indirizzo di memoria del carattere 'r' di "rino" rispetto
// all'indirizzo di memoria di partenza di 'P' di "Pellegrino"
// per esempio, se 'P' è all'indirizzo 0x405064, res conterrà l'indirizzo 0x40506a
// che è l'indirizzo del carattere 'r' della stringa "rino"
char *res = strstr(name, "rino");
// res contiene un puntatore alla stringa "Pellegrino", ossia al carattere 'P', perché
// il suo secondo argomento è una stringa di lunghezza 0
res = strstr(name, ""); // 0x405064
Lunghezza di una stringa
La lunghezza di una stringa esprime l’ammontare di caratteri costituenti una stringa ed è ottenibile mediante l’utilizzo della seguente funzione:
size_t strlen(const char *s)computa la lunghezza della stringa puntata das. Ritorna il numero di caratteri che precede il carattere nullo'\0'.
Snippet 11.20 La funzione strlen.
char *name = "Pellegrino";
char city[] = "Roma";
// lunghezza della stringa puntata da name
size_t len = strlen(name); // 10
// lunghezza dell'array di caratteri di city
// in questo caso la dimensione dell'array è una grandezza diversa rispetto
// alla quantità di caratteri lì contenuti
// infatti la dimensione di city è pari a 5 (byte) perché include anche il carattere '\0'
len = strlen(city); // 4
// lunghezza di un letterale stringa
len = strlen("Linguaggio C"); // 12
Funzionalità supplementari
L’header <string.h> dichiara anche una serie
di funzioni che iniziano con i caratteri mem... che, a
differenza delle funzioni viste che iniziano con i caratteri
str..., sono state progettate per operare con blocchi
di memoria arbitrari, che contengono dati di qualsiasi
tipo, piuttosto che con mere stringhe ossia con array di caratteri
null-terminated.
Alcune di queste funzioni, che nella sostanza manipolano oggetti di diverso tipo alla stregua di vettori caratteri, sono le seguenti.
void *memcpy(void * restrict s1, const void * restrict s2, size_t n)copiancaratteri dall’oggetto puntato das2nell’oggetto puntato das1. Ritorna il valore dis1.int memcmp(const void *s1, const void *s2, size_t n)compara i primincaratteri dell’oggetto puntato das1con i primincaratteri dell’oggetto puntato das2. Ritorna un intero più grande di, uguale a o minore di 0, se l’oggetto puntato das1è più grande del, uguale al o minore dell’oggetto puntato das2.void *memchr(const void *s, int c, size_t n)ricerca la prima occorrenza dic(convertito inunsigned char), neglincaratteri dell’oggetto puntato das. Ritorna un puntatore al carattere trovato oppure un puntatore nullo se il carattere non è stato trovato.
Snippet 11.21 La funzione memcpy.
...
#define SIZE 6
int main(void)
{
int data[SIZE] = {10, 20, 30, 40, 50, 60};
int o_data[SIZE];
// copia tutti gli elementi da data in o_data
// res conterrà un puntatore al primo elemento dell'array o_data
// la quantità dei byte da copiare, forniti come terzo argomento, sarà data
// dalla quantità di elementi da copiare (SIZE) per la dimensione in memoria
// del tipo di dato di ciascun elemento (int)
int *res = memcpy(o_data, data, SIZE * sizeof(int));
...
}
Snippet 11.22 La funzione memcmp.
...
#define SIZE 12
int main(void)
{
char str_1[SIZE + 1] = "Lup\0o e cane";
char str_2[SIZE + 1] = "Lup\0i e cani";
// qui strcmp si ferma quando trova un carattere non corrispondente oppure
// il carattere nullo '\0' in entrambe le stringhe, e pertanto per essa le due
// stringhe sono considerate uguali
int res = strcmp(str_1, str_2); // 0
// qui memcmp si ferma quando trova un carattere non corrispondente oppure quando si
// raggiunge la quantità di byte da scorrere indicati dal suo terzo argomento
// per essa le due stringhe non sono considerate uguali
res = memcmp(str_1, str_2, SIZE * sizeof(char)); // 1
...
}
Snippet 11.23 La funzione memchr.
...
#define SIZE 12
int main(void)
{
char str_1[SIZE + 1] = "Lup\0o e cane";
// qui strchr scorre la stringa indicata ma si ferma quando trova il primo
// carattere nullo '\0'; pertanto anche se presente il carattere 'c', lo stesso
// non è trovato e res conterrà un puntatore nullo
char *res = strchr(str_1, 'c'); // 0x0
// qui memchr scorre la stringa indicata della quantità di caratteri (byte) indicati
// dal suo terzo argomento; pertanto il carattere 'c' è trovato ed è ritornato
// a res un puntatore a esso
res = memchr(str_1, 'c', sizeof str_1); // 0x28fee7 partendo da 0x28fedf
// puntatore a 'L'
...
}
Input e output: <stdio.h>
L’header <stdio.h> definisce diverse macro,
dichiara tre tipi e svariate funzioni che permettono di compiere
operazioni di input (ingresso o lettura) e output (uscita o
scrittura) dei dati. Tra le macro citiamo le seguenti:
NULL, che indica una costante di tipo puntatore nullo;
EOF, che indica la fine di un file (end of
file); stdin, che indica un puntatore verso lo
standard input; stdout, che indica un
puntatore verso lo standard output; stderr,
che indica un puntatore verso lo standard error.
Per quanto riguarda i tipi abbiamo: size_t,
utilizzato per indicare il risultato dell’operatore
sizeof; FILE, utilizzato per contenere
informazioni su un file; fpos_t, utilizzato per
memorizzare valori di posizionamento all’interno di un file.
Le funzioni, invece, sono categorizzate in quelle che eseguono: operazioni sui file; accessi ai file; input e output formattato; input e output dei caratteri; input e output diretto; posizionamento all’interno di file; gestione degli errori.
Operazioni e accessi sui file
Un file è un’area di storage con un nome al cui interno sono memorizzate delle informazioni o dati ed è, tipicamente, salvato in un’area di memoria permanente come quella offerta dai comuni hard disk, DVD, USB flash drive e via discorrendo.
Una libreria di funzioni di un qualsiasi linguaggio di programmazione di un certo livello, com’è appunto quella di C, offre delle API che consentono di compiere delle comune operazioni sui file come possono essere, per esempio, quelle per la loro apertura e chiusura, lettura e scrittura, rimozione e rinomina e così via.
Prima, tuttavia, di studiare le funzioni per la gestione e la manipolazione dei file messe a disposizione dalla libreria standard del linguaggio C, dobbiamo soffermarci su un concetto molto importante che ruota attorno al termine di stream.
Uno stream è definibile come una “connessione” logica associabile, mappabile, a una sorgente (input source o input stream) oppure a una destinazione (output source o output stream), attraverso la quale avviene il passaggio di dati o informazioni. Questa connessione logica permette di trattare in modo uniforme le varie tipologie di input o di output che possono avere delle caratteristiche proprie e differenti (per esempio, un input può provenire da una comune tastiera, da un sintetizzatore vocale, da uno scanner, da un file e così via; allo stesso modo un output può fluire verso un comune monitor, una stampante, un plotter, un file e così via).
TERMINOLOGIA
Uno stream può essere inteso anche, in senso figurativo, come una sorta di condotto o canale di comunicazione dentro il quale avviene il passaggio di dati che fluiscono da una sorgente oppure che transitano verso una destinazione.
Quanto detto significa, nella pratica, che uno stream può indicare qualsiasi sorgente di input oppure qualsiasi destinazione per l’output laddove, tipicamente, un programma usa come input uno stream associato a una tastiera mentre come output uno stream associato a uno schermo o monitor (ossia un display device).
Di default, l’header <stdio.h> fornisce tre
stream predefiniti, indicati come standard streams, che
sono già disponibili (non è necessario aprirli o chiuderli) e che
sono rappresentati dai nomi delle seguenti macro semplici:
stdinsta per standard input e indica uno stream che è associato a una sorgente di input convenzionale che tipicamente è la tastiera;stdoutsta per standard output e indica uno stream che è associato a una destinazione di output convenzionale che tipicamente è lo schermo;stderrsta per standard error e indica uno stream che è associato a una destinazione di output utilizzata per scrivere messaggi di diagnostica che tipicamente è lo schermo.
Nei moderni sistemi operativi è possibile “forzare” gli stream citati, associandoli a dei file piuttosto che ai device prima menzionati, mediante un procedimento noto con il termine di redirezione dell’input o dell’output.
Per compiere una redirezione dell’input, ossia per assegnare lo
stream stdin a un file, è possibile utilizzare nella
shell di sistema il relativo operatore che fa uso del simbolo
minore di <; per esempio, se abbiamo un programma
denominato get che è deputato a leggere dei caratteri,
possiamo far sì che questi caratteri siano letti da un file
piuttosto che dalla tastiera digitando un comando come get
< file.txt.
Per compiere, invece, una redirezione dell’output, ossia per
assegnare lo stream stdout a un file, è possibile
utilizzare nella corrente shell di sistema il relativo operatore
che fa uso del simbolo maggiore di >; per esempio,
se abbiamo un programma denominato set che è deputato
a scrivere dei caratteri, possiamo far sì che questi caratteri
siano scritti in un file piuttosto che sullo schermo digitando un
comando come set > file.txt.
In più è possibile anche unire entrambi gli operatori per far sì
che, contestualmente, un programma legga dei dati da un file e poi
li scriva in un altro file; per esempio, un comando come copy
< file.txt > file_copy.txt invocherà il programma
copy che leggerà dei dati dal file
file.txt e poi li copierà in un file creato allo scopo
chiamato file_copy.txt.
NOTA
In alcuni sistemi operativi è presente anche un
particolare operatore, espresso tramite il simbolo barra verticale
(|) e definito pipe, che consente di
incanalare l’output di un programma nell’input di un altro
programma. Così, se abbiamo un programma chiamato send
e un altro chiamato receive, il comando send |
receive farà sì che lo standard output di send
sia incanalato nello standard input di receive.
Il sistema di redirezione anzidetto, per quanto comodo e
immediato, si rileva però inadeguato e limitato soprattutto quando
occorre lavorare in un modo più raffinato e complesso sui file; in
questo caso è certamente più opportuno utilizzare le funzionalità
seguenti messe a disposizione dalla libreria standard del
linguaggio C attraverso l’header <stdio.h>.
FILE *fopen(const char * restrict filename, const char * restrict mode): apre un file il cui nome è indicato dalla stringa puntata dafilenamee gli associa uno stream. Il parametromodepunta a una stringa che indica una modalità di apertura (o accesso) perfilename, ossia esplicita quali operazioni possiamo o vogliamo compiere con esso (Tabella 11.2). Ritorna un puntatore a un tipoFILEche rappresenta l’oggetto effettivo che memorizza le informazioni necessarie per controllare il relativo stream. Se l’operazione di apertura di filename fallisce, perché per esempio il file non esiste oppure perché non si hanno i permessi necessari per eseguirla, sarà ritornato un puntatore nullo.
DETTAGLIO
Il tipo FILE è definito nell’header
<stdio.h> mediante un typedef di
una struttura, la quale è costituita da una serie di membri
deputati a contenere informazioni essenziali per il controllo di
uno stream quali: un indicatore di posizione del carattere
corrente, un puntatore associato a un eventuale buffer, un
indicatore di stato per un eventuale errore di lettura o di
scrittura, un indicatore che indica se si è raggiunta la fine di un
file e così via.
int fclose(FILE *stream): chiude il file associato dallo stream cui il puntatorestream. Se vi è un buffer di dati da scrivere lo svuota e li scrive nel relativo file; se vi è un buffer di dati da leggere gli stessi sono scartati. Ritorna0se il file è stato chiuso con successo edEOFin caso contrario (se vi è stato un errore).
DETTAGLIO
EOF è una macro semplice definita
nell’header <stdio.h> che deve espandersi con
un’espressione costante intera di tipo int con un
valore negativo (per esempio, in GCC EOF si espande
come -1). EOF è ritornata da diverse
funzioni di I/O per indicare che non vi è più nessun input da
processare dal corrente stream.
int setvbuf(FILE * restrict stream, char * restrict buf, int mode, size_t size): imposta la modalità di buffering dello stream puntato da stream. Il parametromodedetermina come lo stream sarà bufferizzato e potrà assumere uno dei seguenti valori ricavati dalle macro:_IOFBF(I/O Full Buffering),_IOLBF(I/O Line Buffering) e_IONBF(I/O No Buffering) tutte dichiarate nell’header<stdio.h>. Il parametrobufè un puntatore al buffer desiderato, mentre il parametrosizeè la dimensione di tale buffer. Ritorna0in caso di successo e un valore diverso da0semodefornisce un valore non valido oppure se la richiesta non può essere soddisfatta.
| Modo | Significato |
|---|---|
| “r” | Apre un file di testo per la lettura. |
| “w” | Crea un file di testo per la scrittura oppure lo tronca a zero length se già esiste. |
| “wx” | Crea un file di testo per la scrittura in exclusive mode1. |
| “a” | Apre o crea un file di testo per la scrittura a partire dalla sua fine (append mode). |
| “rb” | Apre un file binario per la lettura. |
| “wb” | Crea un file binario per la scrittura oppure lo tronca a zero length se già esiste. |
| “wbx” | Crea un file binario per la scrittura in exclusive mode1. |
| “ab” | Apre o crea un file binario per la scrittura a partire dalla sua fine (append mode). |
| “r+” | Apre un file di testo per l’aggiornamento (lettura e scrittura)2. |
| “w+” | Crea un file di testo per l’aggiornamento oppure lo tronca a zero length se già esiste. |
| “w+x” | Crea un file di testo per l’aggiornamento in exclusive mode1. |
| “a+” | Apre o crea un file di testo per l’aggiornamento a partire dalla sua fine (append mode). |
| “rb+” | Apre un file binario per l’aggiornamento (lettura e scrittura). |
| “wb+” | Crea un file binario per l’aggiornamento oppure lo tronca a zero length se già esiste. |
| “wb+x” | Crea un file binario per l’aggiornamento in exclusive mode1. |
| “ab+” | Apre o crea un file binario per l’aggiornamento a partire dalla sua fine (append mode). |
| 1 Se si apre un file per la scrittura che già esiste in exclusive mode, l’apertura fallirà. Questa modalità è disponibile a partire dallo standard C11. | |
2 Il carattere + indica che
su un file possono essere compiute, contestualmente, operazioni di
input e di output (il file è in update mode). Tuttavia, è
importante sapere, che tra un’operazione di lettura e una di
scrittura, o viceversa, è obbligatorio invocare la funzione
fflush oppure una funzione per il posizionamento
all’interno di un file (fseek, fsetpos o
rewind), altrimenti i buffer interni potrebbero non
essere svuotati in modo appropriato. |
|
TERMINOLOGIA
Un buffer è un’area di storage temporanea utilizzata, in caso di operazioni di input e output, per memorizzare dei dati prima che questi vengano effettivamente processati (per esempio visualizzati su uno schermo oppure scritti in un file su un hard disk). In pratica i byte da leggere o da scrivere sono raggruppati in “blocchi”, e solo dopo l’accadimento di certe condizioni (per esempio quando il buffer è pieno) quei blocchi sono realmente letti o realmente scritti. Secondo lo standard di C un buffer può essere di tipo: fully buffered, se i byte sono trasmessi al o dal sistema host come blocchi di byte quando tale buffer è pieno; line buffered, se i byte sono trasmessi al o dal sistema host come blocchi di byte quando un carattere di new line è rilevato; unbuffered, se i byte sono trasmessi al o dal sistema host non appena possibile. Da quanto detto appare evidente che l’utilizzo di un buffer per le operazioni di input e output, soprattutto quando bisogna leggere o scrivere dei file, aumenta in modo notevole le performance di un programma perché quei byte non saranno letti o scritti uno alla volta accedendo ripetutamente al disk drive.
int fflush(FILE *stream): forza, per un output stream (uno stream associato cioè a un file in scrittura), lo svuotamento del buffer causando la scrittura effettiva dei dati nel file riferito; per un input stream l’invocazione difflushprovoca un comportamento non definito. Il parametrostreampuò essere un valido puntatore verso un output stream ma anche un puntatore nullo (NULL) nel qual caso avverrà lo svuotamento del buffer di tutti gli output stream aperti. Ritorna0in caso di successo edEOFin caso di errore di scrittura.int remove(const char *filename): rimuove il file il cui nome è rappresentato dalla stringa puntata dafilename. Se il file da rimuovere è aperto, il comportamento è dipendente dalla corrente implementazione. Ritorna0se l’operazione di rimozione va a buon fine, un valore diverso da0in caso contrario.int renane(const char *old, const char *new): rinomina il file il cui nome è rappresentato dalla stringa puntata daoldcon il nome rappresentato dalla stringa puntata danew. Se il nomenewfa riferimento a un file che già esiste, il comportamento è dipendente dalla corrente implementazione. Ritorna0se l’operazione di rinomina va a buon fine, un valore diverso da0in caso contrario.
File di testo e file binari
Un file di testo è un file dove i suoi byte rappresentano dei caratteri che sono leggibili da un essere umano e che sono facilmente modificabili da un qualsiasi editor di testo. Esso è diviso in righe di testo che finiscono con uno speciale marcatore di end of line che è specifico del sistema operativo in uso.
Per esempio, nei sistemi Windows tale marcatore
è rappresentato da un carattere di carriage return (in ASCII
0x0d) cui segue un carattere di new line o line feed
(in ASCII 0x0a). Nei sistemi Unix, invece, tale
marcatore è rappresentato dal solo carattere di new line o line
feed (in ASCII 0x0a). Inoltre, può contenere un altro
marcatore che indica la fine del file (end of file) e che
in alcuni sistemi operativi, tipo Windows, è rappresentato dal
carattere di controllo Ctrl+Z (in ASCII 0x1a). Nei
sistemi Unix, invece, non vi è alcun carattere speciale di end of
file che se inserito in un file di testo è impiegato per
determinarne la sua fine (è possibile però digitare da terminale
durante il processing di un input il carattere di controllo Ctrl+D
per “inviare” un segnale di end of file). Un file binario è un file
i cui byte non rappresentano necessariamente dei caratteri ma
possono rappresentare codice macchina, dati numerici, codifiche di
immagini, di suoni, di video e così via. Questi byte non sono
dunque leggibili in modo significativo da un essere umano oppure
modificabili con un semplice editor di testo. Inoltre, un file
binario non è diviso in righe di testo e non ha un marcatore di
fine riga o di fine file. Ciò detto, appare ora evidente perché
quando usiamo la funzione fopen è necessario indicare
se il file che si intende manipolare deve essere aperto in modo
testo oppure in modo binario. La Figura 11.5 evidenzia la
rappresentazione interna binaria di un numero come
24590 scritto in un file in modalità testo e in
modalità binaria. Nel primo caso vediamo come ogni byte indichi il
codice numerico ASCII dei caratteri '2',
'4', '5', '9' e
'0' (sono memorizzati, per l’appunto in modalità
testo); nel secondo caso, invece, notiamo come i byte utilizzati
siano quelli necessari per la rappresentazione binaria effettiva
del numero 24590 (è memorizzato infatti in modalità
binaria).

Figura 11.5 Il numero 24590 memorizzato in formato testo e in formato binario.
Snippet 11.24 fopen e fclose.
...
// è possibile anche indicare un path completo;
// per esempio in GNU/Linux: "/home/thp/MY_C_FILES/Canto_I" oppure
// in Windows "C:\\MY_C_FILES\\Canto_I" o "C:/MY_C_FILES/thp/Canto_I";
// se si usa nel path per Windows il carattere backspace \ bisogna fare dello
// stesso l'escape perché esso è considerato il carattere iniziale di una sequenza
// di escape e \M e \C non sarebbero riconosciuti come sequence di escape valide;
// nel nostro caso il file si troverà nello stesso path dell'eseguibile
#define FILE_NAME "Canto_I"
int main(void)
{
// apro il file Canto_I in lettura e verifico se file contiene un puntatore
// valido allo stream associato
FILE *file = fopen(FILE_NAME, "r");
if (file)
printf("%s correttamente aperto!\n", FILE_NAME);
else
{
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
exit(EXIT_FAILURE); // termina il programma!
}
// se durante la chiusura è capitato un qualsiasi errore di I/O avvisiamo
// e terminiamo il programma
if (fclose(file) != 0)
{
printf("%s [ERRORE DI CHIUSURA]\n", FILE_NAME);
exit(EXIT_FAILURE); // termina il programma!
}
...
}
Snippet 11.25 setvbuf.
...
#define FILE_NAME "Canto_I"
#define SIZE 1024
int main(void)
{
// un buffer...
char buffer[SIZE];
// apro il file Canto_I in append mode e verifico se file contiene un puntatore
// valido allo stream associato
FILE *file = fopen(FILE_NAME, "a+");
if (file)
{
printf("%s correttamente aperto!\n", FILE_NAME);
// imposto un buffer di 1024 byte e decido che deve essere svuotato
// a ogni new line;
// setvbuf deve essere utilizzato solo dopo che uno stream è stato aperto e prima
// di ogni operazione effettuata con esso
int status = setvbuf(file, buffer, _IOLBF, SIZE);
if (status == 0)
printf("Buffer per %s correttamente impostato!\n", FILE_NAME);
else
printf("%s [BUFFER NON IMPOSTATO]\n", FILE_NAME);
}
else
{
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
exit(EXIT_FAILURE); // termina il programma!
}
// se durante la chiusura è capitato un qualsiasi errore di I/O avvisiamo
// e terminiamo il programma
if (fclose(file) != 0)
{
printf("%s [ERRORE DI CHIUSURA]\n", FILE_NAME);
exit(EXIT_FAILURE); // termina il programma!
}
...
}
Snippet 11.26 remove e rename.
...
#define FILE_NAME "Canto_I"
#define O_FILE_NAME "Canto_I.txt"
#define SIZE 1024
int main(void)
{
// rimuovo il file indicato da O_FILE_NAME
int res = remove(O_FILE_NAME);
if (res != 0)
printf("%s [ERRORE DI RIMOZIONE]\n", O_FILE_NAME);
else
printf("%s correttamente rimosso!\n", O_FILE_NAME);
res = rename(FILE_NAME, O_FILE_NAME);
if (res != 0)
printf("%s [ERRORE DI RINOMINA]\n", FILE_NAME);
else
printf("%s correttamente rinominato in %s!\n", FILE_NAME, O_FILE_NAME);
...
}
Input e output dei caratteri
Nel momento in cui abbiamo a diposizione uno stream, sia standard sia personalizzato, abbiamo bisogno di funzioni che consentano di leggere o scrivere dei caratteri da o in quello stream; così, per l’input dei caratteri, possiamo impiegare quanto segue.
int fgetc(FILE *stream): ottiene un carattere, comeunsigned charpoi convertito inint, dall’input stream puntato da stream. Se definito, aggiorna l’indicatore di posizione del file associato dallo stream. RitornaEOFse l’indicatore di posizione del file si trova alla sua fine (end of file), è impostato oppure vi è un qualsiasi altro errore di input; altrimenti ritorna il successivo carattere.int getc(FILE *stream): ha la stessa semantica difgetc. Tuttavia, bisogna prestare attenzione a utilizzarla perché, potendo anche essere implementata come una macro, potrebbe valutare più di una volta l’argomentostream; pertanto quest’ultimo non dovrebbe mai essere un’espressione che produce side-effect.int getchar(void): ha la stessa semantica digetce usa, di default,stdincome stream. In pratica è come se la funzionegetcfosse invocata comegetc(stdin).char *fgets(char * restrict s, int n, FILE * restrict stream): legge dallo stream puntato dastreamal massimo il numero di caratteri specificati dan(meno 1) e li memorizza nell’array puntato das. Se durante la lettura è incontrato un carattere di new line oppure un end of file la lettura è interrotta, ossia nessun carattere è più parte dell’input; l’eventuale carattere new line è comunque trattenuto. In più, il carattere nullo'\0'è sempre posto nell’arraysdopo la lettura dell’ultimo carattere. Ritorna un puntatore asse la lettura è occorsa correttamente; un puntatore nullo se è occorso un end-of-line e nessun carattere è stato posto nell’array oppure vi è stato un errore di lettura. In definitiva questa funzione è utile per leggere un’intera riga di testo piuttosto che un singolo carattere come fanno le funzionifgetc,getcegetchar.
IMPORTANTE
Prima dello standard C11 era disponibile anche la
funzione gets, avente il prototipo char
*gets(char *s), la quale leggeva i caratteri immessi dallo
stdin (tipicamente dalla tastiera) e li poneva
nell’array puntato da s finché un end of file era
incontrato o un carattere new line era letto. Dallo standard C11
attuale, però, questa funzione è stata soppressa per ragioni di
sicurezza, poiché essa non verifica se la riga di testo contiene
l’esatto numero di caratteri contenibili nel buffer riservato.
Infatti, se tale riga di testo è troppo lunga, si può incorrere in
un buffer overflow che non solo può causare anomalie di
funzionamento di un programma, ma può anche compromettere la
sicurezza di un sistema perché un cracker potrebbe
sfruttare questa “vulnerabilità” per inserire codice malevole con
il quale prendere possesso del sistema.
TERMINOLOGIA
Un cracker è un termine che designa un esperto informatico che sfrutta le sue capacità per entrare nei sistemi, violandoli, al fine di trarne profitti (per rubare informazioni preziose per scopi di spionaggio informatico) oppure per distruggerli o danneggiarli. Esso non deve, in modo assoluto, essere confuso con il termine hacker, che indica invece un esperto informatico che eventualmente vìola dei sistemi per fini di divertimento, apprendimento o semplice curiosità esplorativa.
Per l’output dei caratteri possiamo invece impiegare quanto segue.
int fputc(int c, FILE *stream): scrive il carattere specificato dac, e convertito in ununsigned char, nell’output stream puntato dastreame alla posizione indicata dall’indicatore di posizione del file associato allo stream. Aggiorna quindi l’indicatore alla nuova posizione. Ritorna il carattere scritto oppureEOFse occorre un errore di scrittura.int putc(int c, FILE *stream): ha la stessa semantica difputc. Tuttavia, bisogna prestare attenzione a utilizzarla perché, potendo anche essere implementata come una macro, potrebbe valutare più di una volta l’argomentostream; pertanto quest’ultimo non dovrebbe mai essere un’espressione che produce side-effect.int putchar(int c): ha la stessa semantica diputce usa, di default,stdoutcome stream. In pratica è come se la funzioneputcfosse invocata comeputc(c, stdout).int fputs(const char * restrict s, FILE * restrict stream): scrive la stringa puntata dasnello stream puntato dastream. Il carattere nullo'\0'non è scritto. Ritorna un valore non negativo se la scrittura va a buon fine, altrimentiEOF.int puts(const char *s): scrive la stringa puntata dasnello streamstdoutappendendo un carattere new line. Il carattere nullo'\0'non è scritto. Ritorna un valore non negativo se la scrittura va a buon fine, altrimentiEOF.
Snippet 11.27 fgetc.
...
#define FILE_NAME "stallman"
#define SIZE 100
int main(void)
{
char buffer[SIZE + 1];
int c_read = 0;
FILE *file = fopen(FILE_NAME, "r");
if (file)
{
// legge al massimo 100 caratteri dal file cui FILE_NAME, ma se
// incontra un EOF manda un avviso ed esce dal ciclo;
// il buffer è popolato con il carattere corrispondente al codice
// numerico ritornato da fgetc;
// fgetc ritorna un int perché così può anche ritornare il valore di EOF
// che tipicamente è -1 ed è fuori dal range di valori
// di un unsigned char (0 - 255)
for (int i = 0; i < SIZE; i++)
{
int c = fgetc(file);
if (c != EOF)
buffer[i] = (char) c;
else
{
printf("%s [EOF]\n", FILE_NAME);
c_read = i;
break;
}
}
buffer[c_read != 0 ? c_read : SIZE] = '\0';
printf("%d caratteri letti dal file %s\n", c_read != 0 ? c_read : SIZE,
FILE_NAME);
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
Snippet 11.28 getchar.
...
#define SIZE 10
int main(void)
{
char buffer[SIZE + 1];
int ch;
int n = 0;
// legge da tastiera i caratteri immessi finché non è incontrato un EOF;
// per inoltrare un EOF digitare all'inizio di una riga Ctrl+Z per Windows
// oppure Ctrl+D per GNU/Linux e poi premere il tasto Invio;
// il buffer può comunque essere riempito per al massimo 10 caratteri;
// per esempio, se da tastiera si digitano più di 10 caratteri e poi si preme
// il tasto Invio, il buffer sarà comunque riempito per al massimo quei 10 caratteri
while ((ch = getchar()) != EOF && n < SIZE)
buffer[n++] = (char) ch;
buffer[n < SIZE ? n : SIZE] = '\0';
...
}
IMPORTANTE
Se mandiamo in esecuzione lo Snippet 11.28 ci
accorgeremo che se digitiamo più di 10 caratteri in console gli
stessi saranno tutti visualizzati. Ciò è perfettamente lecito
perché è solo dopo la pressione del tasto Invio che il buffer di
input sarà svuotato e reso disponibile al programma che accetterà
al massimo 10 dei caratteri digitati in accordo con la condizione
di test del ciclo while.
Snippet 11.29 fgets.
...
#define FILE_NAME "stallman"
#define SIZE 10
int main(void)
{
char buffer[SIZE + 1];
FILE *file = fopen(FILE_NAME, "r");
if (file)
{
// legge al massimo 10 caratteri da file e li memorizza in buffer
char *chars = fgets(buffer, sizeof(buffer), file);
printf("%s\n", chars); // Richard Ma
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
Snippet 11.30 fputc.
...
#define FILE_NAME "stallman"
#define FILE_NAME_C "stallman_copy"
int main(void)
{
FILE *file_from = fopen(FILE_NAME, "r");
FILE *file_to = fopen(FILE_NAME_C, "w");
if (file_from && file_to)
{
int ch;
// effettua una copia, carattere per carattere, dal file stallman al file
// stallman_copy
while ((ch = fgetc(file_from)) != EOF)
{
int res = fputc(ch, file_to);
if (res == EOF)
{
printf("%s [ERRORE DI SCRITTURA]", FILE_NAME_C);
exit(EXIT_FAILURE);
}
}
printf("Scrittura completata!\n");
fclose(file_from);
fclose(file_to);
}
else
printf("[ERRORE DI INPUT/OUTPUT]\n");
...
}
Snippet 11.31 putchar.
int ch;
// legge da tastiera i caratteri immessi finché non è incontrato un EOF;
// quando si preme il tasto Invio putchar ne fa l'echo a video;
// per esempio, se si digitano i caratteri abcde[Invio]
// sarà visualizzato abcde
while ((ch = getchar()) != EOF)
putchar(ch);
Snippet 11.32 fputs.
...
#define FILE_NAME "stallman"
int main(void)
{
const char* text =
"\nStallman launched the GNU Project in September 1983 "
"to create a Unix-like computer operating system"
"\ncomposed entirely of free software. With this, he also "
"launched the free software movement. He has"
"\nbeen the GNU project's lead architect and organizer, and "
"developed a number of pieces of widely used GNU"
"\nsoftware including, among others, the GNU Compiler Collection, "
"the GNU Debugger and the GNU Emacs text editor."
"\nIn October 1985 he founded the Free Software Foundation.";
FILE *file = fopen(FILE_NAME, "a");
if (file)
{
// aggiunge al file stallman il testo contenuto nella stringa puntata da text
int res = fputs(text, file);
if (res == EOF)
printf("%s [ERRORE DI SCRITTURA]\n", FILE_NAME);
else
printf("Aggiornamento completato!\n");
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
Tabella riepilogativa
| Nome funzione | Tipologia | Scopo |
|---|---|---|
fgetc |
input | Legge un carattere da un qualsiasi stream. |
getc |
input | Legge un carattere da un qualsiasi stream (possibile macro). |
getchar |
input | Legge un carattere da stdin. |
fgets |
input | Legge una riga di testo da un qualsiasi stream. |
gets1 |
input | Legge una riga di testo da stdin. |
fputc |
output | Scrive un carattere in un qualsiasi stream. |
putc |
output | Scrive un carattere in un qualsiasi stream (possibile macro). |
putchar |
output | Scrive un carattere in stdout. |
fputs |
output | Scrive una riga di testo in un qualsiasi stream. |
puts |
output | Scrive una riga di testo in stdout. |
1 La funzione gets è
deprecata a partire dallo standard C11. |
||
Input e output diretto
Le funzioni sin qui esaminate sono utilizzabili per leggere o
per scrivere espressamente dei caratteri (sono
text-oriented); ciò implica che se le impiegassimo per
scrivere dei dati numerici in un file, anche se questo fosse aperto
in modalità binaria, quei dati sarebbero scritti con dei byte che
indicano la loro rappresentazione numerica in accordo con il set di
caratteri in uso nel corrente sistema, che tipicamente è quello
US-ASCII a 7 bit (la Figura 11.5 prima presentata evidenzia quanto
detto per la memorizzazione del numero 24590).
Le funzioni seguenti, invece, consentono di leggere o scrivere dei dati come meri dati binari, ossia nello stesso formato utilizzato per la loro rappresentazione all’interno di un programma software.
size_t fread(void * restrict ptr, size_t size, size_t nmemb, FILE * restrict stream): legge dallo stream puntato dastreamla quantità di elementi indicati danmemb, di dimensionesize, e li memorizza nell’array puntato daptr. Ritorna il numero di elementi correttamente letti il cui valore, se inferiore rispetto anmemb, indica un errore di lettura o un end of file. Questa funzione è utilizzabile per leggere blocchi arbitrari di memoria, e non dunque solo caratteri, da un file binario.size_t fwrite(const void * restrict ptr, size_t size, size_t nmemb, FILE * restrict stream): scrive nello stream puntato dastreamla quantità di elementi indicati danmemb, di dimensionesize. Gli elementi da scrivere sono ricavati dall’array puntato daptr. Ritorna il numero di elementi correttamente scritti il cui valore, se inferiore rispetto anmemb, indica un errore di scrittura. Questa funzione è utilizzabile per scrivere blocchi arbitrari di memoria, e non dunque solo caratteri, in un file binario.
Snippet 11.33 fread e fwrite.
...
#define FILE_NAME "tmp_data"
int main(void)
{
int data[] = {10, 100, 1000, 10000};
// apre il file in modalità aggiornamento/binaria; se non esiste lo crea
FILE *file = fopen(FILE_NAME, "wb+");
if (file)
{
// scrive l'intero contenuto dell'array data nel file tmp_data
// scrive cioè 4 blocchi di memoria ciascuno di 4 byte
// (nel nostro sistema un int è di 32 bit)
size_t elems = fwrite(data, sizeof data[0], sizeof data / sizeof data[0], file);
if (elems != sizeof data / sizeof data[0])
printf("[ERRORE DI SCRITTURA]\n");
else
{
// necessario perché dopo l'operazione di scrittura compiamo un'operazione
// di lettura
rewind(file); // sposta l'indicatore di posizione del file al suo inizio
int buffer[elems];
// legge dal file tmp_data 4 blocchi di memoria di 4 byte ciascuno
// e li memorizza nell'array di tipo int buffer
size_t elems_i = fread(buffer, sizeof data[0], sizeof data / sizeof data[0],
file);
if (elems_i != sizeof data / sizeof data[0])
printf("[ERRORE DI LETTURA]\n");
else
{
// se il programma funziona correttamente l'output al termine
// del ciclo sarà: Elementi letti: 10 100 1000 10000
printf("Elementi letti: ");
for (size_t i = 0; i < elems_i; i++)
{
printf("%d ", buffer[i]);
}
printf("\n");
}
}
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
Input e output formattato
La libreria di I/O dello standard mette a disposizione delle potenti funzioni che consentono di controllare la formattazione di dati in ingresso (come cioè quei dati debbano essere interpretati) e in uscita (come cioè quei dati debbano essere presentati), consentendo altresì la conversione di caratteri in valori numerici (nel caso quei dati provengano da operazioni di input) oppure di valori numeri in caratteri (nel caso quei dati provengano da operazioni di output).
Per quanto concerne le funzioni per l’output formattato possiamo usare:
int fprintf(FILE * restrict stream, const char * restrict format, ...)scrive nello stream puntato dastreamquanto indicato dalla stringaformatche specifica come gli argomenti variabili forniti debbano essere convertiti per l’output. Ritorna, in caso di successo, il numero di caratteri trasmessi, altrimenti, in caso di insuccesso, per un errore di codifica o di output, un valore negativo;int printf(const char * restrict format, ...): è equivalente alla funzionefprintfconstdoutpassato come argomento al suo parametrostream. Ciò significa cheprintfmanderà il suo output allo stream di output standard che, come già detto, è tipicamente lo schermo;int sprintf(char * restrict s, const char * restrict format, ...):è equivalente alla funzionefprintfeccetto per il fatto che l’output è scritto nell’array specificato dall’argomentospiuttosto che in uno stream. Il carattere nullo'\0'è appeso alla fine dei caratteri scritti ma non è contato come parte del valore di ritorno.
NOTA
In definitiva le funzioni per l’output formattato
non fanno altro che convertire valori numerici negli equivalenti o
in appositi caratteri di output e secondo un determinato stile (per
esempio, un numero di tipo int come 124
può essere convertito da una funzione come printf
negli equivalenti caratteri 1, 2 e
4 visualizzabili sullo schermo in quel modo, ossia
secondo una comune notazione in base decimale).
Di tutte le funzioni esaminate, il parametro format
è fondamentale in quanto rappresenta la cosiddetta “stringa di
controllo del formato” ossia quella stringa al cui interno possono
essere posti sia dei caratteri ordinari, che sono visualizzati così
come sono indicati, sia delle specifiche di conversione (Sintassi
11.2), ognuna delle quali causa la conversione, in formato
carattere, di un argomento corrispondente fornito che può essere
una variabile, una costante o, in linea più generale, una qualsiasi
espressione.
Sintassi 11.2 Specifica di conversione.
%[flags][field_width][.precision][length_modifier]conversion_specifier
Una specifica di conversione inizia con il carattere percento
(%) e può avere, opzionalmente e nell’ordine indicato,
quanto segue.
flags: modificano il significato di una specifica di conversione (Tabella 11.4). Possono essere usati in qualsiasi ordine e anche più di uno.field_width: indica l’ampiezza minima di un “campo” al cui interno saranno visualizzati i caratteri dell’argomento convertito. Se l’argomento convertito ha meno caratteri dell’ampiezza indicata, allora sarà posto di default a sinistra (spazio di padding, il carattere spazio) e i caratteri saranno allineati a destra. Se l’argomento convertito ha più caratteri dell’ampiezza indicata saranno comunque visualizzati tutti. Il valore difield_widthpuò essere un qualsiasi intero non negativo oppure il carattere asterisco (*), nel qual caso indica che il valore di ampiezza sarà ricavato da un apposito argomento fornito.
| Carattere da usare | Significato |
|---|---|
| - | L’argomento convertito è allineato a sinistra nel suo campo. |
| + | L’argomento convertito sarà sempre visualizzato con un segno (+ o -). |
| [spazio] | Se il primo carattere non è un segno sarà posto un carattere di spazio. |
| # | Specifica una “forma alternativa” per una conversione: per
o, la prima cifra sarà 0; per
x o X, sarà prefisso a un risultato non
nullo 0x o 0X; per a, A, e, E, f, F, g e
G, il risultato avrà sempre un punto decimale anche se nessuna
cifra lo segue; per g e G, dal risultato non saranno rimossi gli
zeri in coda. |
| 0 | Per le conversioni cui d, i, o, u, x, X, a, A, e, E, f, F, g e G viene posto il carattere 0 (zero) come padding al posto del carattere spazio quando l’argomento convertito ha meno caratteri dell’ampiezza indicata (è ignorato se già presente il flag -). |
precision: indica per gli specificatori di conversioned,i,o,u,x, eX, il numero minimo di cifre da scrivere (se il numero ha meno cifre sono posti in testa degli zero iniziali); pera,A,e,E,f, eF, il numero di cifre da visualizzare dopo il punto decimale; pergeG, il massimo numero di cifre significative; pers, il massimo numero di caratteri da scrivere. Il valore diprecisiondeve sempre essere prefisso dal carattere punto (.) e può essere un intero oppure il carattere asterisco (*), nel qual caso indica che il valore di precisione sarà ricavato da un apposito argomento fornito.length_modifier:specifica la dimensione di un argomento (Tabella 11.5) asserendo cioè che lo stesso ha in effetti un tipo “più piccolo” o “più grande” rispetto a quanto espresso dal relativo specificatore di conversione (per esempio, per uno specificatore di conversione comed, che indica che l’argomento da convertire è un intero, anteporgli il modificatorehfarà intendere che l’argomento da convertire dovrà invece essere di tiposhort int);length_modifierè dunque un modificatore della lunghezza di un tipo.
Una specifica di conversione termina, quindi, con
conversion_specifier, che specifica tramite un
apposito carattere (Tabella 11.6) il tipo di conversione da
applicare.
Snippet 11.34 printf e applicazione dei flag.
// campo di dimensione 4; allineamento di default a destra
printf("[%4d]\n", 22); // [ 22]
// campo di dimensione 4; allineamento a sinistra
printf("[%-4d]\n", 33); // [33 ]
// un valore negativo visualizzerà sempre il segno - mentre per un valore
// positivo per far visualizzare il segno + bisogna usare il flag +
printf("[%4d]\n", -11); // [ -11]
printf("[%+4d]\n", 11); // [ +11]
// lo spazio permette di allineare 50 con -50 a sinistra perché 50 non usa
// il segno +
printf("[%-4d]\n", -50); // [-50 ]
printf("[% -4d]\n", 50); // [ 50 ]
// visualizza il letterale ottale 012 (rappresenta il new line ASCII)
// con il carattere 0 iniziale; senza # 012 sarebbe visualizzato come 12
printf("[%#4o]\n", 012); // [ 012]
// visualizza il punto decimale anche se può essere omesso; infatti 12.0
// verrebbe visualizzato come 12
printf("[%#4.1f]\n", 12.0); // [12.0]
// 122 ha meno caratteri dell'ampiezza di campo specificata (4) e quel "buco"
// viene riempito con il carattere 0 e non con lo spazio
printf("[%04d]\n", 122); // [0122]
| Carattere da usare | Significato |
|---|---|
| hh (da C99) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo signed char o unsigned char. |
| h | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo short int o unsigned short int. |
| l (elle) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo long int o unsigned long int (non ha effetto sugli specificatori a, A, e, E, f, F, g o G). |
| ll (elle-elle) (da C99) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo long long int o unsigned long long int. |
| j (da C99) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo intmax_t o uintmax_t1. |
| z (da C99) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo size_t. |
| t (da C99) | Per gli specificatori d, i, o, u, x o X indica che l’argomento deve essere trattato come tipo ptrdiff_t2. |
| L | Per gli specificatori a, A, e, E, f, F, g o G indica che l’argomento deve essere trattato come tipo long double. |
1 I tipi intmax_t e
uintmax_t sono dichiarati nell’header
<stdint.h>. |
|
2 Il tipo ptrdiff_t è
dichiarato nell’header <stddef.h>. |
|
NOTA
In tutte le istruzioni printf, nella
stringa di controllo del formato, i caratteri parentesi quadra
sinistra [ e parentesi quadra destra ]
sono stampati così come sono indicati. Come detto qualsiasi altro
carattere ordinario, eccetto quelli propri delle specifiche di
conversione, verrà stampato tale e quale.
| Carattere da usare | Significato |
|---|---|
| d, i | L’argomento di tipo int è convertito in notazione decimale in accordo con lo stile [-]dddd. |
| f, F (da C99) | L’argomento di tipo double è convertito in notazione decimale in accordo con lo stile [-]ddd.ddd, dove il numero di cifre dopo il punto decimale è indicato dal grado di precisione specificato (per default è 6). |
| e, E | L’argomento di tipo double è convertito in notazione esponenziale in accordo con lo stile [-]d.ddd e±dd, dove il numero di cifre dopo il punto decimale è indicato dal grado di precisione specificato (per default è 6). I due dd posti dopo ± indicano la parte esponente. |
| g, G | L’argomento di tipo double è convertito come lo specificatore e (o E se G) se l’esponente è minore di -4 o maggiore o uguale al grado di precisione specificato, altrimenti come lo specificatore f (o F se G). Omette gli zeri in coda se vi sono (dalla parte frazionaria) e il punto decimale se non vi sono cifre nella parte frazionaria rimanente. |
| a (da C99), A (da C99) | L’argomento di tipo double è convertito in notazione esponenziale esadecimale in accordo con lo stile [-]0xh.hhhh p±d, dove il numero di cifre esadecimali dopo il punto decimale è indicato dal grado di precisione specificato (se mancante, la precisione utilizzata sarà sufficiente per fornire l’esatta rappresentazione del valore). Il d posto dopo ± indica un numero decimale che rappresenta una potenza di 2. Se è usato a, allora saranno visualizzate le lettere abcdef x p; se è usato A, allora saranno visualizzate le lettere ABCDEF X P. |
| o | L’argomento di tipo unsigned int è convertito in notazione ottale priva di segno in accordo con lo stile dddd. |
| u | L’argomento di tipo unsigned int è convertito in notazione decimale priva di segno in accordo con lo stile dddd. |
| x, X | L’argomento di tipo unsigned int è convertito in notazione esadecimale priva di segno, e senza 0x o 0X in testa, in accordo con lo stile dddd. Se è usato x, allora saranno visualizzate le lettere abcdef; se è usato X, allora saranno visualizzate le lettere ABCDEF. |
| c | L’argomento di tipo int è convertito in un unsigned char e il risultante carattere è scritto. |
| s | L’argomento di tipo char * fornisce i caratteri da scrivere eccetto il carattere nullo ‘\0’. Se è presente una precisione, essa indica il numero massimo di caratteri da scrivere. |
| p | L’argomento di tipo void * è convertito in una sequenza di caratteri dipendenti dalla corrente implementazione (tipicamente visualizza come valore di un puntatore quello di un indirizzo di memoria). |
| n | L’argomento di tipo int * è utilizzato per memorizzare il
numero di caratteri scritti fino a quel momento dall’attuale
chiamata a fprintf. Non ha luogo alcuna
conversione. |
| % | Scrive letteralmente il carattere %. Non ha luogo alcuna conversione. |
ATTENZIONE
Nell’usare la funzione printf avremo
un comportamento non definito se: vi sono meno argomenti rispetto
alle specifiche di conversione indicate; una specifica di
conversione è invalida; il tipo di un argomento non è di un tipo
corretto così come quello indicato nella corrispondente specifica
di conversione.
Snippet 11.35 printf e applicazione dei modificatori di ampiezza.
// visualizzalo come short int
printf("[%5hd]\n", 10000); // [10000]
// visualizzalo come long int
printf("[%ld]\n", 1500000000L); // [1500000000]
int c_dim = 4;
// visualizzalo come size_t;
// in questo caso notiamo anche l'utilizzo del simbolo * che consente di
// determinare il valore dell'ampiezza del campo dal valore della variabile
// c_dim; è importante notare come per ogni * vi debba essere un apposito
// argomento, in successione, e prima degli argomenti da convertire
printf("[%*zu]\n", c_dim, sizeof (int)); // [ 4]
Snippet 11.36 printf e applicazione degli specificatori di conversione.
// converte un int
printf("[%20d]\n", 12345); // [ 12345]
// converte un double
// la precisione stabilisce che dopo il punto decimale devono essere visualizzate
// al massimo 4 cifre e nel caso ve ne fossero di più avverrà un arrotondamento
printf("[%20.4f]\n", 12345.56789); // [ 12345.5679]
// converte un double (notazione esponenziale)
// dopo il punto, 7 cifre di precisione, e la 'e' di esponente deve essere
// visualizzata in maiuscolo
printf("[%20.7E]\n", 325685.99); // [ 3.2568599E+005]
// converte un double
// per g o G il grado di precisione indica le cifre significative da considerare
// che includono anche quelle poste prima del punto decimale
// il valore è convertito in notazione esponenziale perché il valore dell'esponente
// è più piccolo di -4
// G fa visualizzare E in maiuscolo
printf("[%20.10G]\n", 0.000000078); // [ 7.8E-008]
// converte un double
// visualizza in notazione esponenziale esadecimale
// a visualizza le lettere del numero esadecimale in minuscolo e anche x e p
printf("[%20a]\n", 456.7895); // [ 0xe.4650e5604189p+5]
// converte in un valore in base ottale senza segno
printf("[%20o]\n", 1000); // [ 1750]
// converte in un valore in base decimale senza segno
printf("[%20u]\n", 1000); // [ 1000]
// converte in un valore in base esadecimale senza segno
printf("[%20x]\n", 1000); // [ 3e8]
// converte un int nel corrispondente carattere
printf("[%20c]\n", 66); // [ B]
// scrive solo i primi 10 caratteri della stringa indicata
printf("[%-20.10s]\n", "Pellegrino Principe"); // [Pellegrino ]
// visualizza l'indirizzo di memoria della stringa indicata
// con anche i caratteri 0x
printf("[%#20p]\n", "C"); // [ 0x40a0d7]
int n_char = 0;
// n_char conterrà il valore 22 perché quando %n sarà utilizzato quelli saranno
// i caratteri fino a quel momento scritti, ossia 2 per le parentesi [ e ] più
// altri 20 pari alla lunghezza del campo specificato nel quale la stringa
// ne prende il posto (essa è lunga 18 caratteri) + altri 2 caratteri di padding (spazio)
printf("[%-20s]%n\n", "Nel mezzo del camm", &n_char); // [Nel mezzo del camm ]
// scrive verbatim il carattere % e in più per fini di allineamento scrive
// 19 caratteri di spazio; 0x20 (decimale 32) è il codice ASCII del carattere di spazio
printf("[%-19c%%]\n", 0x20); // [ %]
Per quanto concerne, invece, le funzioni per l’input formattato possiamo usare quanto segue.
int fscanf(FILE * restrict stream, const char * restrict format, ...): legge dallo stream puntato dastreamquanto indicato dalla stringaformatche specifica le sequenze o i campi di input ammissibili e come debbano essere convertiti per poter essere legittimamente assegnati ai corrispondenti argomenti variabili che devono essere puntatori a oggetti atti a ricevere quegli input convertiti. Ritorna, in caso di successo, il numero di campi di input convertiti e assegnati, e in caso di insuccessoEOF(se un errore di input occorre prima dell’effettuazione della prima conversione). Essa ritorna anche prematuramente se vi è un errore di mancata corrispondenza tra una sequenza di input e la corrispettiva specifica di conversione (in questo caso il valore ritornato può essere0se il primo campo di input non è corrispondente oppure un numero minore rispetto alla quantità di argomenti forniti se solo alcuni campi di input sono stati convertiti rispetto agli altri immessi che hanno invece fallito la corrispondenza).int scanf(const char * restrict format, ...):è equivalente alla funzionefscanfconstdinpassato come argomento al suo parametrostream. Ciò significa chescanfotterrà il suo input dallo stream di input standard che, come già detto, è tipicamente la tastiera.int sscanf(const char * restrict s, const char * restrict format, ...):è equivalente alla funzionefscanfeccetto per il fatto che l’input è ottenuto dalla stringa specificata dall’argomentospiuttosto che da uno stream. Il raggiungimento della fine della stringa è equivalente all’incontrare un end of file per la funzionefscanf.
NOTA
In definitiva le funzioni per l’input formattato
non fanno altro che convertire dei caratteri di input negli
equivalenti valori numerici (per esempio, se da tastiera digitiamo
il numero 124, di fatto stiamo inserendo i caratteri
1, 2 e 4 che unitamente
possono essere convertiti da una funzione come scanf
nell’equivalente valore numerico 124 di tipo
int)
Di tutte le funzioni esaminate il parametro format
è fondamentale, in quanto rappresenta la cosiddetta stringa di
controllo del formato, ossia quella stringa al cui interno
possono essere posti: dei caratteri ordinari, che devono combaciare
esattamente con i corrispondenti caratteri immessi; dei caratteri
di spazio, che non sono ignorati (se vi sono in un certo
punto della stringa di controllo dei caratteri di spazio, tutti i
caratteri di spazio nella corrispondente sequenza di input vengono
letti e scartati); delle specifiche di conversione (Sintassi 11.3)
ognuna delle quali causa la conversione, in accordo con il tipo di
dato indicato, di una sequenza di input corrispondente che è
rappresentata da una stringa di caratteri che non siano spazi e che
si estende fino allo spazio successivo (oppure fino all’ampiezza di
campo eventualmente specificata).
In quest’ultimo caso, eccetto se la specifica di conversione
contiene gli specificatori [...], c o
n, eventuali spazi di input sono scartati; questo
significa che se usiamo una specifica di conversione come
%d con la funzione scanf, allora possiamo
digitare da tastiera anche degli spazi prima o dopo di un numero
intero in notazione decimale perché gli stessi sono semplicemente
non considerati.
Sintassi 11.3 Specifica di conversione.
%[*][field_width][length_modifier]conversion_specifier
Una specifica di conversione inizia con il carattere percento
(%) e può avere, opzionalmente e nell’ordine indicato,
quanto segue.
- Il carattere asterisco
*(assignment-suppressing wide character) consente di ignorare il campo di input corrispondente che è solo letto ma non assegnato al relativo oggetto. Questo campo non farà dunque parte del conteggio ritornato da un funzione di input formattato. field_widthindica l’ampiezza massima di un “campo” che stabilisce il limite del numero di caratteri di un campo di input; ciò implica che la conversione termina quando quel numero di caratteri è raggiunto. Il valore difield_widthdeve essere espresso come un intero decimale maggiore di zero.length_modifierspecifica la dimensione dell’oggetto ricevente il campo di input convertito (Tabella 11.7) asserendo che lo stesso può essere “più piccolo” o “più grande” rispetto a quanto espresso dal relativo specificatore di conversione (per esempio, per uno specificatore di conversione comed, che indica che l’oggetto ricevente è un intero, anteporgli il modificatorehfarà intendere che tale oggetto dovrà invece essere di tiposhort int);length_modifierè dunque un modificatore della lunghezza di un tipo.
| Carattere da usare | Significato |
|---|---|
| hh (da C99) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo signed char * o unsigned char *. |
| h | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo short int * o unsigned short int *. |
| l (elle) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo long int * o unsigned long int *. Per gli specificatori a, A, e, E, f, F, g o G indica che l’argomento deve essere trattato come double *. |
| ll (elle-elle) (da C99) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo long long int * o unsigned long long int *. |
| j (da C99) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo intmax_t * o uintmax_t *1. |
| z (da C99) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo size_t *. |
| t (da C99) | Per gli specificatori d, i, o, u, x, X o n indica che l’argomento deve essere trattato come tipo ptrdiff_t *2. |
| L | Per gli specificatori a, A, e, E, f, F, g o G indica che l’argomento deve essere trattato come tipo long double *. |
1 I tipi intmax_t e
uintmax_t sono definiti nell’header
<stdint.h>. |
|
2 Il tipo ptrdiff_t è
definito nell’header <stddef.h>. |
|
Una specifica di conversione termina, quindi, con
conversion_specifier, che specifica tramite un
apposito carattere (Tabella 11.8) il tipo di conversione da
applicare ossia, detto in altri termini, quale interpretazione dare
al campo di input.
| Carattere da usare | Significato |
|---|---|
| d | Legge un intero in notazione decimale che converte e assegna a un tipo int *. |
| i | Legge un intero in notazione decimale, ottale (preceduto dal carattere 0) o esadecimale (preceduto dai caratteri 0x o 0X) che converte e assegna a un tipo int *. |
| a, A, e, E, f, F, g, G1 | Legge un numero in virgola mobile, espresso anche in notazione esponenziale oppure esponenziale esadecimale che converte e assegna a un tipo float *. |
| o | Legge un intero in notazione ottale (preceduto o meno dal carattere 0) che converte e assegna a un tipo unsigned int *. |
| u | Legge un intero in notazione decimale che converte e assegna a un tipo unsigned int *. |
| x, X | Legge un intero in notazione esadecimale (preceduto o meno dai caratteri 0x o 0X) che converte e assegna a un tipo unsigned int *. |
| c | Legge la quantità di caratteri indicati da
field_width (in assenza legge 1 carattere) che
memorizza in un array di caratteri grande abbastanza per contenere
quella sequenza. Non è aggiunto il carattere nullo ‘\0’ ma è
possibile inserire dei caratteri di spazio. |
| s | Legge una stringa di caratteri senza spazi che memorizza in un
array di caratteri grande abbastanza per contenere quella sequenza
e il carattere nullo ‘\0’, che è aggiunto automaticamente. Se
presente field_width l’array deve essere grande almeno
quanto field_width più il carattere nullo ‘\0’ che
viene aggiunto automaticamente. |
| [...] | Legge una stringa di caratteri non vuota i cui caratteri siano
contenuti in un insieme di caratteri (scanset) specificati
all’interno della coppia di parentesi quadre [ ], che
memorizza in un array di caratteri grande abbastanza per contenere
quella sequenza e il carattere nullo ‘\0’ che è aggiunto
automaticamente. Se questo specificatore è scritto come
[^...] allora i caratteri legittimamente memorizzabili
saranno quelli “non” specificati all’interno della coppia di
parentesi quadre [ ]. |
| p | Legge una sequenza di caratteri che esprimono il valore di un
puntatore, nella stessa forma scritta da fprintf e
%p, che converte e assegna a un tipo void. ** |
| n | L’argomento di tipo int * è utilizzato per memorizzare il
numero di caratteri letti fino a quel momento dall’attuale chiamata
a fscanf. Non legge dati in ingresso e la sua
esecuzione non incrementa il contatore di assegnamenti ritornati
dalla predetta funzione fscanf. |
| % | Legge letteralmente il carattere percento %. Non ha luogo alcuna conversione o assegnamento. |
| 1 a, A e F sono disponibili da C99. | |
Snippet 11.37 scanf e applicazione dei modificatori di lunghezza.
// interpretalo come short int *
short int v1;
printf("Istruzione scanf(\"%%hd\", &v1): ");
scanf("%hd", &v1); // INPUT:99↵ v1 = 99
// interpretalo come long int *
// al massimo 10 caratteri saranno interpretati e convertiti
long int v2;
printf("Istruzione scanf(\"%%10ld\", &v2): ");
scanf("%10ld", &v2); // INPUT:1234567898765↵ v2 = 1234567898
// sopprimi il primo campo di input;
// interpreta poi il secondo campo di input come int *
int v3;
printf("Istruzione scanf(\"%%*f%%d\", &v3): ");
int f = scanf("%*f%d", &v3); // INPUT:22.3 33↵ v3 = 33
ATTENZIONE
Nell’usare la funzione scanf avremo
un comportamento non definito se: vi sono meno argomenti rispetto
alle specifiche di conversione indicate; una specifica di
conversione è invalida; il tipo di un argomento non è di un tipo
corretto così come quello indicato nella corrispondente specifica
di conversione.
Snippet 11.38 scanf e applicazione degli specificatori di conversione.
int res;
// legge un intero in notazione decimale
int v1;
printf("Intero in notazione decimale: ");
res = scanf("%d", &v1); // INPUT:155↵ v1 = 155
// legge un intero in notazione esadecimale
int v2;
printf("Intero in notazione esadecimale: ");
res = scanf("%i", &v2); // INPUT:0x50↵ v2 = 80 (in base 10)
// legge un numero in virgola mobile espresso in notazione esponenziale
float v3;
printf("Float in notazione esponenziale: ");
res = scanf("%f", &v3); // INPUT:-2.32678e2↵ v3 = -232.677994
// legge un intero in notazione ottale
unsigned int v4;
printf("Intero in notazione ottale: ");
res = scanf("%o", &v4); // INPUT:12↵ v4 = 10 (in base 10)
// legge un intero in notazione decimale
unsigned int v5;
printf("Intero in notazione decimale senza segno: ");
res = scanf("%u", &v5); // INPUT:33↵ v4 = 33
// legge un intero in notazione esadecimale
unsigned int v6;
printf("Intero in notazione esadecimale: ");
res = scanf("%X", &v6); // INPUT:A↵ v4 = 10 (in base 10)
// legge una sequenza di 10 caratteri; lo spazio può essere incluso
// lo specificatore %*c permette di ignorare il carattere new line finale che si trova
// nell'input stream e potrebbe interferire con un successivo scanf;
// per esempio, in questo caso, dato che la specifica accetta anche gli spazi, se non
// eliminassimo il new line proprio del precedente scanf, lo stesso si troverebbe come
// carattere in data[0]
char data[10];
printf("Sequenza di 10 caratteri (spazio incluso): ");
res = scanf("%*c%10c", data); // INPUT:risto rant↵
// data = {'r','i','s','t','o',' ','r','a,'n','t'}
// legge una stringa di caratteri; lo spazio non può essere incluso
char data2[10 + 1];
printf("Stringa di caratteri (spazio non incluso): ");
res = scanf("%*c%10s", data2); // INPUT:ristorante↵
// data = {'r','i','s','t','o','r','a','n','t','e','\0'}
// legge una stringa di caratteri che può essere formata solo dai caratteri
// a, e, i, o e u
char vowels_only[10 + 1 ];
printf("Stringa di caratteri tra: [a, e, i, o, u]: ");
res = scanf("%*c%10[aeiou]", vowels_only); // INPUT:aeeiiouooa↵
// vowels_only =
// {'a','e','e','i','i','o','u,'o','o','a','\0'}
// legge una stringa di caratteri che può essere formata solo da caratteri
// che "non" siano a, e, i, o e u
printf("Stringa di caratteri \"non\" tra: [a, e, i, o, u]: ");
char consonants_only[5 + 1 ];
res = scanf("%*c%5[^aeiou]", consonants_only); // INPUT:bcdfg↵
// consonants_only =
// {'b','c','d','f','g','\0'}
// legge un indirizzo di memoria; &add è congruo con quanto atteso da %p come argomento
// perché esso è risolto come un puntatore a un puntatore a void!
void *add;
printf("Indirizzo di memoria: ");
res = scanf("%p", &add); // INPUT 40a0d7↵ add = 0x40a0d7
// legge una stringa di caratteri e ne memorizza i caratteri letti in n_char
// N.B. res conterrà il valore 1 per effetto della conversione della stringa di caratteri
// letta così come dettato dallo specificatore %s
char data3[6 + 1];
int n_char;
printf("Stringa di caratteri (spazio non incluso) per conteggio con %%n: ");
res = scanf("%s%n", data3, &n_char); // INPUT:colore↵
// data3 = {'c','o','l','o','r','e','\0'}
// n_char = 7
// legge due interi in notazione decimale tra i quali deve essere presente
// anche il carattere %
int nr_1, nr_2;
printf("Due interi in notazione decimale \"uniti\" dal carattere %%: ");
res = scanf("%d%%%d", &nr_1, &nr_2); // INPUT 4%6↵ nr_1 = 4 e nr_2 = 6
IMPORTANTE
Nell’eseguire lo Snippet 11.38, per avere un
risultato di corrispondenza corretta tra la sequenza di input e
quanto indicato dalla stringa di controllo del formato per ogni
singolo caso, digitare esattamente quanto riportato da
INPUT:[sequenza]↵, laddove il
simbolo ↵ indica la pressione del tasto Invio. In caso contrario è
utile sapere che se un campo di input non corrisponde a quanto
indicato da una stringa di controllo del formato, allora i
caratteri di quel campo saranno “riutilizzati” per una successiva
operazione di input.
Posizionamento all’interno di file
Quando apriamo un file, il relativo stream associato ha un indicatore di posizione, una sorta di “marcatore” che tiene traccia di dove, all’interno di quel file, avverrà la prossima operazione di lettura o di scrittura.
Normalmente, quando si apre un file per una lettura o per una scrittura, questo indicatore ha un valore impostato al suo inizio (at the beginning); quando si apre, invece, per un’operazione di append, l’indicatore ha un valore impostato alla sua fine (at the end).
In seguito, qualsiasi operazione si effettui con quel file, per esempio una lettura, la stessa avverrà in modo sequenziale, ossia sarà letto un carattere dopo l’altro, e l’indicatore di posizione si aggiornerà, incrementandosi automaticamente.
Le API di I/O della libreria standard, comunque, consentono anche di compiere delle operazioni di lettura o di scrittura all’interno di un file a partire, in modo casuale, da una determinata posizione (in pratica, si può impostare manualmente l’indicatore di posizione in modo che punti dovunque all’interno di un file e a partire da quella posizione effettuare una lettura o una scrittura).
TERMINOLOGIA
I file dove le operazioni di lettura o di scrittura avvengono in modo sequenziale sono detti file ad accesso sequenziale (sequential access files), mentre i file dove le operazioni di lettura o di scrittura avvengono in modo arbitrario sono detti file ad accesso casuale (random access files).
Le funzioni messe a disposizione dalla libreria di I/O per operare in modo arbitrario sulla posizione all’interno di un file sono le seguenti.
int fseek(FILE *stream, long int offset, int whence): imposta l’indicatore di posizione di un file per lo stream puntato dastreamin modo che qualsiasi operazione di lettura o scrittura successiva parta da quella nuova posizione. Se il file è binario, allora la posizione può corrispondere a offset caratteri a partire dawhence, che può essere impostato conSEEK_SET(inizio del file),SEEK_CUR(attuale posizione) oSEEK_END(fine del file). Se il file è di testo, allora la posizione deve corrispondere a offset caratteri conoffsetimpostato o a0ewhenceimpostato aSEEK_SEToSEEK_CURoSEEK_ENDoppure con offset impostato dal valore ritornato daftellewhenceimpostato aSEEK_SET. Ritorna un valore diverso da0solo se la richiesta di posizionamento non può essere soddisfatta.
DETTAGLIO
SEEK_SET, SEEK_CUR e
SEEK_END sono macro semplici dichiarate nell’header
<stdio.h> che si espandono come espressioni
costanti intere con valori tipicamente di 0,
1 e 2.
long int ftell(FILE *stream): ottiene il corrente valore dell’indicatore di posizione di un file per lo stream puntato dastream. Se il file è binario, il valore è il numero di caratteri di offset dall’inizio del file. Se il file è di testo, questo valore è “non specificato” e può essere usato in modo sicuro solo con la funzionefseekpassandolo come argomento al suo parametrooffset, nel qual caso rappresenta il valore dell’indicatore di posizione al tempo in cuiftellstessa è stata invocata. Ritorna il corrente valore dell’indicatore di posizione di un file se la funzione ha successo oppure-1Lin caso di errore.
IMPORTANTE
Nei sistemi dove vi è una differenza tra un file
di testo e un file binario (non è il caso dei sistemi Unix), se
apriamo un file in modalità testo, ftell può ritornare
un valore che non riflette i caratteri effettivi lì contenuti e
questo perché non tutti i sistemi rappresentano un carattere di
nuova riga con un solo carattere (per esempio '\n' per
new line); infatti, in quest’ultimo caso, i caratteri fisici
effettivamente usati possono essere differenti (per esempio, nei
sistemi Windows, ogni nuova riga è codificata con i caratteri
'\r' per il carriage return e '\n' per il
new line). Ecco quindi che il semplice meccanismo del modello di
I/O di Unix che prevede un’indicizzazione per numero di caratteri
non può essere supportato in modo consistente per i file di testo
tra diversi sistemi. Per lo standard, quindi, ftell
deve avere per i file di testo solo il seguente comportamento: deve
ritornare la corrente posizione nel file (che ribadiamo è un valore
dipendente da come il corrente sistema interpreta un file di testo;
è una sorta cioè di magic number), la quale è usabile solo
per far riposizionare il file in quella corrente locazione. La
funzione ftell non deve dunque avere nessun’altra
interpretazione eccetto quella di far spostare con
fseek il puntatore di posizionamento nello stesso
posto di quello da essa precedentemente ritornato. In
questo modo ogni implementazione per uno specifico sistema può
codificare le informazioni di posizionamento in un file di testo
nel modo che ritiene più opportuno e appropriato, a condizione però
che quell’informazione sia sempre rappresentabile nel tipo
long.
void rewind(FILE *stream)imposta l’indicatore di posizione di un file per lo stream puntato dastreamall’inizio del relativo file. In effetti questa funzione ha la stessa semantica dell’invocazione di(void)fseek(stream, 0L, SEEK_SET)e non ritorna nulla.int fgetpos(FILE * restrict stream, fpos_t * restrict pos)memorizza, nell’oggetto puntato dapos, il corrente valore dell’indicatore di posizione di un file per lo stream puntato dastream. Ritorna0in caso di successo, un valore diverso da0in caso di fallimento.int fsetpos(FILE *stream, const fpos_t *pos)imposta l’indicatore di posizione di un file per lo stream puntato dastreamcon il valore dell’oggetto puntato daposche deve essere quello fornito da una precedente invocazione difgetpos. Ritorna0in caso di successo, un valore diverso da0in caso di fallimento.
DETTAGLIO
Le funzioni fgetpos e
fsetpos sono nate per consentire di lavorare con file
di notevoli dimensioni laddove il relativo valore di posizionamento
è astratto in un tipo di dato, fpos_t (file
position type), capace di contenere quel valori e a superare,
quindi, il limite proprio delle funzioni fseek e
ftell, che consentono invece di gestire valori di
posizionamento contenibili solamente in un tipo long
(il parametro offset è infatti di quel tipo). Il tipo
fpos_t evidenziato è dipendente da un’implementazione,
ossia la sua rappresentazione interna può variare da sistema a
sistema. Per esempio, nella libreria glibc, fpos_t è
definito come un typedef di una struttura che ha due
membri uno dei quali, __pos di tipo
__off_t, è quello deputato a gestire informazioni sul
posizionamento in un file di notevoli dimensioni.
Snippet 11.39 fseek e ftell.
...
#define FILE_NAME "letters"
int main(void)
{
// apre il file in modalità binaria in modo che fseek e ftell siano utilizzabili
// senza problemi di differenze tra sistemi diversi
// il file contiene i seguenti caratteri:
// ABCDEFGHIJKLMNOPQRSTUVWXYZ
FILE *file = fopen(FILE_NAME, "rb");
if (file)
{
// sposta l'indicatore di posizione del file letters di 8 byte "in avanti"
// inizia a contare 8 byte dopo il byte 0 iniziale
fseek(file, 8L, SEEK_SET);
long int pos = ftell(file); // 8, ossia 8 byte a partire dall'inizio del file
putchar(fgetc(file)); // stampa la lettera I
// sposta l'indicatore di posizione del file letters di 5 byte
// dopo la corrente posizione
fseek(file, 5L, SEEK_CUR);
pos = ftell(file); // 14, ossia 14 byte a partire dall'inizio del file
putchar(fgetc(file)); // stampa la lettera O
// sposta l'indicatore di posizione del file letters di 3 byte "all'indietro"
// inizia a contare 3 byte non dall'ultimo byte ma da quello prima di esso;
// possiamo anche dire: sposta l'indicatore al terzo byte prima della fine
// del file oppure ancora: se il file è di 26 caratteri allora sposta
// l'indicatore in base al risultato di 26 - 3 che è 23; sposta quindi
// l'indicatore di 23 caratteri dopo il primo
fseek(file, -3L, SEEK_END);
pos = ftell(file); // 23, ossia 23 byte a partire dall'inizio del file
putchar(fgetc(file)); // stampa la lettera X
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
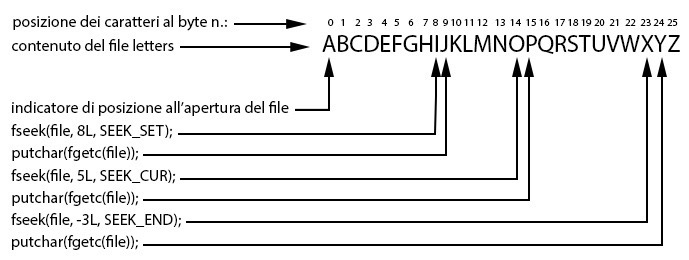
Figura 11.6 Stato di avanzamento dell’indicatore di posizione del file letters come da Snippet 11.39.
NOTA
Ogni invocazione di fgetc sposta
automaticamente in avanti, di un carattere, l’indicatore di
posizione del file letters.
Gestione degli errori
Delle funzioni di I/O sin qui esaminate, quando vi sono degli
errori, alcune ritornano un’indicazione di EOF mentre
altre ritornano un errore di lettura o di scrittura.
Quando vi sono le condizioni di anomalie descritte, vengono
attivati degli indicatori di stato, di cui uno è un indicatore per
gli EOF, mentre l’altro è un indicatore per gli errori
di lettura o di scrittura.
Per distinguere quale tipologia di anomalia una funzione di I/O ha sollevato possiamo usare una delle due seguenti funzioni.
int feof(FILE *stream):verifica l’indicatore diEOFper lo stream puntato dastream. Ritorna un valore diverso da0se e solo se l’indicatore diEOFè impostato perstream.int ferror(FILE *stream): verifica l’indicatore di errore per lo stream puntato dastream. Ritorna un valore diverso da0se e solo se l’indicatore di errore è impostato perstream.
Snippet 11.40 ferror e feof.
...
#define FILE_NAME "letters"
#define SIZE 8
int main(void)
{
int c_nr = 0;
FILE *file = fopen(FILE_NAME, "r");
if (file)
{
while (fgetc(file) != EOF) // scorro letters carattere per carattere
c_nr++;
if (ferror(file))
printf("[ERRORE DI LETTURA]\n");
else if (feof(file)) // se EOF allora il conteggio dei caratteri è completo!
printf("Il file letters contiene %d caratteri\n", c_nr);
fclose(file);
}
else
printf("%s [ERRORE DI APERTURA]\n", FILE_NAME);
...
}
La funzione seguente, invece, consente di resettare
esplicitamente gli indicatori EOF e di errore:
void clearerr(FILE *stream): cancella l’indicatore diEOFe di errore per lo stream puntato dastream. Non ritorna nulla.
Utility generali: <stdlib.h>
L’header <stdlib.h> definisce cinque macro,
dichiara cinque tipi e una serie di funzioni di utilità generale
categorizzate come segue: funzioni per le conversioni
numeriche; funzioni per la generazione di sequenze
pseudo-casuali; funzioni per la gestione della
memoria; comunicazione con l’ambiente; utilità
per la ricerca e l’ordinamento; funzioni per l’aritmetica
intera; funzioni di conversione tra caratteri multibyte e
caratteri estesi; funzioni di conversione tra stringhe
multibyte e stringhe estese.
Per le macro abbiamo: NULL indica una costante di
tipo puntatore nullo; EXIT_FAILURE si espande in
un’espressione costante intera il cui valore, tipicamente
1, è usabile come argomento della funzione
exit per riportare all’ambiente di esecuzione uno
status di terminazione non corretto di un programma;
EXIT_SUCCESS si espande in un’espressione costante
intera il cui valore, tipicamente 0, è usabile come
argomento della funzione exit per riportare
all’ambiente di esecuzione uno status di terminazione corretta di
un programma; RAND_MAX si espande in un’espressione
costante intera il cui valore è il valore massimo ritornato dalla
funzione rand; MB_CUR_MAX si espande in
un’espressione intera di tipo size_t il cui valore è
il massimo numero di byte in un carattere multibyte di un set di
caratteri estesi del corrente sistema di localizzazione.
Per i tipi abbiamo: div_t è il tipo del valore
ritornato dalla funzione div; ldiv_t è il
tipo del valore ritornato dalla funzione ldiv;
lldiv_t è il tipo del valore ritornato dalla funzione
lldiv; size_t è il tipo del risultato
dell’operatore sizeof; wchar_t è il tipo
utilizzato per la rappresentazione dei caratteri estesi, ossia è
quel tipo impiegabile per memorizzare i codici di tutti i membri
del più grande set di caratteri esteso supportato dalla corrente
implementazione.
NOTA
Le funzioni div, ldiv e
lldiv sono dichiarate anche nell’header
<stdlib.h> e fanno parte della categoria
funzioni per l’aritmetica intera.
Gestione della memoria
Il linguaggio C supporta nativamente le due seguenti modalità o tipologie di allocazione della memoria laddove, in senso generico, per allocazione si intende quel procedimento di assegnazione di un blocco di memoria RAM a un programma.
- Allocazione statica: utilizzata per memorizzare le
variabili esterne (o globali) e le variabili statiche. Queste
variabili rappresentano dei blocchi di memoria di dimensioni fisse
che vengono allocati quando il programma si avvia e vengono
deallocati quando il programma si conclude. Il valore di queste
variabili è pertanto mantenuto per tutta la durata di un programma.
In questo tipo di allocazione la dimensione del blocco di memoria
non è modificabile a run-time (è conosciuta cioè solo a
compile-time), e lo stesso blocco non è programmaticamente
rilasciabile e assegnabile per altre allocazioni. Si pensi, per
esempio, alla classica dichiarazione di un array come
int data[6];dove, in questo caso, a compile-time viene fissata la sua dimensione pari a 6 elementi di tipointche non può poi essere cambiata, in aumento o in diminuzione, durante l’esecuzione del programma (a run-time). In questo caso l’area di memoria utilizzata dall’allocazione statica è conosciuta con il termine di data segment (segmento dati). - Allocazione automatica: utilizzata per memorizzare le variabili automatiche (i parametri formali di una funzione, le variabili locali a una funzione o a un più generico blocco di codice). Queste variabili rappresentano dei blocchi di memoria di dimensioni fisse che vengono allocati quando il flusso di esecuzione del codice “entra” in una funzione o in un qualsiasi generico blocco di codice e vengono deallocati quando il flusso di esecuzione del codice “esce” da una funzione o da un qualsiasi generico blocco di codice. Il valore di queste variabili è pertanto mantenuto per la sola durata della funzione o del blocco di codice. In questo tipo di allocazione la dimensione del blocco di memoria non è modificabile a run-time (è conosciuta cioè solo a compile-time) e lo stesso blocco non è programmaticamente rilasciabile e assegnabile per altre allocazioni. In questo caso l’area di memoria utilizzata dall’allocazione automatica è conosciuta con il termine di stack (pila).
Le due modalità di allocazione predefinite della memoria, quantunque semplici, immediate e “automatiche”, sono però impiegabili con una certa utilità solo quando un programma non ha necessità di creazione e utilizzo di oggetti di dimensioni variabili, ossia di oggetti la cui dimensione non è già nota a compile-time e che può crescere o diminuire durante l’esecuzione del programma.
Ecco quindi che in C, per fronteggiare tale limitazione, è
possibile usare un terzo tipo di allocazione della memoria,
definito allocazione dinamica, che non è built-in nel
linguaggio ma che è impiegabile attraverso l’utilizzo di apposite
funzioni dichiarate nell’header <stdlib.h>.
In linea generale, quindi, l’allocazione dinamica della memoria è una tecnica di allocazione della memoria per effetto della quale, in modo esplicito e, per C con l’ausilio di funzioni ad hoc, un programmatore richiede al sistema di fornirgli un blocco di memoria la cui dimensione è variabile e può anche mutare a run-time durante l’esecuzione di un programma.
TERMINOLOGIA
L’area di memoria utilizzata dall’allocazione dinamica è conosciuta con il termine di heap (mucchio).
Nel contempo, dato che l’allocazione dinamica è
programmaticamente utilizzata, anche la fase di deallocazione del
relativo blocco è un procedimento che un programmatore deve
compiere manualmente; infatti, in C, dovrà usare un’apposita
funzione di freeing dello storage sempre dichiarata
nell’header <stdlib.h>.
Vediamo ora quali sono le funzioni che la libreria standard del linguaggio C mette a disposizione per gestire l’allocazione dinamica della memoria.
void *malloc(size_t size): alloca spazio di storage per un oggetto di dimensione pari ai byte esplicitati dasizeil cui valore è però indeterminato, ossia il contenuto di tale area di memoria contiene valori garbage. Ritorna, in caso di fallimento, un puntatore nullo, e in caso di successo un puntatore generico allo spazio allocato.void *calloc(size_t nmemb, size_t size): alloca spazio di storage per un array dinmembelementi, ciascuno dei quali di dimensione pari ai byte esplicitati dasize. Il contenuto di tale area di memoria è inizializzato con byte nulli (tutti i bit a 0). Ritorna, in caso di fallimento, un puntatore nullo, e in caso di successo un puntatore generico allo spazio allocato.void *realloc(void *ptr, size_t size): dealloca il vecchio oggetto puntato daptre ritorna un puntatore a un nuovo oggetto di dimensione pari ai byte indicati dasize. Il contenuto del vecchio oggetto sarà preservato fino alla dimensione minima tra quella vecchia e quella nuova. Se la nuova dimensione è maggiore della vecchia, quei byte aggiuntivi avranno un valore indeterminato. In questo casoreallocpuò usare, ridimensionandola, la stessa area di memoria del vecchio oggetto se i successivi byte occorrenti non sono in uso, oppure può usare una nuova area di memoria nella quale copierà, preliminarmente, tutti i byte del vecchio oggetto con i valori lì contenuti. Per quanto riguarda l’argomento fornito aptr, esso potrà essere un valido puntatore così come ritornato damalloc,callocoreallocstesso, ma anche un puntatore nullo nel qual casoreallocsi comporterà comemalloc. Ritorna, in caso di fallimento, un puntatore nullo e il vecchio oggetto non è deallocato e i dati lì contenuti rimangono inalterati; in caso di successo, ritorna un puntatore generico a nuovo oggetto che può avere anche lo stesso valore del puntatore del vecchio oggetto.void free(void *ptr): dealloca lo spazio puntato daptrrendendolo disponibile per future allocazioni. Septrè un puntatore nullo non accade niente, altrimenti septrnon è un valido puntatore così come ritornato damalloc,callocorealloc, il comportamento non è definito. Non ritorna alcun valore.
ATTENZIONE
È fondamentale usare sempre la funzione
free per deallocare un blocco di memoria
precedentemente allocato con malloc,
calloc o realloc e ciò per non incorrere
in problemi di memory leak (perdita di memoria) che si
hanno se dei blocchi di memoria precedentemente allocati non sono
più accessibili e dunque deallocabili (C non ha infatti un sistema
software detto garbage collector come altri linguaggi,
tipo Java o C#, che provvede in automatico a localizzare blocchi di
memoria non più riferiti e a deallocarli di conseguenza recuperando
così quella preziosa memoria). I memory leak sono piuttosto gravi
perché possono portare, nei casi limite, all’esaurimento della
memoria disponibile, e con ciò compromettere il corretto
funzionamento di un programma oppure terminarlo in modo
anomalo.
TERMINOLOGIA
Anche se usiamo in modo accorto la funzione
free bisogna fare comunque attenzione a non utilizzare
successivamente all’operazione di deallocazione il puntatore
relativo (per esempio per accedere o modificare quell’area di
memoria in precedenza riferita). In caso contrario, se usiamo il
puntatore dopo averlo deallocato come free esso
diverrà un dangling pointer (puntatore pendente), ovvero
un puntatore che non punterà più a un valido blocco di memoria, e
ciò causerà comportamenti non definiti in caso di un suo
utilizzo.
Snippet 11.41 malloc, calloc, realloc e free.
// allochiamo un blocco di memoria di 6 byte dove i primi 5 byte conterranno dei caratteri
// propri di una stringa mentre l'ultimo byte conterrà il carattere nullo '\0';
// in questo caso non è stato necessario usare sizeof(char) perché la specifica
// stabilisce che sizeof(char) deve essere sempre pari a 1 (byte);
// è anche importante notare come il risultato di tipo void * ritornato da malloc
// non sia convertito in char *; ciò perché tale conversione è fatta in automatico dal
// compilatore durante la fase di assegnamento;
// per chiarezza, comunque, spesso, molti programmatori preferiscono esplicitarla:
// per esempio: char *string = (char *) malloc(nr_char + 1);
size_t nr_char = 5;
char *string = malloc(nr_char + 1); // string punterà al primo byte del blocco di memoria
// ritornato da malloc
if (string) // se l'allocazione ha avuto esito favorevole...
strcpy(string, "Pelle"); // ... inizializzo i byte del blocco di memoria
// ritornato da malloc
// allochiamo un blocco di memoria capace di contenere 10 elementi di tipo int;
// se nell'attuale implementazione un int è di 4 byte, allora il blocco di memoria
// ritornato da calloc sarà di 40 byte
size_t nr_elem = 10;
int *data = calloc(nr_elem, sizeof (int)); // tutti gli elementi di data conterranno
// il valore 0
if (data) // aumentiamo la dimensione di data del doppio!
{
int *tmp = realloc(data, sizeof (int) * (nr_elem * 2));
// in questo caso è importante usare un puntatore temporaneo per realloc al fine di
// evitare dei memory leak in caso realloc torni un puntatore nullo e lo stesso sia
// assegnato direttamente a data
if (tmp)
data = tmp;
}
int val1 = data[0]; // 0
int val2 = data[10]; // qualsiasi valore perché l'aumento di dimensione causato da
// realloc non ha anche inizializzato quei byte in più
// liberiamo la memoria
free(string);
free(data);
Snippet 11.42 Memory leak e dangling pointer.
// p_1 punta a un blocco di memoria di 40 byte (se int di 4 byte)
int *p_1 = malloc(10 * sizeof(int)); // indirizzo 0x770dc0
// p_2 punta a un blocco di memoria di 20 byte (se int di 4 byte)
int *p_2 = malloc(5 * sizeof(int)); // indirizzo 0x770e00
// ora p_1 punta allo stesso blocco puntato da p_2;
// abbiamo un memory leak perché il blocco di memoria originario puntato da p_1 non è
// più referenziabile e dunque deallocabile con free
p_1 = p_2; // indirizzo 0x770e00
free(p_1);
// non necessario free(p_2) perché entrambi puntano allo stesso blocco di memoria
// p_1 è un dangling pointer; l'area di memoria da esso riferita non è più valida
// e pertanto accedere a essa in modifica è un grave errore e può portare a
// comportamenti non definiti
*p_1 = 100; // ATTENZIONE!!!
IMPORTANTE
In ambiente GNU/Linux è possibile usare il
potente tool Valgrind che, tra le altre cose, consente di rilevare
potenziali problemi di gestione della memoria. Se, infatti,
lanciamo il comando valgrind con l’eseguibile dello
Snippet 11.42, avremo in output quanto evidenziato dalla Figura
11.7, dove viene rilevato l’utilizzo di un dangling pointer
(*p_1 = 100) e anche il memory leak per effetto
dell’assegnamento di p_2 a p_1.
Tutti gli altri header
Per ragioni di spazio non è purtroppo possibile illustrare in dettaglio tutte le funzionalità degli altri file header presenti nella libreria standard del linguaggio C (lo abbiamo fatto solo per quelle che sono utilizzate con più frequenza). Pertanto ci limiteremo a fornire solo una breve descrizione degli stessi ricordando al lettore che in caso volesse approfondirne gli aspetti può farlo consultando sia la Grundnorm del linguaggio, ossia il documento di specifica di C11 (Capitolo 7 e Allegato B), sia altre autorevoli fonti come è quella della libreria glibc.
Figura 11.7 Report di Valgrind per i problemi di memoria di cui lo Snippet 11.42.
In definitiva, da un certo punto di vista, quello che davvero conta per programmare proficuamente in C è l’acquisizione di un solido e profondo background teorico/pratico sui suoi fondamenti e costrutti; dopodiché sarà sempre possibile consultare sia una qualsiasi guida rigorosa e corretta sulle API standard della libreria di C per scrivere programmi compatibili tra più piattaforme sia le guide di API di altre librerie che consentono di programmare GUI, networking, database e così via, per scrivere programmi specialistici di determinate piattaforme.
Diagnostica <assert.h>
L’header <assert.h>, utilizzato per fini di
debugging del codice, definisce le macro assert e
static_assert. La macro assert, definita
come una macro parametrica, stampa su stderr delle
informazioni diagnostiche, se la sua espressione da verificare è
falsa (vale 0), e poi invoca la funzione
abort (dichiarata nel file header
<stdlib.h>) che causa la terminazione anomala
del corrente programma.
Snippet 11.43 <assert.h>.
FILE *file = fopen("test", "r");
// se il file esiste fa qualcosa con il resto del codice, altrimenti stampa qualcosa
// in un formato dipendente dalla corrente implementazione che potrebbe essere
// simile al seguente:
// Assertion failed: expression, function abc, file xyz, line nnn.
assert(file != NULL);
NOTA
Se prima dell’inclusione di
<assert.h> si definisce la macro
NDEBUG (sta per no debug), allora qualsiasi
invocazione di assert nell’ambito del codice non avrà
effetto (sarà disattivata). Ciò è utile perché consente di
usare degli assert durante la fase di test di un
programma e poi, piuttosto che eliminarli dal codice, disattivarli
semplicemente quando il programma deve essere rilasciato. In
seguito, nel caso vi fosse la rilevazione di ulteriori errori o
bug, sarà sempre possibile riattivare gli assert
presenti nel codice sorgente rimuovendo la macro
NDEBUG.
La macro semplice static_assert, invece, si espande
in _Static_assert la quale, ricordiamo, è una nuova
keyword introdotta dallo standard C11 per scrivere asserzioni
statiche (si veda il Capitolo 9).
Aritmetica complessa <complex.h> (C99)
L’header <complex.h> definisce una serie di
macro e dichiara svariate funzioni che consentono di svolgere
operazioni con i numeri complessi. Sono raggruppate in:
funzioni trigonometriche, funzioni iperboliche,
funzioni esponenziali e logaritmiche, funzioni per le
potenze e il valore assoluto e funzioni di
manipolazione.
Eccetto per quelle di manipolazione, le altre funzioni citate
sono le equivalenti, laddove previsto, delle funzioni dichiarate
nell’header <math.h> con la differenza, però,
che operano con i tipi complessi e che sono prefisse dal carattere
c.
Così, per esempio, le funzioni cos,
sin, exp, log e così via,
proprie dell’header <math.h>, sono dichiarate
nell’header <complex.h> come ccos,
csin, cexp, clog e così
via.
In più, ognuna delle funzioni dichiarate nell’header
<complex.h> è scritta in tre versioni a
seconda se utilizza il tipo float complex (il suo nome
terminerà con il suffisso f), il tipo double
complex o il tipo long double complex (il suo
nome terminerà con il suffisso l).
Per esempio, la funzione che computerà il coseno di un argomento
di un tipo complesso avrà i seguenti tre prototipi: double
complex ccos(double complex z); float complex
ccosf(float complex z); long double complex ccosl(long
double complex z).
Per quanto riguarda le macro abbiamo: complex, che
si espande in _Complex; _Complex_I, che
si espande in un’espressione costante di tipo const float
_Complex con valore la parte immaginaria;
imaginary, che si espande in _Imaginary;
_Imaginary_I, che si espande in un’espressione
costante di tipo const float _Imaginary con valore la
parte immaginaria; la macro I, che si espande in
_Imaginary_I oppure, se quest’ultima non è definita,
in _Complex_I.
Snippet 11.44 <complex.h>.
double complex c_number = 5.2 + 1.4 * I;
// usa le funzioni creal e cimag appartenenti alla gruppo delle funzioni di manipolazione
// che permettono di estrarre da un numero complesso la parte reale
// e la parte immaginaria
printf("c_number = %.1f + %.1fi\n", creal(c_number), cimag(c_number)); // c_number =
// 5.2 + 1.4i
NOTA
In questo header è anche illustrato il
comportamento della direttiva #pragma STDC
CX_LIMITED_RANGE la quale, se impostata su ON,
informa la corrente implementazione che le operazioni di
moltiplicazione, divisione e valore assoluto con i numeri complessi
useranno solo operandi che non esprimeranno valori infiniti, e che
non vi dovrà essere la necessità di gestire casi di overflow o di
underflow. Nel momento in cui vengono scritte queste righe sia GCC
che MinGW non supportano ancora tale direttiva.
Errori <errno.h>
L’header <errno.h> definisce le macro
EDOM, EILSEQ, ERANGE ed
errno che riportano un valore che indica l’eventuale
accadimento di situazioni di errore causate dall’invocazione e
utilizzo di alcune funzioni della libreria standard del linguaggio
C.
Le macro EDOM, EILSEQ ed
ERANGE si espandono in un’espressione costante intera
di tipo int il cui valore è un codice di errore che,
rispettivamente, segnala: un errore di dominio (generato, per
esempio, dalle funzioni dell’header <math.h>
quando il valore di un argomento passato è al di fuori dal dominio
di definizione della relativa funzione; si pensi al passaggio di un
valore negativo come -1 alla funzione
sqrt); un errore nell’intervallo di valori (generato,
per esempio, dalle funzioni dell’header <math.h>
quando il risultato matematico ottenuto non può essere
rappresentato nel tipo di ritorno perché troppo grande
[overflow] oppure perché troppo piccolo
[underflow]; si pensi all’uso della funzione
pow dove si vuole computare 5000 elevato
alla potenza di 10000); un errore di codifica
(generato, per esempio, dalle funzioni dell’header
<wchar.h> quando una sequenza di caratteri non
forma una valida rappresentazione di caratteri multibyte; si pensi
all’uso della funzione di conversione mbsrtowcs la cui
sequenza di caratteri fornita non può essere interpretata, nel
sistema di codifica utilizzato, come una valida sequenza di
caratteri multibyte e dunque convertita nella corrispondente
sequenza di caratteri estesi).
La macro errno, invece, si espande in un lvalue
modificabile di tipo int, che ha valore 0
all’avvio di un programma, ed è impiegata da diverse funzioni della
libreria standard per memorizzare un codice di errore (un numero
intero positivo) in caso l’utilizzo di una di esse non abbia avuto
esito favorevole.
NOTA
Ogni implementazione può definire innumerevoli
altre macro che riportano ulteriori situazioni di errore.
Consultare a tal fine l’header <errno.h>.
Snippet 11.45 <errno.h>.
double res = sqrt(-1); // ora errno == EDOM
// perror è una funzione dichiarata nel file header <stdio.h> che visualizza la stringa
// fornita come argomento e anche un'altra sequenza di caratteri che rappresenta la
// descrizione testuale dell'errore associato al codice numerico di errore
// contenuto in errno;
// ogni implementazione definisce un messaggio testuale di errore
// per il relativo codice numerico di errore;
// perror scrive il suo output nello stderr e pone anche un carattere di new line
if (errno != 0)
perror("EDOM"); // EDOM: Domain error
// reinizializziamo errno a 0 perché le funzioni che lo usano non lo fanno
// in automatico dopo averlo impostato con un codice di errore
errno = 0;
res = pow(5000, 10000); // ora errno == ERANGE
if (errno != 0)
perror("ERANGE"); // ERANGE: Result too large
// in questo caso con GCC è definita anche la macro ENOENT che ha la descrizione
// No such file or directory
errno = 0;
FILE *file = fopen("no_file", "r"); // ora errno == ENOENT
if (errno == ENOENT) // altro modo di rilevare un tipo eventuale di errore
perror("ENOENT"); // ENOENT: No such file or directory
Ambiente in virgola mobile <fenv.h> (C99)
L’header <fenv.h> definisce diverse macro e
dichiara dei tipi e delle funzioni che consentono di accedere
all’ambiente in virgola mobile, rappresentato da flag di stato
(floating-point status flag) e modi di controllo
(floating-point control modes) così come sono supportati
dalla corrente implementazione.
Un flag di stato è rappresentato da una variabile di tipo
fexcept_t il cui è valore è impostato quando
un’eccezione di tipo overflow, underflow,
division by zero, invalid operation o
inexat è sollevata (o sono sollevate) in virtù del
compimento di operazioni che riguardano l’aritmetica in virgola
mobile.
Ognuna delle eccezioni indicate ha delle corrispondenti macro
semplici denominate FE_OVERFLOW,
FE_UNDERFLOW, FE_DIVBYZERO,
FE_INVALID e FE_INEXACT che si espandono
in espressioni costanti intere i cui valori possono anche essere
combinati con l’operatore bitwise inclusive OR
| per rappresentare più eccezioni simultaneamente (è
anche prevista la macro FE_ALL_EXCEPT il cui valore è
un bitwise OR di tutti i valori delle macro delle eccezioni
indicate e di altre eventuali macro di eccezioni che
un’implementazione ha ritenuto opportuno definire).
Un modo di controllo è rappresentato da una variabile che può essere impostata programmaticamente per cambiare il comportamento di certe operazioni in virgola mobile come, per esempio, quelle che possono esprimere dei risultati con dei valori arrotondati.
Le seguenti macro semplici permettono infatti di controllare o
di scegliere la direzione di un arrotondamento tra:
round toward nearest (FE_TONEAREST),
round toward zero (FE_TOWARDZERO), round
toward positive infinity (FE_UPWARD) e round
toward negative infinity (FE_DOWNWARD). I valori
di queste macro si espandono in espressioni costanti intere i cui
valori sono distinti e non negativi.
Per quanto riguarda le funzioni esse sono categorizzate come
segue: funzioni per le eccezioni in virgola mobile
(fegetexceptflag, feraiseexcept,
fesetexceptflag e così via); funzioni per gli
arrotondamenti (fegetround e
fesetround); funzioni per la gestione
dell’ambiente in virgola mobile (fegetenv,
fesetenv e così via). Per queste ultime funzioni è
utilizzato un parametro di tipo fenv_t che tipicamente
è un typedef di una struttura deputata a rappresentare
tutto l’ambiente in virgola mobile.
Snippet 11.46 <fenv.h>.
...
// esplicita al compilatore la volontà di operare con l'ambiente in virgola mobile;
// ciò è utile perché indica al compilatore che certe ottimizzazioni non dovrebbero
// essere fatte quando questa modalità è ON
#pragma STDC FENV_ACCESS ON
int main(void)
{
double res = 4.0 / 0.0; // FE_DIVBYZERO
// verifica se è occorsa l'eccezione indicata
if (fetestexcept(FE_DIVBYZERO))
printf("division by zero sollevata.\n"); // division by zero
// simula un'eccezione sollevandola
int ret = feraiseexcept(FE_OVERFLOW | FE_INVALID);
if (ret == 0) // ok eccezioni sollevate
{
int which = fetestexcept(FE_OVERFLOW | FE_INVALID);
// mostra un altro modo di testare le eccezioni sollevate...
if (which & (FE_OVERFLOW | FE_INVALID))
printf("overflow e invalid operation sollevate.\n"); // division by zero
}
// imposta il metodo di arrotondamento come "round toward positive infinity"
// in questo caso la funzione rint ritorna come valore arrotondato 3 e non 2;
// rint è dichiarata nell'header <math.h> e arrotonda il suo argomento in base
// al corrente modo di arrotondamento
fesetround(FE_UPWARD);
double v = rint(2.3); // 3
...
}
NOTA
Nel momento in cui vengono scritte queste righe,
il compilatore in uso (GCC 4.9.2) non supporta ancora la direttiva
#pragma STDC FENV_ACCESS.
Caratteristiche dei tipi in virgola mobile <float.h>
L’header <float.h> definisce molteplici macro
che danno indicazioni sui limiti dei tipi in virgola mobile
(precisione, range e così via). Tranne che per le macro
DECIMAL_DIG, FLT_EVAL_METHOD,
FLT_RADIX, e FLT_ROUNDS che si applicano
a tutti i tipi in virgola mobile, le altre macro iniziano con i
prefissi FLT, DBL o LDBL a
seconda se si applicano, rispettivamente, ai tipi
float, double o long double
(in più, tutte le macro si espandono in espressioni costanti,
eccetto FLT_ROUNDS, che può cambiare valore a runtime
per effetto della funzione fesetround dichiarata
nell’header <fenv.h>).
NOTA
Nell’header <float.h> non sono
dichiarati tipi o funzioni.
Snippet 11.47 <float.h>.
// risultato di una serie di macro nella corrente implementazione (GCC)
// consultare l'header <float.h> per un elenco completo di tutte la macro presenti
printf("Valore minimo di un float: %e\n", FLT_MIN); // Valore minimo di un float:
// 1.175494e-038
printf("Valore massimo di un double: %e\n", DBL_MAX); // Valore massimo di un double:
// 1.797693e+308
printf("Numero di cifre significative: %d\n", LDBL_DIG); // Numero di cifre
// significative: 18
Conversione di formato dei tipi interi <inttypes.h> (C99)
L’header <inttypes.h> include l’header
<stdint.h> (definisce dei tipi interi con una
specifica ampiezza di bit) e definisce una serie di macro che
consentono di fornire degli specificatori di conversione
“portabili” alle funzioni per l’input e l’output formattato (per
esempio per printf e scanf) che
utilizzano i tipi definiti nel citato header
<stdint.h>.
Le macro definite nell’header <inttypes.h> si
espandono in letterali stringa, ciascuno contenente i caratteri
propri di un determinato specificatore di conversione ed
eventualmente di un modificatore di ampiezza, usabili con il
corrispondente tipo intero definito nell’header
<stdint.h>.
L’identificatore di tali macro ha la seguente generica forma di
denominazione: inizia con i caratteri PRI (se la macro
è usabile con le funzioni per l’output formattato tipo
printf) o SCN (se la macro è usabile con
le funzioni per l’input formattato tipo scanf), i
quali sono seguiti da uno specificatore di conversione
(d o i per i tipi interi con segno,
o, u, x o X per
i tipi interi senza segno), il quale è seguito da dei caratteri, in
maiuscolo, che corrispondono al nome di un tipo similare definito
nell’header <stdint.h> senza, però, il nome del
tipo e il suffisso _t.
Così, per esempio, i tipi int32_t e
int_least32_t definiti nell’header
<stdint.h> hanno le corrispondenti macro
denominate PRId32 (e SCNd32) e
PRIdleast32 (e SCNdleast32) definite
nell’header <inttypes.h>.
Snippet 11.48 <inttypes.h>.
// questo valore sarà garantito in modo portabile su piattaforme diverse
int32_t i32 = 2000000000;
// il valore di i32 sarà stampato in modo portabile su piattaforme diverse:
// per esempio, in un sistema a 32 bit la macro PRId32 potrà essere espansa come "d"
// in un sistema a 16 bit la macro PRId32 potrà essere espansa come "ld"
printf("Valore di i32 [%" PRId32 "]\n", i32); // Valore di i32 [2000000000]
Grafie alternative <iso646.h> (C95)
L’header <iso646.h> definisce delle macro che
si espandono in token rappresentanti degli operatori singoli del
linguaggio C oppure delle loro combinazioni (Tabella 11.9).
In sostanza questo file header consente di sopperire
all’eventuale mancanza dei tasti di una tastiera che permettono, se
presenti, di inserire con facilità i caratteri &,
|, ~, ! o
^.
DETTAGLIO
Il nome di questo header deriva dallo standard
ISO/IEC 646 del 1983 (la più recente revisione è del 1991) che
specifica un set di caratteri a 7 bit costituito da insieme di 128
caratteri (di controllo, lettere, cifre e simboli) e la loro
equivalente codifica. Esso ha anche delle varianti nazionali (tipo
l’ISO 646-IT per la variante Italiana), alcune delle quali usano
dei caratteri propri (tipo à, codice 7B)
al posto di alcuni simboli utilizzabili in C (tipo {,
codice 7B).
| Nome macro | Token espanso |
|---|---|
and |
&& |
and_eq |
&= |
bitand |
& |
bitor |
| |
compl |
~ |
not |
! |
not_eq |
!= |
or |
|| |
or_eq |
|= |
xor |
^ |
xor_eq |
^= |
Anche se non direttamente collegato a questo header è qui importante rammentare che in C è possibile usare anche delle apposite sequenze di tre caratteri, dette trigraph (Tabella 11.10) o di due caratteri, dette digraph (digrammi, Tabella 11.11), che si riferiscono a dei caratteri che potrebbero non essere presenti in determinate tastiere, con ciò consentendone comunque un inserimento anche se indiretto.
| Sequenza | Carattere equivalente |
|---|---|
??= |
# |
??( |
[ |
??) |
] |
??/ |
\ |
??' |
^ |
??! |
| |
??< |
{ |
??> |
} |
??- |
~ |
| Sequenza | Carattere equivalente |
|---|---|
<: |
[ |
:> |
] |
<% |
{ |
%> |
} |
%: |
# |
%:%: |
## |
Snippet 11.49 <iso646.h>.
int a = 10, b = 11;
if (a and b) // and si espande in &&
<% // digramma equivalente a {
int d = ??-b; // fase 1 di traduzione del codice: sequenza ??- sostituita con ~
%> // digramma equivalente a }
Dimensione dei tipi interi <limits.h>
L’header <limits.h> definisce delle macro
SHRT_MIN, INT_MAX, LONG_MIN
e così via, che si espandono in espressioni costanti i cui valori
rappresentano i limiti dei tipi interi corrispondenti, short
int, int, long int e così via,
ossia i valori minimi e massimi che possono contenere (non dichiara
tipi e funzioni).
NOTA
I valori delle macro per i limiti dei tipi devono essere uguali o più grandi in magnitudine rispetto a quelli dei tipi indicati dalle Tabelle 2.2 e 2.7 del Capitolo 2 i cui valori sono quelli espressamente indicati nel documento dello standard di C.
Tra queste macro abbiamo anche la macro CHAR_BIT,
che indica il numero di bit di un byte (almeno 8),
MB_LEN_MAX, che indica il massimo numero di byte in un
carattere multibyte (almeno 1), CHAR_MIN
e CHAR_MAX i cui valori sono uguali a quelli di
SCHAR_MIN (-127) e SCHAR_MAX
(127), se un tipo char è trattato come un
intero con segno, altrimenti i valori sono uguali a 0
e a UCHAR_MAX (255).
Snippet 11.50 <limits.h>.
// valori con la corrente implementazione (GCC)
int nr_bit = CHAR_BIT; // 8
int c_min = CHAR_MIN; // -128
int c_max = CHAR_MAX; // 127
int sc_min = SCHAR_MIN; // -128
int sc_max = SCHAR_MAX; // 127
int uc_max = UCHAR_MAX; // 255
Localizzazione: <locale.h>
L’header <locale.h> dichiara le funzioni
setlocale e localeconv, il tipo
lconv e definisce le macro NULL,
LC_ALL, LC_COLLATE,
LC_CTYPE, LC_MONETARY,
LC_NUMERIC e LC_TIME le quali, eccetto
per NULL, si espandono in espressioni costanti i cui
valori sono utilizzabili come primo argomento della funzione
setlocale.
L’obiettivo delle funzionalità dichiarate in questo header è quello di consentire un adattamento delle proprie applicazioni al corrente sistema locale di un utente permettendo, di fatto, la cosiddetta internazionalizzazione del software.
TERMINOLOGIA
Per sistema locale s’intende un sistema dove l’interpretazione dei caratteri in uso, la formattazione delle quantità numeriche e monetarie, la visualizzazione di date e orari, il procedimento di ordinamento delle stringhe (collation ordering) e così via sono dipendenti da un insieme di convenzioni, classificate dallo standard in categorie, proprie del paese, della lingua e della cultura di un utente.
Quando si sceglie di cambiare un sistema locale è possibile decidere, in modo specifico e indipendente, quale categoria dello stesso modificare in modo che solo essa si adatti, per l’appunto, alla lingua e al paese di un determinato utente.
A tal fine è possibile usare le seguenti macro.
LC_COLLATE: questa categoria riguarda il procedimento di ordinamento delle stringhe. Dal punto di vista della libreria influenza il comportamento delle funzionistrcollestrxfrmdichiarate nell’header<string.h>.LC_CTYPE:questa categoria riguarda la classificazione e la conversione dei caratteri e dei caratteri multibyte ed estesi. Dal punto di vista della libreria influenza il comportamento: delle funzioni di gestione dei caratteri dichiarate nell’header<ctype.h>(eccetto le funzioniisdigiteisxdigit); delle funzioni di conversione tra caratteri multibyte e caratteri estesi dichiarate nell’header<stdlib.h>; delle funzioni di conversione tra stringhe multibyte e stringhe estese dichiarate nell’header<stdlib.h>; delle funzioni per la classificazione e mappatura dei caratteri estesi dichiarati nell’header<wctype.h>.LC_MONETARY: questa categoria riguarda la formattazione di valori numerici di tipo monetario. Dal punto di vista della libreria influenza quanto ritornato dalla funzionelocaleconvdichiarata nell’header<locale.h>(per la parte delle informazioni di formattazione di valori monetari).LC_NUMERIC: questa categoria riguarda la formattazione di valori numerici che non sono di tipo monetario. Dal punto di vista della libreria influenza: quale carattere usare come punto decimale di separazione per le funzioni per l’input e l’output formattato dichiarate nell’header<stdio.h>tipoprintfescanf; il comportamento delle funzioni per le conversioni numeriche dichiarate nell’header<stdlib.h>; quanto ritornato dalla funzionelocaleconvdichiarata nell’header<locale.h>(per la parte delle informazioni di formattazione di valori non monetari).LC_TIME: questa categoria riguarda la formattazione dei valori di date e orari. Dal punto di vista della libreria influenza il comportamento delle funzionistrftime, dichiarata nell’header<time.h>, ewcsftime, dichiarata nell’header<wchar.h>.
NOTA
La macro LC_ALL non definisce una
mera categoria; piuttosto consente di assegnare un’impostazione
locale che influenza tutte le categorie appena discusse. Al
contempo, un’implementazione è libera di definire delle ulteriori
categorie espresse tramite altre macro che iniziano con il prefisso
LC_ cui far seguire altri caratteri scritti in
maiuscolo (per esempio, nei sistemi Unix-like, un’implementazione
fornisce anche la macro LC_MESSAGES, che definisce una
categoria che influisce sulla formattazione dei messaggi di sistema
in merito ai valori propri di risposte affermative o negative).
Per modificare una corrente impostazione di un sistema locale con un nuovo sistema locale si deve impiegare la funzione seguente.
char *setlocale(int category, const char *locale): il parametrocategorydefinisce la categoria che sarà influenzata dal nuovo sistema locale e può assumere uno dei valori delle macro con prefissoLC_prima indicate (o di altre eventualmente previste dalla corrente implementazione). Il parametrolocaledefinisce il nome di un sistema locale da utilizzare e lo standard ne prevede solo due:"C", indica il sistema locale standard di C i cui attributi e comportamenti sono specificati, per l’appunto, dallo standard di C;""(stringa vuota), indica il corrente sistema locale in uso (quello nativo) così come definito per l’ambiente di un utente. È comunque possibile usare altre stringhe indicanti nomi di sistemi locali, ma ciò è dipendente dalla corrente implementazione e sistema in uso. Per esempio, nei sistemi GNU/Linux con GCC è possibile fornire al parametro locale delle stringhe nel formatolanguage[_territory[.codeset]][@modifier], dove:languageindica il nome della lingua da usare (codice di due caratteri come da standard ISO 639);_territoryindica il nome del paese che usa la lingua specificata (codice di due caratteri come da standard ISO 3166);.codesetindica il nome del set di caratteri da impiegare (una lista dei nomi ufficiali può essere consultata all’URLhttp://www.iana.org/assignments/character-sets/character-sets.xhtml);@modifierindica ulteriori attributi per la localizzazione come, per esempio, se usare una particolare moneta (tipo@euro), un dialetto della lingua (tipo@valencia) e così via (non esiste uno standard che esplicita cosa@modifierdebba contenere, quindi bisogna consultare la documentazione ufficiale della propria implementazione). Ritorna un puntatore alla stringa associata alla categoria indicata e modifica il corrente sistema locale da usare (tipicamente la stringa puntata ha lo stesso valore di quella fornita al parametrolocal) se l’invocazione ha avuto successo, e un puntatore nullo se l’invocazione non ha avuto successo (il corrente sistema locale non è modificato).
CONSIGLIO
In un ambiente Unix, tipo GNU/Linux, è possibile
usare il comando locale -a per ottenere una lista
delle localizzazioni presenti nel sistema in uso. In pratica, i
risultati ritornati possono essere forniti come valori del
parametro locale della funzione setlocale.
La funzione seguente, invece, consente di ottenere delle
informazioni sulle categorie LC_MONETARY e
LC_NUMERIC, ossia quali convenzioni in merito alla
formattazione dei valori monetari e non monetari il corrente
sistema locale adotta.
struct lconv *localeconv(void): non accetta argomenti ma ritorna un puntatore a una struttura di tipostruct lconvi cui membri sono valorizzati con le informazioni citate. Alcuni di questi membri sono di tipochar *e se contengono come valore la stringa"", per il corrente sistema locale non è prevista alcuna convenzione in particolare. Altri membri, invece, sono di tipochare se contengono come valoreCHAR_MAX, per il corrente sistema locale non è prevista alcuna convenzione in particolare. Per esempio: i membridecimal_pointemon_decimal_point, se valorizzati, indicano il carattere di separazione usato per separare la parte intera dalla parte frazionaria, rispettivamente, di quantità numeriche non monetarie e monetarie; i membrithousands_sepemon_thousands_sep, se valorizzati, indicano il carattere di separazione usato per separare gruppi di cifre prima del punto decimale, rispettivamente, di quantità numeriche non monetarie e monetarie; i membriint_curr_symbolecurrency_symbol, se valorizzati, indicano il “simbolo” usato per rappresentare la moneta corrente, rispettivamente, secondo una convenzione internazionale (un’abbreviazione di tre lettere come da standard ISO 4217, tipoUSD,EURe così via) oppure la convenzione locale (tipicamente un carattere come$,€e così via).
Snippet 11.51 <locale.h>.
// in ambiente Windows usare "Italian_Italy.1252"
const char *locale_to_use = "it_IT.utf-8";
// altri pattern comuni di utilizzo sono:
// 1) setlocale(LC_ALL, ""); -> ritorna il sistema locale nativo in uso
// e lo imposta pure
// 2) setlocale(LC_ALL, NULL); -> ritorna il corrente sistema locale in uso
// ma non lo imposta
char *locale = setlocale(LC_ALL, locale_to_use);
if (locale)
{
float number = 44.99f;
// si noti nell'output di printf come in accordo con le convenzioni del sistema
// locale italiano il carattere di separazione dei decimali è la virgola , e non
// il consueto punto .
printf("Valore di number: %.2f\n", number); // Valore di number: 44,99
// riempiamo la struttura locale_info con informazioni sulla formattazione
// di valori numerici di tipo monetario e non
struct lconv* locale_info = localeconv();
double amount = 12457.99;
printf("Le spese ammontano a %s%.2f\n", locale_info->currency_symbol, amount);
// Le spese ammontano a €12457,99
}
else
printf("%s non disponibile.\n", locale_to_use);
Funzioni matematiche <math.h>
L’header <math.h> definisce diverse macro e
dichiara due tipi e molteplici funzioni di natura matematica che
sono categorizzate come segue: funzioni trigonometriche
(cos, sin, tan e così via);
funzioni iperboliche (cosh,
sinh, tanh e così via); funzioni
esponenziali e logaritmiche (exp,
log, modf e così via); funzioni di
elevamento a potenza e valore assoluto (fabs,
hypot, pow e così via); funzioni di
errore e gamma (erf, lgamma e così
via); funzioni per l’intero più vicino (ceil,
floor, round e così via); funzioni
per il resto (fmod, remainder e così
via); funzioni di manipolazione (copysign,
nan e così via); funzioni di massimo, minimo e
differenza positiva (fdim, fmax e
fmin); moltiplicazione e somma in virgola
mobile (fma).
Tutte le funzioni sono dichiarate in tre versioni: una
principale, per esempio cos, che opera con i tipi
double; un’altra con lo stesso nome di quella
principale ma che termina con il suffisso f, per
esempio cosf, che opera con i tipi float;
un’altra ancora con lo stesso nome di quella principale ma che
termina con il suffisso l, per esempio
cosl, che opera con i tipi long
double.
I tipi introdotti a partire da C99 sono float_t e
double_t, i quali sono definiti tramite un
typedef verso dei corrispondenti tipi in virgola
mobile che siano grandi almeno quanto i tipi float e
double e che, con l’attuale implementazione, possano
garantire la massima efficienza computazionale durante le
operazioni aritmetiche in virgola mobile.
La macro FLT_EVAL_METHOD definita nell’header
<float.h> indica, a seconda del valore che ha e
per la corrente implementazione, quali sono i tipi effettivi
corrispondenti a float_t e double_t; se
vale 0, allora float_t sarà un
float e double_t sarà un
double: se vale 1, allora
float_t sarà un double e
double_t sarà un double; se vale
2, allora float_t sarà un long
double e double_t sarà un long
double.
Tra le macro abbiamo: HUGE_VAL, che si espande in
un’espressione costante di tipo double che rappresenta
il valore ritornato dalle funzioni matematiche in caso di overflow
(quando cioè il valore ritornato eccede quello massimo
rappresentabile da un tipo double);
INFINITY, che si espande in un’espressione costante di
tipo float che rappresenta, se disponibile, il valore
di infinito positivo; NAN, che si espande in
un’espressione costante di tipo float che rappresenta,
se disponibile, un valore che non è un numero in virgola mobile
valido (not a number).
NOTA
L’header <math.h>, a parte
alcune funzioni di semplice utilizzo nelle applicazioni ordinarie,
come per esempio quelle che vedremo nello Snippet 11.52, è
costituito da una molteplicità di funzioni complesse e
specialistiche. Esse sono sovente utilizzate per la costruzione di
applicazioni di carattere scientifico e richiedono un forte
background di teoria matematica per essere impiegate
consapevolmente. Una loro disamina, pertanto, essendo al di fuori
degli obiettivi didattici del presente testo, non sarà
effettuata.
Snippet 11.52 <math.h>.
// nello standard IEEE 754 ogni computazione tra valori in virgola mobile;
// deve comunque avere un risultato definito; quindi, anche per: a / 0; -a / 0; 0 / 0
printf("Infinito positivo: %f\n", 10.0 / 0); // Infinito positivo: inf
printf("Infinito negativo: %f\n", -10.0 / 0); // Infinito negativo: -inf
printf("NaN: %f\n", 0.0 / 0); // NaN: nan
// pow computa il primo argomento elevato alla potenza del secondo argomento
printf("5 elevato alla potenza di 0.5 = %.2f\n", pow(5.0, 0.5));
// 5 elevato alla potenza di 0.5 = 2.24
// sqrt computa la radice quadrata del primo argomento che deve essere >= 0
printf("Radice quadrata di 22.22 = %.2f\n", sqrt(22.22));
// Radice quadrata di 22.22 = 4.71
// ceil computa il più piccolo intero che non è minore del suo argomento
// esegue sempre una sorta di "arrotondamento per eccesso"
printf("Arrotondamento di 4.3 (ceil) = %.2f\n", ceil(4.3)); // Arrotondamento di
// 4.3 (ceil) = 5.00
// floor computa il più grande intero che non è maggiore del suo argomento
// esegue sempre una sorta di "arrotondamento per difetto"
printf("Arrotondamento di 4.3 (floor) = %.2f\n", floor(4.3)); // Arrotondamento di
// 4.3 (floor) = 4.00
// fmod computa il resto della divisione in virgola mobile dei suoi due argomenti
printf("Resto della divisione tra 4.3 / 2.2 = %.2f\n", fmod(4.3 , 2.2)); // Resto della
// divisione tra 4.3 / 2.2 = 2.10
NOTA
In questo header è anche illustrato il
comportamento della direttiva #pragma STDC FP_CONTRACT
la quale, se impostata su ON, permette alla corrente
implementazione di “contrarre” un’espressione in virgola mobile,
ossia di valutarla come se fosse una singola operazione al fine di
incrementare la velocità computazionale. Nel momento in cui vengono
scritte queste righe sia GCC che MinGW non supportano ancora tale
direttiva.
Salti non-locali <setjmp.h>
L’header <setjmp.h> definisce la macro
parametrica setjmp, dichiara la funzione
longjmp e il tipo jmp_buf. In modo
combinato queste tre “entità” consentono di porre in essere dei
salti non locali, ossia permettono, da una funzione
qualsiasi, di spostare il flusso di esecuzione del codice
direttamente nell’ambito di una qualsiasi altra funzione.
Ricordiamo, infatti, che se abbiamo le seguenti funzioni,
diciamo A, B, C,
D ed E, laddove A invoca
B, B invoca C,
C invoca D e D invoca
E allora, quando E cesserà la sua
esecuzione, il flusso di ritorno del codice sarà necessariamente da
E a D, da D a C
e da B ad A (rammentiamo anche che non è
possibile usare l’istruzione goto, posta diciamo nella
funzione E, per saltare a una label posta in un’altra
funzione, diciamo A).
Per consentire queste tipologie di salti possiamo usare il seguente template.
- Nell’ambito di una funzione utilizziamo la macro parametrica
setjmpin modo da “marcare” un punto in quell’ambito che servirà come target di un futuro salto effettuato dalla funzionelongjmp. La macro parametricasetjmpprende come argomento una variabile di tipojmp_bufche è deputata a salvare il corrente “ambiente di invocazione”.setjmpritorna0, se è stata direttamente invocata e un valore diverso da0se è stata “invocata” per il tramite della funzionelongjmp. - Nell’ambito di un’altra funzione utilizziamo la funzione
longjmpla quale prenderà: come primo argomento la variabile di tipojmp_bufutilizzata da una precedente chiamata asetjmp; come secondo argomento un valore di tipointche sarà ritornato dalla funzionesetjmpquandolongjmpne passerà il flusso di esecuzione del codice. In sostanza,longjmpripristinerà “l’ambiente di invocazione” salvato dasetjmp, e astratto nel tipojmp_buf, e farà riprendere il flusso di esecuzione del codice dal quel punto di esecuzione marcato dasetjmp.
Snippet 11.53 <setjmp.h>.
...
jmp_buf env; // conterrà le informazioni del corrente ambiente di invocazione
void E(void)
{
// il primo argomento di longjmp è la variabile env, la stessa usata da setjmp
// il secondo argomento di longjmp fornirà il valore ritornato da setjmp
longjmp(env, 1); // salta in main nel punto marcato da setjmp
}
void D(void) { E(); /* invoca E */ }
void C(void) { D(); /* invoca D */ }
void B(void) { C(); /* invoca C */ }
void A(void) { B(); /* invoca B */ }
int main(void)
{
if(setjmp(env) == 0) // marca il punto dove longjmp farà il salto
printf("setjmp invocata direttamente da main...\n");
else // quando "chiamata" da longjmp setjmp ritornerà 1
{
printf("setjmp \"invocata\" da longjmp...\n");
return (EXIT_SUCCESS); // esco da qui...
}
A(); // invoca A
return (EXIT_SUCCESS); // esco da qui, normalmente...
}
Gestione dei segnali <signal.h>
L’header <signal.h> dichiara il tipo
sig_atomic_t, le funzioni signal e
raise e definisce varie macro. Le funzionalità di
questo header sono studiate per consentire di gestire i cosiddetti
segnali, i quali rappresentano delle condizioni
eccezionali che possono accadere durante l’esecuzione di un
programma.
- Terminazione anomala, causata per esempio
dall’invocazione della funzione
abort(macroSIGABRT, sta per signal abort). - Errore aritmetico fatale, causato per esempio da una
divisione per
0o un overflow (macroSIGFPE, sta per signal floating-point exception). - Immagine della funzione illegale, causata per esempio
dalla scrittura di un’istruzione illegale; si pensi a una funzione
che si attende come argomento un puntatore a una funzione ma invece
ha come argomento un puntatore a un oggetto qualsiasi, tipo una
variabile, e dunque “esegue quest’oggetto” come se fosse del codice
mentre, in realtà, è un dato qualsiasi (macro
SIGILL, sta per signal illegal instruction). - Ricezione di un segnale di attenzione interattivo:
causato, per esempio, da un interrupt (interruzione),
ossia da un segnale inviato alla CPU da un dispositivo hardware o
da apposite istruzioni software che indicano l’accadimento di una
situazione o evento che richiede un’immediata attenzione (macro
SIGINT, sta per signal interrupt). - Accesso illegale alla memoria, causata per esempio da
un deriferimento di un puntatore nullo o non inizializzato (macro
SIGSEGV, sta per signal segmentation violation). - Richiesta di terminazione inviata al programma,
causata per esempio dall’esecuzione di un comando tipo
kill(macroSIGTERM, sta per signal termination).
Le macro elencate, che si espandono in espressioni costanti
intere di tipo int, sono le uniche indicate dalla
libreria standard che rappresentano gli equivalenti segnali.
Tuttavia un’implementazione per un determinato sistema può
decidere di fornire ulteriori macro che rappresentano altri segnali
a condizione che i loro nomi inizino con SIG o
SIG_ cui fa seguito una lettera maiuscola (per
esempio, SIGTRAP, SIGEMT,
SIGSYS e così via).
La funzione signal, prototipo void
(*signal(int sig, void (*func)(int)))(int), consente di
assegnare per un determinato segnale, indicato dal parametro
sig, un apposito gestore, indicato dal parametro
func.
Il gestore di un segnale è un puntatore a una funzione che non
ritorna nulla (void) e che ha come parametro un intero
(int); esso è fondamentale per l’utilizzo dei segnali
perché rappresenta il “codice” che viene chiamato automaticamente
all’accadimento di una certa condizione eccezionale e che fornisce
la logica di gestione di quella condizione (per esempio, la ignora,
termina il programma, prova a recuperare l’errore occorso e così
via).
La funzione raise, prototipo int raise(int
sig), consente di generare programmaticamente il segnale
indicato dal parametro sig. Ritorna 0 in
caso di successo, non 0 altrimenti.
Snippet 11.54 <signal.h>.
...
int makeOperations(int value_1, int value_2, int (*op)(int, int));
void handler(int signal); // gestore di un segnale
int main(void)
{
signal(SIGILL, handler); // per la gestione di un SIGILL
int a;
// passiamo un puntatore a un oggetto piuttosto che a una funzione e ciò
// farà generare un SIGILL
makeOperations(1, 1, &a);
return (EXIT_SUCCESS);
}
int makeOperations(int value_1, int value_2, int (*op)(int, int))
{
return (*op)(value_1, value_2);
}
// il parametro signal conterrà un intero indicante il segnale occorso
void handler(int signal) // gestore di un segnale
{
if (signal == SIGILL)
{
printf("ATTENZIONE \"istruzione illegale\". Esco dal programma\n");
// faccio abortire il corrente programma come se avessi invocato abort
// è usato solo per fini didattici perché il programma terminerebbe comunque
// in modo anomalo e presenterebbe un messaggio tipo
// Segmentation fault; core dumped;
// in questo caso, in più, si evita anche la generazione di quel messaggio,
// indicando all'utente in modo più significativo quello che è accaduto
// e facendo terminare in modo "più grazioso" il programma
raise(SIGABRT); // genero SIGABRT
}
}
Allineamento <stdalign.h> (C11)
L’header <stdalign.h> definisce solamente
quattro macro: alignas, che si espande in
_Alignas; alignof, che si espande in
_Alignof; __alignas_is_defined, che si
espande con il valore 1;
__alignof_is_defined, che si espande con il valore
1.
Le prime due macro consentono, in effetti, di usare con un nome più conveniente gli specificatori di allineamento relativi (sono stati trattati nel Capitolo 9).
Le altre due macro, invece, sono utili se impiegate con la
direttiva del preprocessore #if.
Snippet 11.55 <stdalign.h>.
...
int main(void)
{
// se entrambe le macro hanno un valore diverso da 0 usa alignas e alignof
#if __alignas_is_defined && __alignof_is_defined
printf("Procedo con le operazioni di allineamento...\n");
#endif
...
}
Argomenti variabili <stdarg.h>
L’header <stdarg.h> dichiara il tipo
va_list e definisce le macro parametriche
va_start, va_arg, va_end e
va_copy. Tramite le funzionalità di questo header è
possibile processare una funzione che è stata dichiarata con la
possibilità di ricevere argomenti a lunghezza variabile,
ossia è possibile “avanzare” attraverso una lista di argomenti il
cui numero e tipo non sono noti alla funzione chiamata (possono
variare a ogni invocazione).
NOTA
Un utilizzo dettagliato di tali funzionalità è stato mostrato nel Capitolo 6.
Snippet 11.56 < stdarg.h>.
// template di definizione di una funzione capace di ricevere un una lista di argomenti
// il cui numero e tipo non sono noti a priori
// in questo caso si assume che la funzione ritorni un valore int ma ciò
// non è obbligatorio
int foo(int length, ...)
{
// step per scorrere tutti gli argomenti variabili ----------------------------
va_list ap; // I dichiarazione di un tipo va_list
va_start(ap, length); // II inizializzazione del tipo va_list
int result = va_arg(ap, int); // III ottenimento valore primo argomento
for (int i = 1; i < length; i++)
result -= va_arg(ap, int); // IV ottenimento valori successivi argomenti
va_end(ap); // V "pulizia" del tipo va_list
// ----------------------------------------------------------------------------
return result;
}
Operazioni atomiche <stdatomic.h> (C11)
L’header <stdatomic.h> definisce diverse
macro, dichiara vari tipi e funzioni che consentono di compiere
operazioni atomiche su dati condivisi tra differenti thread di
esecuzione.
È possibile verificare se la corrente implementazione supporta
tale caratteristica; infatti, se è definita la macro
__STDC_NO_ATOMICS__, allora questo header non è
fornito così come le relative funzionalità.
NOTA
Nel Capitolo 9 è stato fornito un breve esempio
di effettuazione di un’operazione atomica. Ci preme sottolineare
che non potremo effettuare una disamina di questo header, seppure
introduttiva, perché ciò richiederebbe una conoscenza preliminare,
teorica e pratica, dei concetti e dei costrutti propri della
programmazione concorrente che, però, non potremo fornire perché
alla data di scrittura del presente testo nessuna implementazione
(inclusa quella della libreria glibc) ne ha ancora il supporto così
come prescritto dallo standard C11 (file header
<threads.h>).
Valori e tipo booleani <stdbool.h> (C99)
L’header <stdbool.h> definisce la macro:
bool, che si espande in _Bool;
true, che si espande con il valore 1;
false, che si espande con il valore 0;
__bool_true_false_are_defined, che si espande con il
valore 1.
In sostanza questo header è utile per usare in modo più conveniente il nome del tipo booleano e in modo più leggibile i valori di verità e falsità.
Snippet 11.57 < stdbool.h>.
// mi accerto che le macro bool, true e false siano definite, così eventualmente
// non le ridefinisco e uso quelle già fornite
#if __bool_true_false_are_defined
bool flag = false;
#endif
Definizioni comuni <stddef.h>
L’header <stddef.h> definisce le macro:
NULL, che si espande in una costante di tipo puntatore
nullo; offsetof, che si espande in un’espressione
costante intera, di tipo size_t, il cui valore indica
la distanza in byte di un membro di una struttura rispetto
all’inizio della struttura dove è stato dichiarato (in effetti
questa macro è definita come una macro parametrica: il primo
argomento fornito indica il tipo di una struttura, mentre il
secondo argomento fornito indica il nome di un membro di quella
struttura).
Dichiara anche i seguenti tipi: ptrdiff_t, che è un
tipo intero con segno atto a contenere il risultato della
sottrazione tra due puntatori; size_t, che è un tipo
intero senza segno atto a contenere il risultato dell’operatore
sizeof; max_align_t, che è un oggetto di
un tipo definito dalla corrente implementazione (per esempio un
typedef di una struct) che è deputato a
esprimere un valore di allineamento grande quanto il valore di
allineamento del più grande tipo fornito da un’implementazione (per
esempio un long double); wchar_t, che è
un tipo intero grande abbastanza per contenere i codici di tutti i
membri del più grande set di caratteri estesi supportato dalla
corrente implementazione.
In definitiva questo header, che non presenta dichiarazioni di funzioni, ha lo scopo di fornire per tutti i programmi definizioni di macro e dichiarazioni di tipo di uso frequente.
Snippet 11.58 < stddef.h>.
struct S
{
char c_data;
int data;
} s = {'A', 65};
// data si troverà a 4 byte di distanza dall'inizio della struttura di tipo
// struct S e ciò perché, ricordiamo, tra il tipo char e il tipo int sono
// posti 3 byte di memoria "non usata" al fine di allineare correttamente la memoria
size_t ofo = offsetof(struct S, data); // 4
Tipi interi <stdint.h> (C99)
L’header <stdint.h> dichiara, attraverso
opportuni typedef, un insieme di tipi interi che hanno
un determinato numero di bit e, per ciascuno di essi, dichiara
anche delle macro che esplicitano i loro valori minimi (per i tipi
interi con segno) e massimi (per i tipi interi con segno e senza
segno). In questo header non sono dichiarate funzioni.
Questo file header è importante se si ha la necessità di scrivere programma portabili tra piattaforme differenti perché l’utilizzo dei suoi tipi garantisce che gli stessi avranno la stessa dimensione anche se utilizzati in sistemi, per l’appunto, differenti.
Sappiamo, infatti, che C non stabilisce che un tipo
int deve essere esattamente di 32 bit su ogni sistema,
ma dice che esso deve essere non più piccolo di un tipo
short e non più grande di un tipo long e
che deve contenere dei valori che siano almeno uguali o più grandi
rispetto al range -32767 / 32767
(consultare la Tabella 2.2 del Capitolo 2).
Così, il tipo int32_t dichiarato nell’header
<stdint.h> deve rappresentare
esattamente un tipo intero con segno a 32 bit. Se tale
file header è utilizzato in un sistema a 32 bit, allora la corrente
implementazione potrebbe definirlo come typedef int
int32_t (un int su un sistema a 32 bit ha
tipicamente un range di valori -2147483648 /
2147483647), mentre se questo file header è utilizzato
in un sistema a 16 bit allora la corrente implementazione potrebbe
definirlo come typedef long int32_t (un
long su un sistema a 16 bit ha tipicamente un range di
valori -2147483648 / 2147483647).
In ambedue i casi, quindi, vi sarà la garanzia che un tipo
int32_t avrà la possibilità di memorizzare dei valori
che saranno compresi nel tipico range di valori offerto da un tipo
a 32 bit, ossia tra -2147483648 e
2147483647.
I tipi interi dichiarati nell’header
<stdint.h> sono categorizzati come segue.
- Tipi interi con un’ampiezza esatta
(
int8_t,int16_t,int32_teint64_tper i tipi con segno euint8_t,uint16_t,uint32_teuint64_tper i tipi senza segno). Se un’implementazione fornisce tipi interi a 8, 16, 32 e 64 bit deve, allora fornire i nomi di tipi interi qui indicati con la stessa esatta quantità di bit. Altrimenti gli stessi sono opzionali. - Tipi interi con un’ampiezza minima
(
int_least8_t,int_least16_t,int_least32_teint_least64_tper i tipi con segno euint_least8_t,uint_least16_t,uint_least32_teuint_least64_tper i tipi senza segno). Almeno i nomi dei tipi interi qui indicati devono essere garantiti da un’implementazione, ossia vi devono essere dei tipi interi che garantiscano quelle quantità minime di ampiezza. - Tipi interi più veloci con un’ampiezza minima
(
int_fast8_t,int_fast16_t,int_ fast32_teint_ fast64_tper i tipi con segno euint_fast8_t,uint_fast16_t,uint_fast32_teuint_fast64_tper i tipi senza segno). Almeno i nomi dei tipi interi qui indicati devono essere garantiti da un’implementazione, ossia vi devono essere dei tipi interi che garantiscano quelle quantità minime di ampiezza e che siano i più veloci durante l’esecuzione delle computazioni che ne fanno uso (la precisa semantica e la rappresentazione di un tipo intero “più veloce” sono a discrezione della corrente implementazione). - Tipi interi capaci di contenere puntatori a oggetti
(
intptr_tper un tipo con segno euintptr_tper un tipo senza segno). I nomi dei tipi interi qui indicati sono opzionali, ma se presenti devono garantire che se si assegna a uno di essi un tipovoid *e poi uno di essi si riassegna a un tipovoid *, queste operazioni siano eseguite in sicurezza, cioè senza perdita di informazioni. - Tipi interi con la più grande ampiezza
(
intmax_tper un tipo con segno euintmax_tper un tipo senza segno). I nomi dei tipi qui indicati devono essere garantiti da un’implementazione, ossia vi devono essere dei tipi interi che siano capaci di rappresentare qualsiasi valore di tipo intero, con segno o senza segno.
Per ognuno dei tipi interi dichiarati in questo header vi è una corrispondente macro che specifica il suo valore minimo e massimo (o solo massimo se il tipo intero è senza segno).
Ogni macro è denominata allo stesso modo del corrispettivo tipo
ma in maiuscolo e con la differenza che al suffisso _t
è sostituito il suffisso _MIN o _MAX (per
esempio, il tipo int_fast8_t avrà una macro denominata
INT_FAST8_MIN e INT_FAST8_MAX).
Snippet 11.59 <stdint.h>.
// questo valore sarà garantito in modo portabile su piattaforme diverse
int32_t i32 = 2000000000;
printf("Dimensione minima [%d] / massima [%d] di int32_t\n", INT32_MIN, INT32_MAX);
// Dimensione minima [-2147483648] / massima [2147483647] di int32_t
_Noreturn <stdnoreturn.h> (C11)
L’header <stdnoreturn.h> definisce la macro
noreturn che si espande in _Noreturn. In
definitiva questa macro consente di usare un nome più
conveniente per lo specificatore di funzione relativo.
Snippet 11.60 < stdnoreturn.h>.
// questa funzione se riceve un valore maggiore di 0 abortisce il corrente programma
// non ritornerà mai al chiamante
// chiaramente non bisognerà mai passare valori uguali o minori di 0...
noreturn void abortIf(int v)
{
if(v > 0) abort();
}
Matematica per tipi generici <tgmath.h> (C99)
L’header <tgmath.h> include gli header
<math.h> e <complex.h> e
definisce molteplici macro parametriche che sono in grado di
rilevare il tipo oppure i tipi degli argomenti forniti e invocare
una corrispondente funzione propria della libreria matematica
oppure propria della libreria dell’aritmetica complessa.
TERMINOLOGIA
Lo standard definisce queste macro come type-generic macros.
Ricordiamo, infatti, che nell’header <math.h>
le relative funzioni sono dichiarate in tre differenti “versioni” a
seconda che l’argomento sia di tipo double (per
esempio pow), di tipo float (per esempio
powf) o di tipo long double (per esempio
powl).
Allo stesso modo nell’header <complex.h>,
laddove previsto, sono dichiarate delle funzioni che sono le
equivalenti di quelle dell’header <math.h>, ma
operano invece con i tipi complessi, e sono altresì dichiarate in
tre differenti versioni a seconda che l’argomento sia di tipo
double complex (per esempio cpow), di
tipo float complex (per esempio cpowf) o
di tipo long double complex (per esempio
cpowl).
Ciò detto appare evidente che a seconda del tipo di dato delle
variabili utilizzate (per esempio, ritornando alle funzioni ora
citate, per un’operazione di elevamento a potenza), dobbiamo
ricordarci di invocare la giusta funzione dell’header
<math.h> o <complex.h>.
Per evitare tale difficoltà ci vengono in soccorso l’header
<tgmath.h> e le sue macro parametriche; è
infatti sufficiente invocare una macro desiderata (per esempio
pow), e la stessa, “dietro le quinte”, a seconda del
tipo o dei tipi di dato forniti, invocherà l’equivalente funzione
presente nell’header <math.h> o
<complex.h>.
Queste macro parametriche sono categorizzate nei seguenti tre gruppi.
- Le macro di questo gruppo corrispondono a delle funzioni che si
trovano dichiarate sia nell’header
<math.h>sia nell’header<complex.h>. In questo caso i nomi delle macro saranno uguali ai nomi delle funzioni relative senza, però, alcun prefisso o suffisso (per esempio, le funzionisin,sinfesinldell’header<math.h>e le funzionicsin,csinfecsinldell’header<complex.h>avranno una macro corrispondente denominatasin). - Le macro di questo gruppo corrispondono a delle funzioni che si
trovano dichiarate solo nell’header
<math.h>. Anche in questo caso i nomi delle macro saranno uguali ai nomi delle funzioni relative senza, però, alcun suffisso (per esempio, le funzioniround,roundferoundldell’header<math.h>avranno una macro corrispondente denominataround). Se a una di queste macro si passa un argomento di un tipo complesso, il comportamento sarà non definito. - Le macro di questo gruppo corrispondono a delle funzioni che si
trovano dichiarate solo nell’header
<complex.h>. Anche in questo caso i nomi delle macro saranno uguali ai nomi delle funzioni relative senza, però, alcun suffisso (per esempio, le funzioni creal,crealfecrealldell’header<complex.h>avranno una macro corrispondente denominatacreal). Se a una di queste macro si passa un argomento di un tipo reale, il comportamento sarà non definito.
Snippet 11.61 < tgmath.h>.
float value = 4.3f;
// in questo caso verrà invocata roundf
printf("Valore di value [%.1f] arrotondato in [%.1f]\n", value,
round(value)); // Valore di value [4.3] arrotondato a [4.0]
Threads <threads.h> (C11)
L’header <threads.h> include l’header
<time.h>, definisce macro e dichiara tipi,
costanti di enumerazione e funzioni per il supporto di thread di
esecuzione multipli.
È possibile verificare se la corrente implementazione supporta
tale caratteristica; infatti, se è definita la macro
__STDC_NO_THREADS__, allora questo header non è
fornito così come le relative funzionalità.
NOTA
Una disamina completa di questo header richiederebbe una trattazione preliminare e approfondita della programmazione concorrente, la quale però non potrà essere effettuata perché alla data di scrittura del presente testo nessuna implementazione (inclusa quella della libreria glibc) fornisce l’API descritta in questo header.
Data e ora: <time.h>
L’header <time.h> definisce le macro
NULL (il consueto puntatore nullo),
CLOCKS_PER_SEC (si espande in un’espressione di tipo
clock_t che rappresenta il numero di clock
ticks per secondo) e TIME_UTC (presente a partire
dallo standard C11, si espande in un intero costante maggiore di
0 che designa il tempo UTC), dichiara i tipi
size_t (il consueto tipo intero ritornato
dall’operatore sizeof), clock_t (un tipo
reale capace di contenere informazioni sul tempo di
utilizzo del processore espresso in numero di clock
ticks), time_t (un tipo reale capace di
memorizzare l’ora e la data corrente in numero di secondi passati
rispetto allo Unix time [o Epoch time], ossia
dalle 00:00:00 UTC del 1 gennaio 1970), struct
timespec (presente a partire dallo standard C11, è un tipo
struttura capace di contenere un intervallo di tempo specificato in
secondi e nanosecondi), struct tm (è un tipo struttura
capace di contenere, in modo estremamente granulare, tutte le
informazioni di una data e di un orario) e diverse funzioni
categorizzate in funzioni per la manipolazione delle ore
(clock, mktime, time e così
via) e funzioni per conversione delle ore
(asctime, localtime,
strftime e così via).
TERMINOLOGIA
Un clock tick è un’unità temporale, espressione di un interrupt timer periodico sul quale si basa l’orologio di sistema, utilizzata per misurare un certo tempo CPU.
TERMINOLOGIA
UTC (Coordinated Universal Time), in italiano Tempo Coordinato Universale, è un sistema standard di riferimento usato per la misurazione del tempo nel mondo che fa uso di orologi atomici ed è il successore del sistema GMT (Greenwich Mean Time). In sostanza UTC è la scala di tempo oggi usata per regolare gli orologi dell’ora civile del meridiano fondamentale e pertanto del tempo civile di tutto il mondo.
Snippet 11.62 < time.h>.
clock_t start, end;
double cpu_time;
// registra il tempo CPU impiegato dal programma dall'inizio dell'esecuzione
start = clock();
int a = INT_MAX;
printf("Computazione in corso... "); fflush(stdout);
while(a-- >=0) ; // simula un ritardo banale
// registra un altro tempo CPU impiegato dal programma dall'inizio dell'esecuzione
// che si può essere "dilatato" a causa dell'elaborazione delle istruzioni proprie
// di tale programma
end = clock();
// ritorna quanti secondi sono passati dall'inizio del programma rispetto anche alla
// computazione precedente...
// end - start è diviso per CLOCKS_PER_SEC per ottenere il tempo espresso in secondi
double diff = (double) end - start;
cpu_time = diff / CLOCKS_PER_SEC;
printf("\nSono stati impiegati [ %.2f ] clock ticks, all'incirca, [ %.2f ] secondi\n", diff, cpu_time);
ATTENZIONE
Nei sistemi GNU/Linux con GCC e nell’attuale
implementazione della libreria standard,
CLOCKS_PER_SEC vale 1000000, così come
indicato dalle richieste POSIX, mentre nei sistemi Windows con
MinGW e nell’attuale implementazione della libreria standard vale
1000. Infatti, se proviamo a eseguire lo snippet
presentato nei due diversi sistemi avremo che i clock ticks passati
saranno espressi in milioni di unità per un sistema
GNU/Linux (per esempio qualcosa come 4839429.00) e in
migliaia di unità per un sistema Windows (per esempio qualcosa come
4839.00).
Snippet 11.63 < time.h>.
...
#define SIZE 256
int main(void)
{
// in ambiente Windows usare "Italian_Italy.1252"
const char *locale_to_use = "it_IT.utf-8";
// equivalente a: time(&now)
time_t now = time(NULL); // ritorna una data e un orario (calendar time)
// in numero di secondi rispetto allo Unix time
// conterrà informazioni particolareggiate su una data e un orario
// che sarà, cioè, scomposto (broken-down time) in ore, minuti, secondi
// giorno, mese, anno e così via che saranno memorizzati nei corrispettivi membri
struct tm *bdc;
char *locale = setlocale(LC_ALL, locale_to_use);
if (locale) // se il corrente locale è disponibile, dammi data e orario locale
{
// riempie i membri della struttura di tipo struct tm con le informazioni
// dettagliate di una data e un orario rispetto al corrente sistema locale
bdc = localtime(&now);
// visualizziamo le informazioni di bdc "manualmente" e secondo una nostra
// formattazione custom tipo: dd/mm/aaaa hh:mm:ss
// per esempio: 25/01/2015 09:47:17
printf("Data e ora corrente [via printf...]\n"
"%.2d/%.2d/%d %.2d:%.2d:%.2d\n", bdc->tm_mday, // giorno del mese [1, 31]
bdc->tm_mon + 1, // mese [0, 11]
bdc->tm_year + 1900, // anno dal 1900
bdc->tm_hour, // ore [0, 23]
bdc->tm_min, // minuti [0, 59]
bdc->tm_sec); // secondi [0, 60]
// visualizziamo le stesse informazioni di bdc mediante la funzione strftime
// la quale attua una formattazione di una data e un orario in base a degli
// appositi specificatori di conversione: per esempio; %d, giorno del mese [01 - 31];
// %A, nome completo del giorno della settimana; %B, nome completo del mese;
// %Y, anno con il secolo; %H, ora [00 - 23]; %M, minuti [00 - 59];
// %S, secondi [00 - 60]
// è altresì sensibile al corrente sistema locale
// sarà visualizzato qualcosa come: domenica 25 gennaio 2015 10:18:32
printf("Data e ora corrente [via strftime...]\n");
char d_t[SIZE];
strftime(d_t, // array di char dove saranno memorizzate la data e l'ora formattate
SIZE, // massimo numero di caratteri memorizzati nell'array di char
"%A %d %B %Y %H:%M:%S", // specifiche di conversione
bdc // struttura di tipo struct tm
);
puts(d_t);
}
else // dammi una data e un orario formattati secondo una certa convenzione
{ // e in accordo al sistema UTC
printf("Data e ora corrente [via asctime...]\n");
// asctime converte data e orario forniti dalla struttura bdc nel
// seguente formato: Sun Sep 16 01:03:52 1973\n\0
// ritorna un tipo char *
// gmtime converte data e orario forniti dal tipo time_t now (calendar time)
// in una struttura di tipo struct tm (broken-down time) e in ora assoluta UTC
// ritorna un tipo struct tm *
printf("%s\n", asctime(gmtime(&now))); // Sun Jan 25 09:34:16 2015
}
...
}
Utility Unicode <uchar.h> (C11)
L’header <uchar.h> dichiara i tipi
mbstate_t (un tipo capace di contenere informazioni
sullo stato di conversione necessario per convertire dei caratteri
multibyte in caratteri estesi), size_t (il consueto
tipo intero ritornato dall’operatore sizeof),
char16_t (un tipo intero senza segno capace di
contenere caratteri codificati a 16 bit [UTF-16]) e
char32_t (un tipo intero senza segno capace di
contenere caratteri codificati a 32 bit [UTF-32]) e una serie di
funzioni per la conversione tra i caratteri multibyte/estesi e i
tipi char16_t e char32_t.
NOTA
Nel momento in cui vengono scritte queste righe
la versione della libreria standard del linguaggio C utilizzata per
il corrente ambiente GNU/Linux, glibc 2.20, non supporta ancora
l’header <uchar.h>. Al contempo anche la
libreria fornita con il package MinGW, per il corrente ambiente
Windows, non ne fornisce il supporto.
Unicode
Unicode è un sistema di codifica universale per i caratteri (sviluppato e mantenuto da un’organizzazione no profit denominata Unicode Consortium), indipendente dal sistema informatico e dalla lingua in uso, che assegna a ciascun carattere un valore numerico (codepoint). Il sistema nasce con l’obiettivo di rappresentare i caratteri di tutte le lingue del mondo (anche di quelle antiche), i simboli scientifici, gli ideogrammi e così via. Nella prima versione di Unicode, dal 1991 al 1995, la codifica dei caratteri era a 16 bit, con cui si potevano codificare fino a 65.536 caratteri; con la versione 2.0 del 1996 la codifica passò a 21 bit con la possibilità di rappresentare circa 2 milioni di caratteri. Dopo di allora vi sono state altre versioni dello standard che lo hanno migliorato sia dal punto di vista formale (per esempio attraverso la modifica delle definizioni terminologiche che erano poco chiare delle versioni precedenti) sia da quello più pratico grazie all’aggiunta progressiva di ulteriori caratteri (per esempio per la lingua etiopica, cherokee e così via). Attualmente Unicode è giunto alla versione 7.0 rilasciata il 16 giugno 2014.
NOTA
Nello standard di C è spesso citata la specifica ISO/IEC 10646 la quale, al pari di Unicode, nasce con l’obiettivo di fornire un sistema di codifica universale multilingua (UCS, Universal Character Set). Dal 1991, comunque, il gruppo responsabile della specifica ISO/IEC 10646 e il consorzio Unicode hanno deciso di lavorare insieme al fine di mantenere sincronizzati tra i due standard i codici carattere e le forme di codifica. Infatti, ogni versione dello standard Unicode identifica una corrispondente versione della specifica ISO/IEC 10646; per esempio, l’attuale versione di Unicode 7.0 è sincronizzata con la specifica ISO/IEC 10646:2012 e i relativi Amendments 1 e 2.
Utilità per i caratteri multibyte ed estesi <wchar.h> (C95)
L’header <wchar.h> definisce le macro
NULL (il consueto puntatore nullo),
WCHAR_MIN (si espande in un intero che esprime il più
piccolo valore inseribile nel tipo wchar_t),
WCHAR_MAX (si espande in un intero che esprime il più
grande valore inseribile nel tipo wchar_t) e
WEOF (si espande in un’espressione costante di tipo
wint_t il cui valore non deve corrispondere a nessun
membro di un set di caratteri esteso ed esprime un end of
file, ossia non c’è più input da uno stream), dichiara i tipi
wchar_t (un tipo intero il cui range di valori è in
grado di rappresentare tutti i codici di tutti i membri del set di
caratteri più esteso tra quelli supportati), size_t
(il consueto tipo intero ritornato dall’operatore
sizeof), mbstate_t (il consueto tipo per
memorizzare informazioni sullo stato di una conversione) e
wint_t (un tipo intero capace di contenere qualsiasi
valore di un corrispondente membro di un set di caratteri esteso) e
molteplici funzioni categorizzate come: funzioni di
input/output formattato per i caratteri estesi
(fwprintf, fwscanf e così via);
funzioni di input/output per i caratteri estesi
(fputws, fgetws e così via); funzioni
di utilità generali per stringhe estese (wmemcpy,
wcscat, wcscmp, wcschr e
così via); funzioni per la conversione di orari per i
caratteri estesi (wcsftime); funzioni di
utilità per la conversione fra caratteri multibyte e caratteri
estesi (mbrtowc, wcrtomb,
mbsrtowcs, wcsrtombs e così via).
Per comprendere come utilizzare le facility di questo header è opportuno dare una spiegazione, seppure breve, dei seguenti elementi.
- Carattere multibyte: è un carattere codificato in una
sequenza variabile di uno o più byte (due, tre e così via) che
rappresentano un membro di un set di caratteri esteso usato in un
ambiente di scrittura del codice sorgente oppure in un ambiente di
esecuzione del codice. I caratteri multibyte sono usabili nei
commenti, nei letterali stringa e così via. A partire da C99, come
già anticipato nel Capitolo 2, è possibile usare dei caratteri da
un set di caratteri estesi anche per scrivere gli identificatori
(UCN, Universal Character Names). Un carattere universale
è scrivibile utilizzando una sorta di sequenza di escape che
utilizza uno dei seguenti pattern:
\uhex-quado\Uhex-quadhex-quad, dovehex-quadè una sequenza di 4 cifre esadecimali. Il primo pattern permette di utilizzare un code point UCS fino al valore esadecimale diFFFF, mentre l’altro pattern permette di utilizzare code point maggiori. In ogni caso è possibile usare un carattere universale scritto mediante quei pattern anche nei letterali caratteri e nei letterali stringa. - Carattere esteso: è un carattere codificato in una
sequenza fissa di byte capace di rappresentare qualsiasi carattere
del corrente set di caratteri locale esteso. Un carattere esteso ha
un proprio tipo, ossia il tipo
wchar_t, e per indicare che un letterale carattere oppure un letterale stringa trattano caratteri estesi bisogna anteporgli il prefissoL.
In più, per quanto riguarda le funzioni qui dichiarate, è utile dire che:
- la maggior parte di esse si comporta come le equivalenti
funzioni dichiarate in altri header (per esempio
<stdio.h>,<stdlib.h>e<string.h>), con la differenza, però, che i parametri formali e il valore di ritorno saranno di tipowchar_towchar_t *piuttosto che di tipocharochar *; - il loro identificatore potrà contenere, tra gli altri, dei
caratteri come
w,wc,wcs,mbe così via, che indicheranno che si opererà con caratteri estesi e/o caratteri multibyte.
Snippet 11.64 < wchar.h>.
// una stringa "ordinaria"
char n_string[] = "Calcolare: C";
// rapporto 1:1; 1 byte = 1 carattere
size_t t = sizeof (n_string); // 13 byte
// una stringa multibyte con un ideogramma cinese
char mb_string[] = "Calcolare:";
// nel caso dell'ideogramma non c'è un rapporto 1:1 tra un byte e un carattere
t = sizeof (mb_string); // 15 byte
// una stringa wide con un ideogramma cinese
wchar_t w_string[] = L"Calcolare:
// non c'è un rapporto 1:1 tra un byte e un carattere
t = sizeof (w_string); // 26 byte: sul corrente sistema dove un wchar_t
// è dichiarato come uno short int (2 byte)
// 52 byte: su un altro sistema dove wchar_t
// è dichiarato come un int (4 byte)
// ritorna il numero di caratteri estesi che precedono il carattere esteso nullo
// di terminazione della stringa estesa, ossia L'\0'
size_t len = wcslen(w_string); // 12
// il tipo wint_t è un tipo intero grande abbastanza per contenere il valore numerico
// di un corrispondente carattere membro di un set di caratteri esteso
wint_t code = L'
// trova nella stringa estesa il carattere esteso indicato;
// se la ricerca ha esito favorevole è tornato un puntatore a quel carattere esteso,
// altrimenti è ritornato un puntatore nullo
wchar_t *ptr = wcschr(w_string, L'
if(ptr)
{
// se l'ambiente di esecuzione supporta una codifica Unicode allora il seguente
// ideogramma cinese sarà correttamente visualizzato;
// per esempio, nel corrente sistema GNU/Linux, laddove la shell utilizza
// una codifica UTF-8, il programma visualizzerà
// Windows dove la console non supporta una codifica Unicode il programma
// non visualizzerà niente!
char *locale = setlocale(LC_ALL, "");
// come la printf ma manda sullo stdout il contenuto formattato della stringa estesa
// %ls -> per una stringa estesa
// %lc -> per un carattere esteso
// N.B. gli stessi specificatori sono usabili con wscanf
wprintf(L"Il carattere e' [ %ls ]\n", ptr); // Il carattere e' [
}
Utilità per la classificazione e mappatura dei caratteri estesi <wctype.h> (C95)
L’header <wctype.h> definisce la macro
WEOF (si espande in un’espressione costante di tipo
wint_t il cui valore non deve corrispondere a nessun
membro di un set di caratteri esteso ed esprime un end of
file, ossia non c’è più input da uno stream), dichiara i tipi
wint_t (un tipo intero capace di contenere qualsiasi
valore di un corrispondente membro di un set di caratteri esteso),
wctrans_t (un tipo capace di contenere un valore che
rappresenta una modalità di mappatura di un carattere esteso
dipendente dal corrente sistema locale), wctype_t (un
tipo capace di contenere un valore che rappresenta una modalità di
classificazione di un carattere esteso dipendente dal corrente
sistema locale) e delle funzioni categorizzate in: funzioni di
classificazione dei caratteri estesi; funzioni estendibili
di classificazione dei caratteri estesi; funzioni di
mappatura dei caratteri estesi; funzioni estendibili per
la mappatura dei caratteri estesi.
In sostanza questo header fornisce funzionalità similari a
quelle fornite dall’header <ctype.h> ma le
stesse si applicano ai caratteri estesi; infatti, avremo funzioni
di character classification come iswalpha,
iswdigit, iswlower, iswpunct
e così via, e funzioni di character case mapping come
towlower e towupper.
Le funzioni delle categorie ora citate hanno le seguenti
proprietà: il loro comportamento è dipendente dal sistema locale
corrente; tutte, eccetto due, hanno un parametro di tipo
wint_t e dunque il relativo argomento fornito deve
esprimere un carattere esteso (deve essere, per esempio, di tipo
wchar_t o in caso contrario il comportamento non sarà
definito); quelle di classificazione ritornano tutte un valore di
tipo int diverso da 0 (true),
per indicare che il valore dell’argomento è conforme con quanto
indicato da ciascuna, uguale a 0 (false) nel
caso contrario; quelle di conversione ritornano un valore di tipo
wint_t che indica il valore dell’argomento convertito
in minuscolo oppure in maiuscolo.
Questo header fornisce inoltre la possibilità, attraverso le seguenti funzioni dette estensibili, di fornire delle modalità ulteriori per la classificazione e la mappatura dei caratteri estesi (se previsti per il corrente sistema locale).
wctype_t wctype(const char *property): ritorna un valore di tipowctype_tche rappresenta una modalità di classificazione per un carattere esteso previsto per il corrente sistema locale. Il parametropropertyè una stringa che indica la modalità di classificazione da usare per costruire il tipowctype_t, e per lo standard le seguenti stringhe devono sempre essere valide per ogni sistema locale:"alnum","alpha","blank","cntrl","digit","graph","lower","print","punct","space","upper"e"xdigit". Un’implementazione può fornire altre stringhe, e se la stringa utilizzata non è valida per il corrente sistema localewctyperitornerà il valore0.int iswctype(wint_t wc, wctype_t desc): determina se il carattere esteso di cui il parametrowcha le proprietà descritte dal parametrodesc. In effetti un’invocazione, per esempio, della funzioneiswalpha(wc)che determina se il caratterewcha le proprietà descritte dalla modalità di classificazione alpha (è un carattere alfabetico?) è del tutto equivalente in quanto a semantica alla seguente invocazione della funzioneiswctype(wc, wctype("alpha")). Ritorna un valore diverso da0sewcha le proprietà descritte dadesc;0in caso contrario.wctrans_t wctrans(const char *property): ritorna un valore di tipowctrans_tche rappresenta una modalità di mappatura per un carattere esteso previsto per il corrente sistema locale. Il parametropropertyè una stringa che indica la modalità di mappatura da usare per costruire il tipowctrans_t, e per lo standard le seguenti stringhe devono sempre essere valide per ogni sistema locale:"tolower"e"toupper". Un’implementazione può fornire altre stringhe, e se la stringa utilizzata non è valida per il corrente sistema localewctransritornerà il valore0.wint_t towctrans(wint_t wc, wctrans_t desc): determina se il carattere esteso di cui il parametrowcha le proprietà descritte dal parametrodesc. In effetti un’invocazione, per esempio, della funzionetowlower(wc)che converte il caratterewcda maiuscolo a minuscolo è del tutto equivalente in quanto a semantica alla seguente invocazione della funzionetowctrans(wc, wctrans("tolower")). Ritorna il valore mappato diwcutilizzando la modalità di mappatura descritta dadesc.
Snippet 11.65 < wctype.h>.
// in ambiente Windows usare "Italian_Italy.1252"
const char *locale_to_use = "it_IT.utf-8";
// il corrente sistema locale scelto deve influenzare solo la categoria
// che riguarda la classificazione e la conversione dei caratteri
// e dei caratteri multibyte ed estesi
char *locale = setlocale(LC_CTYPE, locale_to_use);
if (locale)
{
wchar_t wc = L'ò';
int r = iswdigit(wc); // 0 ò non è una cifra numerica
r = iswalpha(wc); // != 0 ò è un carattere alfabetico
wint_t up = towupper(wc); // 210 - Ò
int r_2 = iswctype(wc, wctype("digit")); // 0 ò non è una cifra numerica
r_2 = iswctype(wc, wctype("alpha")); // != 0 ò è un carattere alfabetico
wint_t up_2 = towctrans(wc, wctrans("toupper")); // 210 - Ò
}