Capitolo 10
Il preprocessore
Il linguaggio C, come visto in più occasioni, ha delle caratteristiche che lo rendono unico e “speciale” rispetto ad altri linguaggi di programmazione mainstream.
Tra queste, vi è sicuramente la presenza di un tool, denominato preprocessore di C (abbreviato come cpp, che sta per C preprocessor), che compie delle operazioni preliminari di “modifica” del codice sorgente in base a degli appositi comandi, scritti con una particolare sintassi e denominati direttive.
Al termine dell’esecuzione di queste operazioni, effettuate prima della fase di compilazione vera e propria, il sorgente così modificato viene processato dal compilatore stesso, durante la fase di compilazione, per produrre il relativo codice oggetto.
In pratica, possiamo dire che l’input del preprocessore, strumento che in alcune implementazioni dei compilatori è parte del compilatore mentre in altre è un programma a se stante automaticamente invocato, è un file di codice C contenente delle direttive che lo stesso comprende ed esegue e poi al termine della fase di preprocessing rimuove dal sorgente stesso.
Nel contempo, l’output del preprocessore è un altro file di codice C, modificato in accordo con quanto indicato dalla direttive e senza di esse, che viene preso come input dal compilatore il quale compie la consueta operazione di compilazione.
L’ambiente di traduzione di C: un dettaglio
Un’implementazione di un compilatore conforme allo standard esegue, fondamentalmente, un processo di traduzione dei file sorgente, scritti secondo le regole e la sintassi propria di C, e un’operazione di esecuzione dei relativi programmi. In particolare, la fase di esecuzione di un programma avviene nel cosiddetto execution environment (ambiente di esecuzione), mentre la fase di traduzione di un file sorgente avviene in quello che lo standard definisce translation environment (ambiente di traduzione), laddove si hanno diverse fasi ciascuna deputata a compiere una ben specifica operazione. Prima, comunque, di vedere queste fasi di traduzione, appare opportuno ribadire e approfondire anche alcuni termini e step che riguardano la strutturazione di un generico programma in C; abbiamo, infatti, che:
- un testo di un programma è scritto in apposite “unità” chiamate source files (file sorgente) o preprocessing files (file pre-elaborazione);
- un file sorgente, unitamente ad altri file sorgente inclusi
tramite la direttiva
#include(per esempio i file header), è riferito con il termine di preprocessing translation unit (unità di traduzione pre-elaborazione); - dopo la fase di preprocessing l’unità di traduzione pre-elaborazione è chiamata translation unit (unità di traduzione).
Ciò detto, ogni unità di traduzione può comunicare con altre unità di traduzione che hanno funzioni oppure oggetti i cui identificatori hanno un linkage esterno, e ciascuna di queste unità di traduzione può essere tradotta separatamente e poi essere linkata per produrre un programma eseguibile. Per quanto riguarda, quindi, le diverse fasi di traduzione abbiamo le seguenti numerate in ordine di accadimento.
- Mappatura dei caratteri multibyte nel set di caratteri del codice sorgente e sostituzione delle sequenze trigraph con le corrispondenti rappresentazioni interne dei singoli caratteri.
- Localizzazione all’interno del codice sorgente di tutte le
occorrenze del carattere backslash (
\) seguito da un carattere new line (inserito premendo fisicamente sulla tastiera il tasto Invio) e cancellazione degli stessi al fine di creare delle righe logiche al posto delle relative righe fisiche. Questa operazione è altresì conosciuta con il termine di line splicing (congiunzione delle righe). - Scomposizione del contenuto di un file sorgente in: token pre-elaborazione (preprocessing tokens) separati da caratteri di spaziatura; sequenze di caratteri di spaziatura; commenti. Ogni eventuale commento è sostituito da un singolo carattere di spazio, mentre ogni implementazione può scegliere se le sequenze di caratteri di spaziatura saranno sostituite da un singolo carattere di spazio oppure saranno lasciate immutate.
- Elaborazione delle direttive per il preprocessore presenti nel file sorgente ed espansione delle macro. Al termine dell’elaborazione tutte le direttive sono cancellate.
- Conversione di ogni membro del set di caratteri del codice sorgente e delle sequenze di escape presenti nelle costanti carattere e nei letterali stringa con i corrispondenti membri del corrente set di caratteri di esecuzione.
- Concatenazione dei letterali stringa adiacenti.
- Conversione dei token pre-elaborazione in token regolari che saranno sintatticamente e semanticamente analizzati e tradotti come unità di traduzione.
- Risoluzione dei riferimenti agli oggetti e alle funzioni esterne e collegamento con codice di librerie esterne non presenti nella corrente traduzione. Tutto l’output tradotto è poi assemblato in “un’immagine” di un programma che è in grado di eseguirsi nel corrente ambiente di esecuzione.
Delle fasi elencate quelle più importanti sono
la 4, dove interviene il preprocessore, la 7, dove interviene il
compilatore stesso e la 8, dove interviene il linker. Solitamente,
in taluni compilatori, l’invocazione del relativo comando di
compilazione del codice sorgente invocherà, in automatico e a
seconda della fase di traduzione in corso, il programma
preprocessore (per esempio cpp nella suite di
compilazione GCC), il programma compilatore (per esempio
gcc nella suite di compilazione GCC) e il
programma linker (per esempio ld nella suite
di compilazione GCC).
TERMINOLOGIA
Un set di caratteri (character set) nell’ambito di C indica quell’insieme di caratteri che può essere validamente usato nella scrittura di un sorgente, definito dallo standard come source character set (set di caratteri del codice sorgente o di origine), oppure che può essere validamente interpretato ed è dunque disponibile durante l’esecuzione di programma ed è definito dallo standard come execution character set (set di caratteri di esecuzione). Ciascuno dei due set di caratteri è poi diviso in un basic character set (set di caratteri di base) i cui membri sono indicati nella Tabella 10.1, e in 0 o più membri specifici del corrente linguaggio locale definiti come extended characters (caratteri estesi). Inoltre, il set di caratteri di base unitamente ai caratteri estesi disponibili è definito extended character set (set di caratteri estesi).
| Lettere maiuscole e minuscole dell’alfabeto latino | Cifre decimali | Caratteri grafici |
|---|---|---|
| A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z | 0 1 2 3 4 5 6 7 8 9 | ! “ # % & ‘ ( ) * + , - . / : ; < = > ? [ \ ] ^ _ { | } ~ |
NOTA
Ai membri della Tabella 10.1 vanno aggiunti il carattere di spazio (space character) e i caratteri di controllo rappresentanti: la tabulazione orizzontale (horizontal tab); la tabulazione verticale (vertical tab); il salto o avanzamento di pagina (form feed); il segnale d’allerta (alert); la cancellazione dell’ultimo carattere (backspace); il ritorno del carrello (carriage return) e l’avanzamento all’inizio della riga successiva (new line). Infine va anche aggiunto il carattere nullo (null character) utilizzato come marcatore di terminazione di una stringa di caratteri.
Listato 10.1 PreprocessingDirectives.c (PreprocessingDirectives).
/* PreprocessingDirectives.c :: Alcune direttive... :: */
#include <stdio.h>
#include <stdlib.h>
#define SIZE 5
// ??= sequenza di tre caratteri che sta per #
??=define NR 10
int main(void)
{
// due righe "fisiche" separate dal carattere \ e new line
printf("Un programma che mostra come effettuare un ciclo che\
consente di scansionare\nogni elemento di un determinato array!!!\n");
// un array
int data[SIZE] = {1, 2, 3, 4, NR};
// due letterali stringa adiacenti
printf("L'array data contiene i" " seguenti valori: [ ");
for (int i = 0; i < SIZE; i++)
printf("%d ",/* array data */data[i]);
printf("]\n");
return (EXIT_SUCCESS);
}
Output 10.1 Dal Listato 10.1 PreprocessingDirectives.c.
Un programma che mostra come effettuare un ciclo che consente di scansionare
ogni elemento di un determinato array!!!
L'array data contiene i seguenti valori: [ 1 2 3 4 10 ]
Il Listato 10.1 è un semplice programma in C utile solo per dimostrare cosa avviene durante le fasi di traduzione citate. Ne mostriamo alcune significative; per esempio:
- in accordo con la fase 1, la sequenza triplice
??=è sostituita con il carattere#; - in accordo con la fase 2, le due righe fisiche in cui è divisa
la prima istruzione
printf, posta subito dopo ilmain, vengono congiunte per formare una sola riga logica; avremo qualcosa comeprintf("Un programma che mostra come effettuare un ciclo che consente di scansionare\nogni elemento di un determinato array!!!\n");; - in accordo con la fase 3, vengono identificati come token
pre-elaborazione, per esempio, i nomi degli header
<stdio.h>e<stdlib.h>. Inoltre i commenti come nel caso di/* array data */sono sostituiti con un singolo carattere di spazio; - in accordo con la fase 4, le direttive
#includevengono eseguite e le macroSIZEeNRdi cui le direttive#definevengono espanse. Inoltre, tali direttive vengono eliminate dal sorgente dove al loro posto, come è il caso delle direttive#define, sono lasciate delle righe vuote (per le direttive#include, invece, dal punto dove sono indicate viene inserito il testo dei file sorgente che includono); - in accordo con la fase 5, una sequenza di escape
\nè interpretata e convertita con un membro del set di caratteri di esecuzione che esprime lo spostamento del cursore in una nuova riga; - in accordo con la fase 6, i letterali stringa adiacenti
"L'array data contiene i" " seguenti valori: [ "sono concatenati nel seguente modo:"L'array data contiene i seguenti valori: [ "; - in accordo con la fase 7, vengono identificati i token regolari
int,fore così via; - in accordo con la fase 8, viene prodotto in ambiente GNU/Linux
il file eseguibile
PreprocessingDirectives(oPreprocessingDirectives.exein ambiente Windows).
Infine mostriamo un esempio dell’output del preprocessore
cpp così come è espresso grazie all’invocazione del
comando gcc con il flag -E (Shell 10.1),
mantenendo nella funzione main la spaziatura
relativa.
Shell 10.1 Utilizzo di gcc per generare il file di output del preprocessore.
gcc -std=c11 -E PreprocessingDirectives.c -o PreprocessingDirectives.i
Output 10.2 Dal file PreprocessingDirectives.i.
...
[inclusione inline del contenuto dei file header <stdio.h> e <stdlib.h>]
...
int main(void)
{
printf("Un programma che mostra come effettuare un ciclo che consente di scansionare\nogni elemento di un determinato array!!!\n");
int data[5] = {1, 2, 3, 4, 10};
printf("L'array data contiene i" " seguenti valori: [ ");
for (int i = 0; i < 5; i++)
printf("%d ", data[i]);
printf("]\n");
return (0);
}
NOTA
L’Output 10.2 mostra il risultato delle fasi di traduzione dalla 1 alla 4. Non vedremo, quindi, ciò che accadrà nelle altre fasi, come per esempio nella fase 6, dove i letterali stringa adiacenti saranno concatenati.
Concetti preliminari
Una direttiva del preprocessore è rappresentata da una sequenza di elementi lessicali minimi (detti token pre-elaborazione), laddove per la loro corretta scrittura si devono e/o si possono soddisfare determinati requisiti.
- Il primo token della sequenza deve essere il carattere
cancelletto
#che può essere posto come primo carattere oppure come carattere preceduto da caratteri di spaziatura. - Il successivo token deve essere la keyword o il nome della
direttiva (per esempio
define,includee così via) che può essere anche preceduto da caratteri di spaziatura (per esempio è valido scrivere# definepiuttosto che#define). - Gli altri token possono essere qualsiasi ulteriore elemento
lessicale necessario al completamento della sintassi della relativa
direttiva (per esempio un identificatore come
SIZEe un valore numerico come10a completamento di una direttiva#definecome#define SIZE 10). - Tra tutti i token che rappresentano nel complesso una direttiva
del preprocessore può esservi qualsiasi numero di caratteri di
spaziatura arbitrari (per esempio è valido scrivere qualcosa come
# define SIZE 10). - L’ultimo token della sequenza può essere un carattere di new
line, e allora esso marcherà la terminazione della direttiva
stessa. È comunque possibile scrivere i token di una direttiva su
più righe di testo utilizzando il carattere backslash
\e il carattere new line. Questa tecnica è spesso utilizzata per consentire a una direttiva particolarmente lunga di continuare su più righe di testo e rendere più leggibile la sua strutturazione.
Infine, per completezza di trattazione è utile dire che: una
direttiva del preprocessore può essere posta dovunque all’interno
del codice sorgente anche se le direttive #include e
#define sono usualmente poste all’inizio del predetto
codice; è possibile usare i consueti commenti per esplicitare la
semantica di una direttiva.
Definizione di macro
Una macro, denominata anche macroistruzione, è una sequenza arbitraria di token cui viene attribuito un nome che, quando utilizzato nell’ambito del codice sorgente, viene sostituito dal preprocessore da quella esatta sequenza di token.
Detto in termini più pratici, una macro altro non è che un “frammento” di testo con un identificatore che viene inserito nel codice sorgente nell’esatto punto dove è posto tale identificatore che lo denomina, che viene a tal fine eliminato e dunque rimpiazzato.
Object-like macro
Una macro definita nella forma della Sintassi 10.1 è denominata dallo standard come object-like macro (macro simile a oggetto) ed è utilizzata, comunemente, per creare dei nomi simbolici che rappresentano delle costanti numeriche, carattere o stringa.
Questa tipologia di macro, riferita talune volte anche come macro semplice, è denominata object-like macro perché ricorda la definizione di un qualsiasi oggetto del linguaggio come può essere, per esempio, la definizione di una variabile che è caratterizzata, oltre che da un tipo, da un identificatore e da un valore associato.
Sintassi 10.1 Object-like macro.
#define macro_identifier token_replacement_list
La Sintassi 10.1 evidenzia che una macro semplice si definisce
utilizzando, nell’ordine: il carattere cancelletto #,
il nome define, un nome per la macro e una lista di
token.
Il simbolo cancelletto # e la keyword
define rappresentano in modo congiunto la direttiva
del preprocessore #define, mentre per
macro_identifier il nome indicato deve seguire le
stesse regole di scrittura dei comuni identificatori utilizzati per
designare le entità del linguaggio, come gli oggetti, le funzioni,
i tag delle strutture e così via; ciò significa, per esempio, che
tale nome non può essere separato da caratteri di spaziatura, deve
contenere solo lettere, numeri, il carattere underscore
_ e via discorrendo.
Invece, token_replacement_list, è rappresentato da
una sequenza di token pre-elaborazione quali identificatori,
costanti numeriche, costanti carattere, letterali stringa, segni di
punteggiatura e così via.
TERMINOLOGIA
In accordo con lo standard di C, fa parte dei
token pre-elaborazione, ed è dunque utilizzabile con la direttiva
#define, anche quello definito preprocessing
number, che è un token rappresentato da un numero,
opzionalmente preceduto dal carattere punto (.), che
può essere seguito da un qualsiasi altro numero, carattere e
sequenza di caratteri e+, e-,
E+, E-, p+, p-,
P+, o P-. Ciò implica che è valido sia un
comune numero intero come 100 o in virgola mobile come
4.5 sia un “numero” come .314E+1 o
1a2b.
Ciò detto avremo che, durante la fase 4 di traduzione del
codice, il preprocessore, quando nel codice sorgente troverà ogni
occorrenza di macro_identifier la sostituirà con
quanto espresso da token_replacement_list.
TERMINOLOGIA
L’operazione con cui il preprocessore sostituisce ogni occorrenza di un nome di una macro con l’equivalente lista di token è anche detta espansione della macro (macro expansion).
Snippet 10.1 La direttiva #define e alcune macro semplici.
// definizioni di macro semplici; tutte valide
// nell'ambito del codice sorgente dove si troveranno i loro nomi il preprocessore
// li espanderà, letteralmente, con la lista di token definita dopo il nome stesso
#define NR 10 /* una macro per una costante numerica intera */
#define EULER 0.5772 /* una macro per una costante numerica in virgola mobile */
#define TpT 2per2 /* una macro per un preprocessing number */
#define MY_INT int /* una macro per una keyword (è un normale identificatore per il
preprocessore) */
#define LT < /* una macro per un segno di punteggiatura */
#define GT > /* una macro per un segno di punteggiatura */
#define NL '\n' /* una macro per una costante carattere */
#define _WARN_ "warning: " /* una macro per una costante stringa */
#define I_LOOP while(1) /* una macro per un frammento di codice */
// per questa macro tutti gli spazi dopo il nome della macro e dopo la cifra 4
// non sono considerati come parte dell'espansione; allo stesso modo tutti i
// caratteri extra tra la cifra 0 il carattere * e tra lo stesso carattere * e la cifra 4
// non sono considerati, ossia è considerato solo un carattere di spazio di separazione;
// ciò significa che in un sorgente dove avremo qualcosa come int a = SIZE; la stessa
// sarà presentata al compilatore come int a = 10 * 4;
#define SIZE 10 * 4 /* una macro semplice ... */
// attenzione un'implementazione può generare un messaggio come:
// warning: "ONE" redefined
#define ONE 1
#define ONE 2
// ridefinizione consentita!
#define TWO 10
#define TWO 10
#define SIX 3 * 2 /* I definizione */
// per il preprocessore 3*2 è un solo token perché tra 3 * e 2 non vi sono spazi
// infatti per il preprocessore ogni token è numerabile se separato dallo spazio
#define SIX 3*2 /* II definizione warning: "SIX" redefined */
#define SIX 2 * 3 /* III definizione warning: "SIX" redefined */
Lo Snippet 10.1 evidenzia la scrittura di una serie di macro
semplici tutte effettuate seguendo sempre lo stesso pattern che è
caratterizzato dall’indicazione della direttiva
#define, dal nome della macro e da una lista di token
di sostituzione.
Di tutte le macro è interessante notare quelle denominate
ONE e quelle denominate TWO. Nel primo
caso un compilatore come GCC ci avvisa che abbiamo ridefinito una
macro; in questo contesto, per ridefinizione si intende
quell’operazione per cui si definiscono due o più macro con lo
stesso nome ma con una lista di token differente.
In ogni caso, lo standard di C chiarisce la semantica del processo di ridefinizione di una macro asserendo che la stessa è valida solo se le liste di sostituzioni di due o più macro con lo stesso nome sono perfettamente uguali, ossia sono considerate identiche.
Nel secondo caso, infatti, non avremo alcun avviso da parte del
compilatore perché le due macro TWO, quantunque
abbiano lo stesso nome, hanno altresì una lista di token uguali
laddove l’uguaglianza è verificata in merito a quali sono questi
token, al loro numero e al loro ordine di scrittura (per esempio, i
token della lista di sostituzione delle macro denominate
SIX non sono uguali perché la prima definizione ha una
lista di sostituzione con tre token ossia 3,
* e 2, la seconda definizione ha una
lista di sostituzione con un token ossia 3*2 e la
terza definizione ha una lista di sostituzione con 3 token che,
seppur uguali a quelli della prima, sono scritti in ordine diverso
ossia 2, * e 3).
NOTA
Il compilatore GCC, in caso di ridefinizione di più macro, si limiterà a emettere degli appositi warning e utilizzerà, in caso di espansione delle stesse, la lista di token dell’ultima definizione. Altri compilatori potrebbero però segnalare tali ridefinizioni come errore. La morale: seguire ciò che dice lo standard di C ed evitare di ridefinire le macro.
Listato 10.2 ObjectLikeMacro.c (ObjectLikeMacro).
/* ObjectLikeMacro.c :: Un esempio di macro semplici :: */
#include <stdio.h>
#include <stdlib.h>
#define MSG "Questo programma stampera' il totale di due moltiplicazioni \
definite tramite\ndelle direttive #define"
#define SIZE_1 (10 * 2)
#define SIZE_2 (10 * 3)
#define TOT_SIZE SIZE_1 + SIZE_2 /* totale di SIZE_1 con SIZE_2 */
#define PRINT_SIZE printf("Il totale di TOT_SIZE e' %d\n", TOT_SIZE)
int main(void)
{
printf("%s\n", MSG); // espande MSG con l'equivalente letterale stringa
PRINT_SIZE; // espande PRINT_SIZE con gli equivalenti token
#define NR 10 /* questa macro è utilizzabile da qui in poi ... */
return (EXIT_SUCCESS);
}
void foo(void)
{
// qui NR sarà visibile ed espansa con 10
int nr = NR;
}
Output 10.3 Dal Listato 10.2 ObjectLikeMacro.c.
Questo programma stampera' il totale di due moltiplicazioni definite tramite
delle direttive #define
Il totale di TOT_SIZE e' 50
Il Listato 10.2 definisce, in primo luogo, la macro
MSG che sarà espansa con tutti i caratteri costituenti
il relativo letterale stringa doppi apici "
inclusi.
In questo caso è interessante rilevare l’utilizzo dei caratteri
backslash \ e new line che ci hanno permesso di
dividere su due righe fisiche quella stringa particolarmente lunga;
tuttavia, come già detto, questo non rappresenta un problema
sintattico perché durante la fase 2 di traduzione quei caratteri
saranno eliminati e sarà creata un’unica riga logica.
A tal fine è importante dire che ogni direttiva del
preprocessore terminerà quando lo stesso troverà il primo carattere
di new line posto dopo il carattere #; per
MSG tale new line di terminazione della direttiva sarà
quello posto dopo il carattere " di chiusura della
relativa stringa e non quello posto dopo il carattere backslash \
perché, ribadiamo, quest’ultimo ci ha permesso di dividere, senza
errori, il contenuto di una riga lunga su più righe oppure, detto
in altro modo, di “continuare” una direttiva su una successiva
riga.
Per la definizione delle macro SIZE_1 e
SIZE_2 non c’è molto da dire e, infatti, esse saranno
espanse, letteralmente con (10 * 2) e (10 *
3). Le macro TOT_SIZE e PRINT_SIZE
mostrano, invece, come sia possibile definire, rispettivamente,
delle liste di sostituzione con altre macro oppure con token e
altre macro.
In ambedue i casi quando il preprocessore incontrerà nell’ambito
del codice sorgente quelle macro provvederà a effettuare delle
espansioni ricorsive: così, per esempio, quando nell’ambito della
funzione main incontrerà PRINT_SIZE la stessa sarà
espansa utilizzando i seguenti step di elaborazione:
printf("Il totale di TOT_SIZE e' %d\n", TOT_SIZE).printf("Il totale di TOT_SIZE e' %d\n", SIZE_1 + SIZE_2).printf("Il totale di TOT_SIZE e' %d\n", (10 * 2) + (10 * 3)).
Dal processo di espansione mostrato è importante rilevare come,
per esempio, la sostituzione di TOT_SIZE non è stata
effettuata all’interno del letterale stringa passato come argomento
alla funzione printf; infatti, le sostituzioni di
macro riguardano solo i token e non i caratteri eventualmente
presenti all’interno di una coppia di doppi apici.
NOTA
Se nel codice sorgente avessimo trovato qualcosa
come MY_TOT_SIZE la sostituzione “parziale” di
TOT_SIZE non sarebbe avvenuta.
MY_TOT_SIZE, infatti, rappresenta un identificatore
ben diverso da TOT_SIZE.
Infine, la funzione main definisce la macro
NR che è visibile, indipendentemente da tale blocco
main, dal suo punto di definizione e fino al termine
della corrente unità di traduzione pre-elaborazione oppure fino a
una corrispondente direttiva #undef.
In conclusione, le macro semplici, sono un pratico strumento
utilizzato soprattutto per definire delle costanti simboliche e, in
tal caso, consentono di raggiungere diversi obiettivi tra i quali:
rendono un programma “più leggibile” perché permettono di non
inserire direttamente nel codice numeri, caratteri o stringhe (un
nome di una macro come EULER è di sicuro più
significativo del numero 0.5772); rendono un programma
“più manutenibile” perché se dobbiamo cambiare un valore che è
utilizzato innumerevoli volte nell’ambito di un sorgente è più
facile farlo una sola volta nella definizione della relativa macro
piuttosto che in tutte le sue occorrenze “fisiche”.
CURIOSITÀ
La comunità di programmatori in C usa scrivere il nome di una macro che rappresenta una costante simbolica con tutte le lettere in maiuscolo. Probabilmente tale convenzione è stata adottata perché è quella consigliata da Kernighan e Ritchie nel loro famoso libro Linguaggio C, dove è detto: “i nomi delle costanti simboliche sono scritti per convezione in maiuscolo perché è più immediato distinguerli dai nomi delle variabili che sono invece scritti per convenzione in minuscolo”.
Function-like macro
Una macro definita nella forma della Sintassi 10.2 è denominata dallo standard come function-like macro (macro simile a funzione) ed è utilizzata, comunemente, per creare delle “piccole funzioni” deputate a svolgere semplici elaborazioni.
Questa tipologia di macro, riferita talune volte anche come
macro parametrica o macro con argomenti, è
denominata function-like macro sia perché la sua definizione
ricorda quella di una comune funzione del linguaggio – dove è cioè
presente un nome, una coppia di parentesi tonde ( ),
una lista di parametri formali e un corpo di istruzioni – sia anche
perché il suo utilizzo è sintatticamente uguale a quello delle
comuni funzioni, ossia si scrive il suo nome e una coppia di
parentesi tonde ( ) al cui interno si inseriscono gli
eventuali argomenti.
Sintassi 10.2 Function-like macro.
#define macro_identifier([identifier_list]) replacement_list
In pratica, come da Sintassi 10.2, una macro parametrica si
definisce utilizzando la direttiva del preprocessore
#define, un identificatore espresso tramite
macro_identifier, una coppia di parentesi tonde
( ) – laddove quella di sinistra ( deve
essere scritta subito dopo l’identificatore senza cioè che tra di
essi vi siano caratteri di spaziatura – una lista di token che
saranno sostituiti a macro_identifier in rapporto alla
“chiamata” della macro.
Per quanto concerne identifier_list, essa
rappresenta quell’insieme degli identificatori dei parametri
formali che possono essere replicati in
replacement_list in modo che durante l’invocazione
della macro parametrica gli stessi siano sostituiti dai
corrispettivi argomenti per questo forniti.
In più, identifier_list può essere anche opzionale,
ossia è possibile scrivere durante la definizione della relativa
macro la coppia di parentesi tonde senza tale lista, cosi che
durante l’invocazione della macro non si renda necessario fornire
alcun argomento.
IMPORTANTE
Bisogna rammentare che una macro parametrica “sembra essere” una comune funzione, soprattutto nella sua fase di utilizzo ma, nella realtà, “non è” come tale. In effetti, il preprocessore quando troverà una macro parametrica non farà altro che porre in essere le consuete sostituzioni già viste pe le macro semplici le quali, però, a differenza di quelle effettuate per quest’ultime, saranno parametriche.
Listato 10.3 FunctionLikeMacro.c (FunctionLikeMacro).
/* FunctionLikeMacro.c :: Un esempio di macro parametriche :: */
#include <stdio.h>
#include <stdlib.h>
// una serie di macro parametriche
#define max(x, y) ((x) > (y) ? (x) : (y)) /* calcola il massimo tra due numeri */
#define cube(x) ((x) * (x) * (x)) /* calcola il cubo di un numero */
#define c_print(c) printf("%c\n", c) /* visualizza un carattere... */
#define i_print(i) printf("%d\n", i) /* visualizza un intero... */
#define nl() printf("\n") /* stampa un carattere di new line */
int main(void)
{
printf("Di seguito il risultato dell'invocazione di alcune macro parametriche:");
nl(); /* nl sarà espansa come printf("\n") */
int j = 10, p = 11;
// m conterrà come valore 11 perché p è maggiore di j!
int m = max(j, p); /* max sarà espansa come ((j) > (p) ? (j) : (p)) */
// c conterrà come valore 1000 che è il cubo di j
int c = cube(j); /* cube sarà espansa come ((j) * (j) * (j)) */
char a_char = 'A';
c_print(a_char); /* c_print sarà espansa come printf("%c\n", a_char) */
i_print(j); /* i_print sarà espansa come printf("%d\n", j) */
return (EXIT_SUCCESS);
}
Output 10.4 Dal Listato 10.3 FunctionLikeMacro.c.
Di seguito il risultato dell'invocazione di alcune macro parametriche:
A
10
Il Listato 10.3 definisce la serie di macro parametriche
max, cube, c_print,
i_print e nl che si comportano come se
fossero delle funzioni che, rispettivamente, ritornano il massimo
tra due numeri, ritornano il cubo di un numero, visualizzano un
carattere e inviano un carattere di new line, visualizzano un
intero e inviano un carattere di new line, inviano un carattere di
new line.
Per comprendere come avviene la sostituzione di una macro
parametrica possiamo prendere come esempio quella denominata
max: gli identificatori x e
y posti tra le parentesi tonde ( ) di
definizione sono “replicati” nell’ambito del corpo delle istruzioni
che ne rappresenta sia il processo elaborativo sia la lista di
sostituzione.
Dunque, quando durante la fase 4 di traduzione il preprocessore
troverà nell’ambito della funzione main la definizione
max(j, p), la cancellerà e la sostituirà con la sua
replacement list laddove tutte le occorrenze dell’identificatore
del parametro x saranno sostituite con
l’identificatore j e tutte le occorrenze
dell’identificatore del parametro y saranno sostituite
con l’identificatore p.
In definitiva la chiave di scrittura di una macro parametrica è la seguente: gli argomenti forniti all’atto della sua invocazione saranno sempre sostituiti ai corrispondenti parametri e ne prenderanno, quindi, il loro posto.
Scorrendo ulteriormente il sorgente del Listato 10.3 notiamo
altresì come, nell’ambito delle liste di sostituzione, gli
identificatori dei parametri delle macro max e
cube siano stati posti tra una coppia di parentesi
tonde ( ) e lo stesso è stato fatto per tutte le liste
di sostituzione ossia sono state esse stesse racchiuse tra tali
parentesi.
Per comprenderne la motivazione vediamo cosa accadrebbe se
definissimo la macro parametrica cube come nello
Snippet 10.2, ossia senza quelle parentesi tonde, e la usassimo poi
per calcolare il cubo di valore dato da un’espressione come, per
esempio, j + 3.
Snippet 10.2 Parentesi mancanti attorno ai parametri di una lista di sostituzione.
...
// cube scritta in modo errato!!!
#define cube(x) x * x * x /* calcola il cubo di un numero */
int main(void)
{
int j = 10;
// m avrà come valore 73!
int m = cube(j + 3); /* cube sarà espansa come j + 3 * j + 3 * j + 3 */
...
}
In pratica senza parentesi il preprocessore sostituirà
cube(j + 3) con j + 3 * j + 3 * j + 3.
Dopodiché, tale espressione verrà valutata dal compilatore, il
quale, in accordo con le consuete regole di precedenza e
associatività, produrrà come valore 73 (in pratica
saranno prima eseguite le moltiplicazioni tra 3 e
j e poi le addizioni tra quei risultati e i rimanenti
operandi). Chiaramente quello non era il risultato atteso perché
noi avremmo voluto avere la computazione del cubo di j +
3 che avrebbe dovuto dare come valore 2197 che
è, per l’appunto, il cubo di 13 laddove
13 è il risultato di j + 3 dove
j vale 10.
Ecco quindi l’importanza delle parentesi tonde ( )
poste attorno ai parametri di una lista di sostituzione; esse
consentono di rispettare l’ordine di valutazione desiderato e
atteso.
Ancora, vediamo lo Snippet 10.3 che mostra cosa accadrebbe se
definissimo la macro parametrica cube senza le
parentesi tonde che racchiudono tutta la relativa lista di
sostituzione e la usassimo per calcolare un valore che è il
risultato di un altro valore diviso per il cubo di un altro
valore.
Snippet 10.3 Parentesi mancanti attorno alla lista di sostituzione.
...
// cube scritta in modo errato!!!
#define cube(x) (x) * (x) * (x) /* calcola il cubo di un numero */
int main(void)
{
int j = 10;
int val = 10000;
// m avrà come valore 100000!
int m = val / cube(j); /* cube sarà espansa come (j) * (j) * (j) */
...
}
In questo caso senza parentesi il preprocessore sostituirà
cube(j) con (j) * (j) * (j). Dopodiché,
tale espressione verrà valutata dal compilatore unitamente a
val e all’operatore di divisione /, il
quale, in accordo con le consuete regole di precedenza e
associatività, produrrà come valore 100000 (in pratica
sarà prima eseguita la divisione tra val e la prima
occorrenza di j e poi le moltiplicazioni tra quel
risultato e i valori espressi dalle altre due occorrenze di
j). Chiaramente, anche qui, quello non era il
risultato atteso perché noi avremmo voluto avere la computazione
del valore di val diviso per il cubo di j
che avrebbe dovuto dare come valore 10 risultante, per
l’appunto, dal valore di val, che vale
10000, diviso per il cubo di j che è
1000 perché j vale 10.
Vediamo, inoltre, un altro esempio di codice (Snippet 10.4) che evidenzia un’ulteriore problematica legata, questa volta, a un utilizzo di una macro parametrica con un argomento che produce un side-effect.
Snippet 10.4 Risultati non voluti prodotti da valutazioni di argomenti che producono side-effect.
...
#define max(x, y) ((x) > (y) ? (x) : (y)) /* calcola il massimo tra due numeri */
int main(void)
{
int j = 100, p = 50;
// m conterrà come valore quello di j che è più grande del valore di p
// m conterrà quindi il valore 101 per effetto dell'incremento di j avuto
// durante la valutazione dell'espressione (j++) > (p)
int m = max(j++, p); /* max sarà espansa come ((j++) > (p) ? (j++) : (p)) */
// j_val conterrà 102 perché j è stato valutato 2 volte al termine della valutazione
// di tutta la full expression che ricordiamo marca un sequence point
int j_val = j;
...
}
In pratica quando la macro parametrica max viene
invocata come max(j++, p) il compilatore si trova ad
analizzare l’espressione ((j++) > (p) ? (j++) :
(p)), conseguenza dell’espansione effettuata dal
preprocessore, dove è evidente come l’argomento j
viene incrementato di un’unità per ben due volte; la prima volta
durante la valutazione del primo operando dell’operatore
condizionale, ossia (j++) > (p), e la seconda volta
durante la valutazione del secondo operando dello stesso operatore
ossia (j++). Quanto detto, è poi dimostrato dalla
successiva operazione di assegnamento dove il valore della
variabile j_val è 102 ossia quanto
contenuto nella predetta variabile j.
Anche in questo caso quello che avremmo voluto era semplicemente
che m avesse contenuto il valore più grande tra
j e p, senza però che durante quella
valutazione il valore di j fosse incrementato. Allo
stesso tempo, comunque, per effetto dell’operatore di incremento
postfisso ++ il valore di j avrebbe
potuto contenere il valore 101 che sarebbe stato
assegnato lecitamente alla variabile j_val.
Quanto indicato è proprio il risultato che sarebbe stato
garantito se avessimo definito max non come una macro
parametrica ma come una normale funzione.
Snippet 10.5 Correttezza di risultato in caso max fosse una normale funzione.
...
// prototipo di max
int max(int x, int y);
int main(void)
{
int j = 100, p = 50;
// m conterrà come valore quello di j che è più grande del valore di p
// m conterrà quindi il valore 100 e non 101 perché l'operatore di incremento
// sull'argomento j è postfisso e non prefisso
int m = max(j++, p);
// j_val conterrà 101 a causa dell'operatore di incremento postfisso applicato
// sull'argomento j che ricordiamo è stato comunque effettuato perché vi è un
// sequence point prima dell'ingresso nella funzione max ossia dopo la valutazione
// dei suoi argomenti e prima dell'esecuzione delle espressioni nel suo body
int j_val = j;
...
}
// definizione di max
int max(int x, int y)
{
return x > y ? x : y;
}
CURIOSITÀ
Rispetto alla convenzione di scrittura evidenziata in precedenza per le macro semplici, che è in modo abbastanza uniforme accettato dalla comunità di programmatori in C, quella adottata per la scrittura delle macro parametriche è invece divergente. Alcuni, cioè, preferiscono scrivere gli identificatori delle macro parametriche con le lettere tutte in maiuscolo, mentre altri preferiscono adottare lo stile adottato nel già citato libro sul C di Kernighan e Ritchie, dove gli identificatori delle macro parametriche sono scritti con le lettere tutte in minuscolo.
Macro con argomenti di lunghezza variabile
A partire dallo standard C99, una macro parametrica può essere anche definita con la possibilità di accettare un numero variabile di argomenti (Sintassi 10.3).
Sintassi 10.3 Function-like macro con un numero variabile di argomenti.
#define macro_identifier([identifier_list], ...) replacement_list
In pratica per definire una macro parametrica e
variadica è sufficiente compiere i seguenti passi:
utilizzare il token rappresentato dai punti di sospensione
... (ellissi) scritti al termine di un’eventuale lista
di identificatori per indicare che la relativa macro è in grado di
accettare un numero variabile di argomenti; impiegare lo speciale
identificatore __VA_ARGS__ scritto nella lista di
sostituzione per indicare quell’insieme di argomenti, il cui numero
non è noto a priori, che prenderanno il suo posto all’atto di
invocazione della relativa macro.
TERMINOLOGIA
Anche se non espressamente riferito nello standard, è diventata prassi comune indicare una macro parametrica che accetta un numero variabile di argomenti con il termine di macro variadica. Allo stesso modo una funzione che accetta un numero variabile di argomenti è spesso citata con il termine di funzione variadica.
Listato 10.4 VariadicMacro.c (VariadicMacro).
/* VariadicMacro.c :: Macro parametriche e variadiche :: */
#include <stdio.h>
#include <stdlib.h>
// debug può accettare un numero variabile di argomenti...
// è interessante notare l'uso di un do/while subito "falso", che è un'utile
// tecnica che permette di raggruppare più istruzioni in modo che le stesse
// possano essere utilizzate senza problemi anche in istruzioni if;
// se, infatti, avessimo definito la macro debug come:
// #define debug(...) { \
// printf("Nella funzione %s: ", __func__);\
// printf(__VA_ARGS__); \
// }
// e l'avessimo usata in un'istruzione if come nel seguente modo:
// if (is_debug)
// debug("a=%d\n", a);
// else
// ...
// il preprocessore l'avrebbe sostituita nel seguente modo:
// if(is_debug)
// { printf("Nella funzione %s: ", __func__); printf("a=%d\n", a); };
// else
// ...
// e il compilatore per effetto dell'istruzione nulla rappresentata dal
// punto e virgola messo dopo la parentesi } avrebbe generato il messaggio
// error: 'else' without a previous 'if'
#define debug(...) do \
{ \
printf("Nella funzione %s: ", __func__);\
printf(__VA_ARGS__); \
} while(0)
// prototipo di foo
void foo(void);
int main(void)
{
int a = 10;
int b = 11;
// debug sarà espansa come:
// do { printf("Nella funzione %s: ", __func__); printf("[a = %d] [b = %d]\n", a, b); }
// while(0);
debug("[a = %d] [b = %d]\n", a, b);
foo();
return (EXIT_SUCCESS);
}
// definizione di foo
void foo(void)
{
int x = 100, y = 101, z = 102;
// debug sarà espansa come:
// do { printf("Nella funzione %s: ", __func__); printf("[x = %d] [y = %d]
// [z = %d]\n", x, y, z); } while(0);
debug("[x = %d] [y = %d] [z = %d]\n", x, y, z);
}
Output 10.5 Dal Listato 10.4 VariadicMacro.c.
Nella funzione main: [a = 10] [b = 11]
Nella funzione foo: [x = 100] [y = 101] [z = 102]
Il Listato 10.4 definisce la macro parametrica
debug in modo che possa accettare un numero variabile
di argomenti e che abbia come scopo quello di stampare a video il
nome della corrente funzione di esecuzione, tramite
l’identificatore predefinito __func__, e il nome di un
numero arbitrario di variabili unitamente al loro valore.
In ambedue i casi, nell’ambito della lista di sostituzione,
utilizziamo l’istruzione printf che è essa stessa
definita come una funzione in grado di accettare un numero
variabile di argomenti e, soprattutto nel secondo caso, si presta
bene all’impiego dell’identificatore __VA_ARGS__ che
gli può fornire, per l’appunto, un qualsiasi numero di
argomenti.
Per esempio, quando nella funzione main verrà
invocata la macro parametrica debug, tutti i suoi
argomenti, ossia il letterale stringa, l’identificatore della
variabile a e l’identificatore della variabile
b, unitamente al carattere virgola (,) di
separazione, sostituiranno nella seconda printf posta
all’interno del do/while l’identificatore
__VA_ARGS__.
DETTAGLIO
L’identificare __func__ è stato
introdotto con lo standard C99 e ogni implementazione ne deve
perciò fornire una dichiarazione implicita. In pratica, esso deve
essere dichiarato come se ogni funzione avesse come prima
istruzione del suo body qualcosa come static const char
__func__[] = "function_name"; dove
function_name è il nome della relativa funzione.
ATTENZIONE
L’identificatore __func__ non è in
alcun modo correlato al preprocessore. Infatti durante la fase 4 di
traduzione tale identificatore non viene espanso con il nome della
corrente funzione.
Macro con argomenti “vuoti”
Dallo standard C99 è possibile invocare una macro parametrica che accetta argomenti omettendone uno o più di uno; in ogni caso, per un corretto utilizzo di questa caratteristica bisogna prestare attenzione a che la macro non sia espansa in modo invalido, dal punto di vista del compilatore, oppure che contenga, nel caso di una macro con due o più argomenti, la giusta quantità di virgole di separazione tra gli stessi in modo che il preprocessore medesimo non la ritenga altresì invalida.
Se, invece, una macro parametrica invocata senza l’indicazione di uno o più argomenti è valida per il preprocessore, lo stesso effettuerà la consueta espansione, eliminando però dalla lista di sostituzione ogni riferimento di uno o più corrispettivi parametri.
Snippet 10.6 Invocazione di una macro parametrica omettendo degli argomenti.
...
// una macro parametrica con due argomenti
#define min(x, y) ((x) < (y) ? (x) : (y))
int main(void)
{
int a = 10, b = 11;
// omesso il primo argomento;
// il suo corrispettivo parametro, ossia x, sarà eliminato dalla lista
// di sostituzione;
// il sorgente non sarà compilabile perché la macro espansa non sarà valida
// error: expected expression before ')' token
int min_1 = min(, b); /* min sarà espansa come (() < (b) ? () : (b)); */
// omesso il secondo argomento;
// il suo corrispettivo parametro, ossia y, sarà eliminato dalla lista
// di sostituzione;
// il sorgente non sarà compilabile perché la macro espansa non sarà valida
// error: expected expression before ')' token
int min_2 = min(a,); /* min sarà espansa come ((a) < () ? (a) : ()); */
// attenzione l'omissione di tutti e due gli argomenti senza indicazione
// del carattere , di separazione fa generare un errore anche da parte del
// preprocessore: error: macro "min" requires 2 arguments, but only 1 given
int min_3 = min(); /* min sarà espansa come (() < () ? () : ()); */
// omessi il primo e il secondo argomento;
// i suoi corrispettivi parametri, ossia x e y, saranno eliminati dalla
// lista di sostituzione;
// il sorgente non sarà compilabile perché la macro espansa non sarà valida
// error: expected expression before ')' token
int min_4 = min(,); /* min sarà espansa come (() < () ? () : ()); */
...
}
Lo Snippet 10.6 definisce la macro parametrica min
che ritorna il più piccolo tra due valori. La funzione
main dichiara quindi le variabili a e
b da comparare e invoca la macro min più
volte e in modo differente in quanto a indicazione dei relativi
argomenti.
Tutte quelle invocazioni di min, però, presentano
dei problemi di invalidità rilevate sia dal compilatore (è il caso
della prima, seconda e quarta invocazione dove le macro, una volta
espanse, mostrano dei problemi sintattici) sia dal preprocessore (è
il caso della terza invocazione dove l’espansione non viene neppure
elaborata, sempre per problemi sintattici, e la compilazione si
ferma durante la fase 4 di traduzione).
In pratica, per il preprocessore non sarà mai considerato un errore l’omissione di uno o più argomenti durante un’invocazione di una macro parametrica ma solo se si scriverà l’esatta quantità di virgole di separazione tra di essi; per esempio, per una macro con due argomenti bisognerà indicare una sola virgola, per una macro con tre argomenti bisognerà indicare due virgole e così via per gli altri casi.
NOTA
Se la macro accetta un solo argomento è possibile
ometterlo scrivendo l’identificatore della macro e le parentesi
tonde ( ) di invocazione vuote. Così, se è definita
una macro parametrica come #define QUAL(q) q sarà
possibile scrivere, in modo valido, qualcosa come
QUAL().
Macro parametriche e funzioni
Le macro parametriche hanno dei vantaggi rispetto alle normali funzioni che possiamo riepilogare come segue.
- Essendo espanse inline evitano l’overhead causato dall’invocazione delle normali funzioni. Quando una macro parametrica è invocata innumerevoli volte (si pensi al suo utilizzo in un’istruzione di iterazione), il programma può risultare più veloce rispetto a se la stessa fosse scritta come una funzione e invocata come tale.
- Permettono di utilizzare dati indipendenti dal tipo. È
possibile, cioè, scrivere macro parametriche “generiche” che
operano su tipi di dato differenti (si pensi alla funzione
minappena presentata e al fatto che può ritornare il minimo tra due tipiint,float,doublee così via).
Allo stesso tempo le macro parametriche hanno anche, sempre rispetto alle normali funzioni, i seguenti svantaggi.
- Possono provocare un aumento di dimensione del codice sorgente e di conseguenza del codice compilato. Ciò è tanto più evidente se si utilizzano molte macro parametriche quando le relative liste di sostituzione sono inserite inline in molti punti del codice sorgente.
- Non vi è un type checking degli argomenti e neppure
un’eventuale conversione verso i tipi dei rispettivi parametri.
Quest’assenza di controllo sui tipi può chiaramente provocare dei
problemi soprattutto se i tipi utilizzati sono differenti (si pensi
alla macro
mine alla possibilità di passare come argomenti un tipointe un tipo array i cui elementi sono di tipochar). - Gli argomenti possono essere valutati più di una volta causando ogni tanto dei comportamenti non attesi soprattutto in presenza di side-effect (vedere, a tal proposito, lo Snippet 10.4 presentato in precedenza).
In buona sostanza, prima di decidere se usare una macro parametrica rispetto a una normale funzione bisogna sempre valutare quali sono gli obiettivi che vogliamo raggiungere e se i relativi svantaggi sono accettabili per il particolare processo computazionale che intendiamo rappresentare e dunque codificare.
NOTA
Ricordiamo che da C99 è possibile utilizzare le funzioni inline per scrivere “piccole” funzioni che consentono di evitare il consueto overhead legato all’invocazione di normali funzioni, rendendole preferibili rispetto alle macro parametriche. In ogni caso, prima di decidere se privilegiare una funzione inline rispetto a una macro parametrica, rammentiamo che bisogna tener presente che il comportamento di un compilatore rispetto a una funzione inline è implementation-defined, ossia può tanto decidere di “espandere” inline il codice che è parte del suo body quanto decidere di non far nulla.
La direttiva #undef
La direttiva del preprocessore #undef (Sintassi
10.4) permette di rimuovere una definizione di una macro, sia
semplice sia parametrica, ossia provoca l’annullamento del suo
identificatore che non può, quindi, dal quel punto in poi, essere
più utilizzato (tranne, chiaramente, se non se ne fornisce un’altra
definizione).
Sintassi 10.4 La direttiva #undef.
#undef macro_identifier
In genere la direttiva #undef si usa sia per
rimuovere una definizione di una macro già esistente per la quale
si desidera dare una nuova definizione (ricordiamo che per lo
standard è lecito ridefinire una macro solo se le liste di
sostituzione sono uguali) sia per garantire che un certo nome
denoti un identificatore di una funzione piuttosto che quello di
una macro parametrica (Snippet 10.7).
Snippet 10.7 Utilizzo di #undef.
...
#include <ctype.h>
// macro parametrica per determinare se un carattere è una cifra decimale
#define isdigit(y) ((y) >= '0' && (y) <= '9' ? 1 : 0)
int main(void)
{
char a = '8';
// qui userà la macro parametrica isdigit
printf("%d\n", isdigit(a)); // 1
#undef isdigit /* annullamento definizione della macro isdigit */
char b = 'a';
// qui userà la funzione isdigit dichiarata nel file header <ctype.h>
printf("%d\n", isdigit(b)); // 0
...
}
NOTA
Se si utilizza la direttiva #undef
con un identificatore non definito oppure che non rappresenta una
macro, non accadrà nulla: la direttiva sarà senza effetto e il
preprocessore non genererà alcun avviso diagnostico.
L’operatore hash #
È possibile utilizzare nell’ambito di una lista di sostituzione
di una macro parametrica lo speciale operatore del preprocessore
avente come simbolo il carattere hash #.
Quest’operatore applicato in modo prefisso all’identificatore di un parametro della macro fa sì che del corrispettivo argomento venga creato un letterale stringa, e tale letterale venga inserito al posto del predetto parametro.
TERMINOLOGIA
Il processo di creazione di un letterale stringa di un argomento di una macro è definito dallo standard come stringizing.
Un utilizzo piuttosto ricorrente dell’operatore #
si ha quando si ha la necessità di creare una macro parametrica
laddove un’istruzione come printf possa mandare a
video delle informazioni di debug che contengano letteralmente il
“nome” dell’espressione che si sta controllando (Snippet 10.8).
Snippet 10.8 Utilizzo dell’operatore #.
...
// una macro parametrica
#define debug(expr) printf(#expr " = %d\n", expr)
int main(void)
{
int a = 100;
// in questo caso #expr sarà sostituita da "a"
debug(a); /* debug sarà espansa come printf("a" " = %d\n", a); */
int b = 200;
// in questo caso #expr sarà sostituita da "b"
debug(b); /* debug sarà espansa come printf("b" " = %d\n", b); */
// in questo caso #expr sarà sostituita da "b / a"
debug(b / a); /* debug sarà espansa come printf("b / a" " = %d\n", b / a); */
...
}
IMPORTANTE
Se come argomento di una macro parametrica che
usa l’operatore # non forniamo nulla (argomento
vuoto), allora il risultato sarà una stringa vuota "".
Per esempio, se definiamo la macro #define P(p) #p e
poi la invochiamo come in char eS[] = P();, tale
istruzione sarà presentata al compilatore come char eS[] =
"";.
L’operatore doppio hash ##
È possibile utilizzare nell’ambito di una lista di sostituzione
di una macro parametrica oppure di una macro semplice lo speciale
operatore del preprocessore avente come simbolo il doppio carattere
hash ##.
Quest’operatore consente di concatenare i due token pre-elaborazione tra i quali è posto in modo da formare un solo token.
Ciò significa, per esempio, che se un token è l’identificatore di un parametro della macro e un altro token è un valore numerico qualsiasi, quando la macro sarà invocata il parametro sarà sostituito dal corrispettivo argoment, che sarà altresì “fuso” con tale valore numerico in modo da formare un unico token.
TERMINOLOGIA
Il processo di creazione di un solo token risultato della concatenazione di due token è definito dallo standard come token pasting.
Snippet 10.9 Utilizzo dell’operatore ##.
...
// una macro parametrica che consente di creare una serie di funzioni min ciascuna
// con il proprio identificatore e capace di processare lo specifico tipo di dato
#define makeMin(type) \
type type##Min(type x, type y) \
{ \
return x < y ? x : y; \
}
// makeMin sarà espansa come:
// int intMin(int x, int y) { return x < y ? x : y; }
makeMin(int)
// makeMin sarà espansa come:
// double doubleMin(double x, double y) { return x < y ? x : y; }
makeMin(double)
int main(void)
{
int a = 10, b = 11;
int min_1 = intMin(a, b); // 10
double m = 10.11, n = 22.11;
double min_2 = doubleMin(m, n); // 10.11
...
}
Lo Snippet 10.9 mostra un interessante esempio di una macro
parametrica, makeMin, che è capace di creare delle
definizioni di funzioni ciascuna con un proprio identificatore e
ciascuna deputata a ritornare un risultato che è il valore minimo
tra due valori laddove ogni valore è di uno specifico tipo di
dato.
Al fine di far generare un identificatore sempre diverso per
ogni definizione di funzione creata, la macro makeMin
usa, nell’ambito della lista di sostituzione, l’operatore
## con i token type e Min,
dove type è l’identificatore di un parametro mentre
Min è una serie arbitraria di caratteri.
Ciò implicherà che, quando per esempio sarà invocata la macro
makeMin(int), l’argomento int sarà
sostituito al parametro type e poi sarà concatenato
con Min per formare il token intMin. Lo
stesso procedimento avverrà con l’invocazione di
makeMin(double), dove al termine dell’operazione di
pasting si avrà il token doubleMin.
IMPORTANTE
Se come argomento di una macro parametrica che
usa l’operatore ## non forniamo nulla (argomento
vuoto), allora tale argomento sarà sostituito da uno speciale token
“invisibile” chiamato placemarker token che sarà, poi,
concatenato con un token ordinario e ritornerà quel token
originario (Snippet 10.10). Se invece a essere concatenati sono due
placemarker token, perché per esempio abbiamo invocato un macro con
due argomenti vuoti, allora sarà ritornato un singolo placemarker
token. In ogni caso, al termine dell’espansione della macro, ogni
eventuale placemarker token sarà rimosso.
Snippet 10.10 Placemarker token.
...
#define list(x,y,z) x##y##z
int main(void)
{
// alla fine delle espansioni data sarà visto dal compilatore come:
// int data[] =
// {
// 123,
// 13,
// 23,
// 12,
// 1,
// 2,
// 3,
//
// };
// da notare lo spazio "vuoto" dopo 3, lasciato dal preprocessore
// a seguito dell'espansione di list(,,)
int data[] =
{
list(1, 2, 3), /* list sarà espansa come 123 */
list(1,, 3), /* list sarà espansa come 13 */
list(, 2, 3), /* list sarà espansa come 23 */
list(1, 2,), /* list sarà espansa come 12 */
list(1,,), /* list sarà espansa come 1 */
list(, 2,), /* list sarà espansa come 2 */
list(,, 3), /* list sarà espansa come 3 */
list(,,) /* espansione "vuota"... */
};
...
}
Espressioni di selezioni generiche
A partire dallo standard C11 è stata introdotta la keyword
_Generic (Sintassi 10.5) che permette di costruire
un’espressione che è generica rispetto a un determinato
tipo di dato (type-generic expressions), ossia che è in
grado di ritornare un determinato valore in base, per l’appunto, a
uno specifico tipo di dato fornito come “valore” di input.
TERMINOLOGIA
Lo standard C11 utilizza anche il termine di generic selection expression (espressione di selezione generica) per indicare un’espressione di tipo generico che “seleziona” un valore in base al tipo di un’espressione.
Sintassi 10.5 _Generic.
_Generic(controlling_expression, type_name: assignment_expression, type_name_other: assignment_expression, default: assignment_expression)
Per definire un’espressione di selezione generica bisogna
utilizzare la keyword _Generic e una coppia di
parentesi tonde ( ) al cui interno porre i seguenti
elementi separati dal carattere virgola (,).
- Una controlling expression, ossia un’espressione di
controllo utilizzata per la determinazione di uno specifico tipo di
dato. Questa espressione non è comunque valutata, ossia se si
fornisce qualcosa come
xche è l’identificatore di una variabile di tipointche contiene il valore10tale valore non sarà computato ma sarà solo “fornito” come valore il nome di tipoint. - Una serie di type name seguiti dal carattere due punti
:, ossia una serie di nomi di tipi di dato (per esempioint,char,floate così via) che rappresentano delle specie di etichette che introducono delle espressioni da valutare, dette assignment expressions, e che saranno valutate se il relativo nome di tipo sarà compatibile con il nome di tipo determinato dall’espressione di controllo. L’elementotype_namee l’elementoassignment_expressionsono definiti da C11, in modo unitario, con il termine di generic association (associazione generica). - Un’etichetta di default, ossia una label, espressa tramite la
keyword
default, la cui relativa espressione sarà valutata se tutte le altre label indicanti i nomi dei tipi di dato non sono corrispondenti al tipo di dato dell’espressione di controllo.
In base a quanto esplicitato, possiamo quindi asserire che se un’espressione di selezione generica ha un’associazione generica con un nome di tipo compatibile con il nome di tipo dell’espressione di controllo, allora l’espressione risultato di tale selezione avrà un tipo e un valore che saranno uguali al tipo e al valore dell’assignment expression di quell’associazione. Se, invece, non vi è alcuna concordanza di tipi tra il tipo dell’espressione di controllo e uno dei tipi delle associazioni generiche, allora l’espressione risultato della selezione generica avrà il tipo e il valore dell’assignment expression dell’etichetta default.
CONSIGLIO
È possibile pensare a un’espressione di selezione
generica come a una sorta di istruzione che ricorda quella di
selezione multipla switch, laddove mentre in
quest’ultima è il valore dell’espressione relativa che è
confrontato con il valore di una serie di etichette
case, nella prima è il tipo dell’espressione relativa
che è comparato con una serie di etichette di nomi di tipi.
Listato 10.5 GenericSelection.c (GenericSelection).
/* GenericSelection.c :: Un caso d'uso di una selezione generica :: */
#include <stdio.h>
#include <stdlib.h>
// definisce una macro parametrica che si espande in un'espressione generica
// che a seconda del tipo di dato ritorna un determinato specificatore di formato
#define gen_fmt(f) _Generic((f),\
char: "%c", \
short: "%hd", \
int: "%d", \
long:"%ld", \
long long: "%lld", \
float:"%f", \
double: "%f", \
long double: "%Lf") \
// definisce una macro parametrica che consente di stampare con printf
// un valore di qualsiasi tipo di dato
#define g_print(p) printf(gen_fmt(p), p)
#define NL printf("\n")
int main(void)
{
char c = 'A';
g_print(c); NL;
int i = 10;
g_print(i); NL;
float f = 10.3f;
g_print(f); NL;
double d = 10.3344;
g_print(d); NL;
return (EXIT_SUCCESS);
}
Output 10.6 Dal Listato 10.5 GenericSelection.c.
A
10
10.300000
10.334400
NOTA
Il presente listato è compilabile correttamente
con una versione di GCC dalla 4.9 in poi; è solo a partire da
quella versione che è stato introdotto il supporto alle espressioni
di selezioni generiche tramite la keyword
_Generic.
Il Listato 10.5 definisce la macro parametrica
gen_fmt con una lista di sostituzione formata dalla
definizione di un’espressione di una selezione generica che ha come
obiettivo quello di ritornare un letterale stringa che rappresenta
un determinato specificatore di formato utilizzabile con la
funzione printf.
Lo specificatore di formato ritornato sarà quello indicato da
un’etichetta di un nome di tipo di dato che sarà compatibile con il
nome di tipo di dato di cui l’espressione f (per
esempio, se invochiamo direttamente la macro gen_fmt
nel seguente modo gen_fmt(10); sarà ritornato il
letterale stringa "%d" perché il valore
10 è di tipo int).
Successivamente definisce anche la macro parametrica
g_print la cui lista di sostituzione è formata
dall’istruzione printf che ha come argomenti la macro
gen_fmt stessa e l’identificatore p del
relativo parametro.
Questa macro, nella sostanza, consente di usare l’istruzione
printf in modo “generico”, ossia consente di stampare
il valore di un’espressione senza indicare un determinato
specificatore perché lo stesso, come detto, sarà fornito
dall’espressione di selezione generica ricavata dall’espansione
della macro gen_fmt.
Così, quando per esempio nella funzione main sarà
usata la macro parametrica g_print(i);, il compilatore
si troverà ad analizzare la seguente istruzione frutto della sua
espansione: printf( _Generic(( i ), char: "%c", short: "%hd",
int: "%d", long:"%ld", long long: "%lld", float:"%f", double: "%f",
long double: "%Lf") , i );. Qui appare evidente come sia
anche stata espansa la macro gen_fmt il cui parametro
p è stato sostituito dall’argomento i, il
quale essendo di tipo int farà ritornare come valore
della selezione generica lo specificatore di formato
"%d" che sarà poi usato dalla printf
stessa per stampare correttamente il valore della variabile
i.
IMPORTANTE
Un’espressione di selezione generica è per lo
standard un’espressione primaria e non è una direttiva per il
preprocessore. Abbiamo comunque preferito inserirla in questo
contesto didattico perché essa è usata, generalmente, con la
direttiva #define per creare delle macro parametriche
che si possono comportare come delle funzioni generiche, cioè come
delle funzioni che agiscono in modo indipendente da un tipo di
dato.
Inclusione condizionale
Una caratteristica importante del preprocessore è quella che permette di includere in modo selettivo o condizionale pezzi di codice ovvero, in base al valore di una condizione esaminata, il preprocessore può scegliere se includere o meno sezioni di testo del corrente codice sorgente di un determinato programma.
L’inclusione condizionale, detta anche compilazione condizionale, è una tecnica comunemente utilizzata per: verificare determinati punti di codice facendo stampare certe informazioni diagnostiche solo quando si decide di attivare tale fase di debugging; scrivere programmi portabili su hardware o sistemi operativi differenti; scrivere programmi adattati per certe implementazioni di C piuttosto che per altre; proteggere l’inclusione multipla di uno stesso file header; fornire una definizione di default di una macro verificando che non sia stata già definita.
La direttiva #if
La direttiva del preprocessore #if (Sintassi 10.5)
verifica se l’espressione costante intera che deve valutare è
diversa da 0 e, nel caso, indica al preprocessore di
non rimuovere dal codice sorgente da compilare il relativo gruppo
di righe di codice; in questo caso, le righe di codice considerate
sono quelle scritte fino alla relativa direttiva
#endif o #else o #elif.
Se, invece, la predetta espressione vale 0, allora
indica al preprocessore di rimuovere dal codice sorgente da
compilare quel relativo gruppo di righe di codice che non saranno
pertanto visibili al compilatore. In ambedue i casi, comunque, la
direttiva #if viene eliminata dal preprocessore.
Sintassi 10.6 La direttiva #if.
#if integer_constant_expression new_line [rows_group]
Come evidenziato dalla Sintassi 10.6, la direttiva del
preprocessore #if valuta, attraverso
integer_constant_expression, un’espressione costante
intera che è però soggetta, in questo contesto di utilizzo, alle
seguenti ulteriori restrizioni rispetto a quelle già esaminate nel
Capitolo 3: non può contenere espressioni sizeof; non
può contenere il costrutto cast; se si utilizzano come
operandi delle costanti enumerative esse saranno trattate come
degli identificatori non appartenenti a macro è saranno sostituite
con il valore 0.
Segue, quindi, un carattere effettivo di new line
(digitato cioè da tastiera) e poi attraverso
rows_group l’indicazione delle righe di testo di
codice da includere o meno nella fase di compilazione a seconda se
l’espressione costante intera sia o meno diversa da
0.
Snippet 10.11 La direttiva #if.
...
// 0 = disattiva debug; 1 = attiva debug
#define DEBUG 1
#define SIZE 10
int main(void)
{
int data[SIZE] = {1, 2, 44, 55, 11, 2, 4, 5, 6, -1};
int sum = 0;
char c = '1';
for (int i = 0; i < SIZE; i++)
{
#if DEBUG /* se DEBUG è diversa da 0 fammi vedere i valori degli elementi di data */
printf("valore di data[%d] = %d\n", i, data[i]);
#endif /* DEBUG */
sum += data[i];
}
...
}
Lo Snippet 10.11 definisce un array data e poi
elabora un ciclo for che deve ottenere la somma di
tutti i valori degli elementi del predetto array, da memorizzare,
poi, nella variabile sum definita allo scopo.
Il ciclo for ha nel suo blocco una direttiva
#if che valuta la macro DEBUG la quale,
espandendosi in un valore diverso da 0, farà sì che il
preprocessore lasci all’interno del codice sorgente la relativa
riga che è rappresentata da un’istruzione printf che
manda a video, per scopi diagnostici, un letterale stringa
contenente, per ogni step dell’iterazione, l’indicazione del
corrente elemento analizzato unitamente al suo valore.
Se decidiamo di non volere più quei messaggi di debug, sarà
sufficiente porre come lista di sostituzione della macro
DEBUG la costante 0 e ricompilare il
codice sorgente; non sarà quindi necessario eliminare le direttive
del preprocessore, #if ed #endif, e la
relativa istruzione printf, che potranno sempre
tornarci utili in futuro se vorremo rielaborare quelle informazioni
diagnostiche.
NOTA
Se una direttiva #if valuterà un
identificatore non definito, lo tratterà come se fosse una macro
con il valore 0.
La direttiva #elif
La direttiva del preprocessore #elif (Sintassi
10.7) permette di valutare la sua espressione costante intera solo
se l’espressione costante intera della relativa direttiva
#if è risultata uguale a 0
(#elif è paragonabile al costrutto else
if incontrato nel Capitolo 5).
Sintassi 10.7 La direttiva #elif.
#elif integer_constant_expression new_line [rows_group]
Snippet 10.12 La direttiva #elif.
...
#define LINUX 1 /* attuale sistema hardware di compilazione... */
#define WINDOWS 0
#define AMIGA_OS 0
#define MAC_OS 0
#define CURRENT_OS LINUX
int main(void)
{
#if CURRENT_OS == WINDOWS
printf("Windows...\n");
#elif CURRENT_OS == MAC_OS
printf("Mac...\n");
#elif CURRENT_OS == AMIGA_OS
printf("Amiga...\n");
#elif CURRENT_OS == LINUX /* questa espressione sarà diversa da 0 */
printf("Linux...\n");
#endif /* CURRENT_OS */
...
}
Lo Snippet 10.12 mostra come utilizzare la direttiva
#elif in una serie di valutazioni per verificare qual
è il corrente sistema operativo dove compileremo il programma.
Analizzando il codice appare evidente come solo l’ultima
espressione della direttiva #elif ritornerà un valore
diverso da 0 perché il valore della macro
CURRENT_OS sarà uguale a LINUX, che è
esso stesso l’identificatore di una macro che sarà uguale a
1.
In più, è importante rilevare come, senza alcun problema, le
espressioni costanti intere siano interessate dall’utilizzo
dell’operatore di uguaglianza uguale a ==; infatti,
allo stesso modo, è possibile impiegare l’altro operatore di
uguaglianza non uguale a !=, gli operatori aritmetici,
gli operatori relazionali, gli operatori logici, gli operatori bit
a bit e l’operatore condizionale.
In pratica è certamente fattibile costruire delle espressioni complesse utilizzando la molteplicità di operatori indicati perché la valutazione di tali espressioni ritornerà sempre un valore intero utilizzabile nell’ambito delle predette direttive condizionali.
NOTA
Vi è un ulteriore modo per scrivere il codice
presentato, ma lo vedremo tra breve quando tratteremo della
direttiva #ifdef.
La direttiva #else
La direttiva del preprocessore #else (Sintassi
10.8) include le righe di codice relative solo se l’espressione
costante intera della relativa direttiva #if, o di
altre direttive #elif, sono risultate uguali a
0 (#else è paragonabile al costrutto
else incontrato nel Capitolo 5.
Sintassi 10.8 La direttiva #else.
#else new_line [rows_group]
Snippet 10.13 La direttiva #else.
#if __STDC_VERSION__ == 201112
printf("Ok standard C11: possiamo usare le sue caratteristiche...\n");
#else /* questo ramo sarà eseguito solo se l'#if sarà uguale a 0 */
printf("ERRORE no standard C11: non possiamo usare le sue caratteristiche...\n");
#endif
Per quanto riguarda questa direttiva bisogna rammentare che al
massimo una di esse può essere presente nell’ambito di un blocco
#if / #endif, mentre questa limitazione non è presente
per le direttive #elif che possono esservi in
qualsiasi numero si desidera.
La direttiva #endif
La direttiva del preprocessore #endif (Sintassi
10.9) permette di evidenziare la chiusura di un blocco definito
dalla direttiva #if (oppure dalle direttive
#ifdef e #ifndef).
Sintassi 10.9 La direttiva #endif.
#endif new_line
Lo Snippet 10.14 è utile solo per mostrare come sia possibile
costruire delle strutture di selezione innestate anche mediante le
direttive #if / #endif.
In ogni caso è prassi codificarle senza porre degli spazi di
indentazione ma facendo terminare le direttive #endif
con un commento che evidenzia a quale #if
appartiene.
Snippet 10.14 La direttiva #endif.
...
#define A 1
#define B 1
#define C 1
int main(void)
{
// una serie di #if / #endif innestati; saranno incluse tutte e tre le istruzioni
// di printf
#if A
printf("Ramo A...\n");
#if B
printf("Ramo B...\n");
#if C
printf("Ramo C...\n");
#endif /* C */
#endif /* B */
#endif /* A */
...
}
La direttiva #ifdef
La direttiva del preprocessore #ifdef (Sintassi
10.10) consente di verificare se un determinato identificatore è
stato definito come un nome di una macro.
Sintassi 10.10 La direttiva #ifdef.
#ifdef macro_identifier new_line [rows_group]
La direttiva #ifdef è per certi versi simile alla
direttiva #if perché indica al preprocessore se
includere o meno nel codice che sarà compilato il gruppo di righe
di testo relativo; tuttavia essa ha un’importante differenza,
ovvero non valuta un’espressione costante intera ma verifica solo
se un nome di una macro è definito (infatti, non è necessario che
la macro abbia associato un valore come 0,
1 e così via).
Snippet 10.15 La direttiva #ifdef.
...
#define NL
int main(void)
{
int data[] = {1, 2, 3, 4, 5};
for (size_t i = 0; i < sizeof data / sizeof (int); i++)
{
#ifdef NL /* stampa gli elementi di data ciascuno su una singola riga */
printf("%d\n", data[i]);
#else /* stampa gli elementi di data su una stessa riga */
printf("%d ", data[i]);
#endif /* NL */
}
...
}
Nello Snippet 10.5 il ciclo for stamperà a video i
valori di tutti gli elementi dell’array data in modo
che saranno visualizzati ciascuno su una riga di testo
separata.
Ciò sarà possibile perché la direttiva #ifdef
verificherà che il nome NL è definito come nome di una
macro, e pertanto indicherà al preprocessore di lasciare nel codice
sorgente la relativa istruzione printf che conterrà
anche la sequenza di escape di nuova riga.
La direttiva #ifndef
La direttiva del preprocessore #ifndef (Sintassi
10.11) consente di verificare se un determinato identificatore non
è stato definito come un nome di una macro.
Sintassi 10.11 La direttiva #ifndef.
#ifndef macro_identifier new_line [rows_group]
Questa direttiva indica al preprocessore di includere nel codice
sorgente da compilare il relativo gruppo di righe di testo solo se
il nome della macro cui macro_identifier non è stato
definito.
Snippet 10.16 La direttiva #ifndef.
// definisci la macro SIZE e attribuisci il valore 10 ma solo se non è già definita
#ifndef SIZE
#define SIZE 10
#endif
L’operatore defined
L’operatore espresso tramite la keyword defined
(Sintassi 10.12) è un operatore del preprocessore che consente di
verificare se un identificatore è stato definito come nome di una
macro. Se l’identificatore è stato definito allora l’espressione
relativa ritornerà il valore 1, altrimenti ritornerà
il valore 0.
Sintassi 10.12 L’operatore defined.
defined macro_identifier
L’identificatore controllato da defined può,
opzionalmente, essere posto tra una coppia di parentesi tonde
( ), come evidenzia lo Snippet 10.17, dove
verifichiamo se è stato definito l’identificatore
LINUX come nome di una macro e nel caso lasciamo
inserita nel codice la relativa istruzione printf.
Snippet 10.17 L’operatore defined.
...
#define LINUX
int main(void)
{
#if defined (WINDOWS)
printf("Windows...\n");
#elif defined (MAC_OS)
printf("Mac...\n");
#elif defined (AMIGA_OS)
printf("Amiga...\n");
#elif defined (LINUX) /* questa espressione sarà diversa da 0 */
printf("Linux...\n");
#endif /* WINDOWS */
...
}
NOTA
Non vi è alcuna differenza semantica nell’usare
#ifdef macro_identifier e #if defined
macro_identifier e #ifndef macro_identifier
oppure #if !defined macro_identifier.
Inclusione di file sorgente
Un programma di una certa complessità è nella pratica costituito
da diversi file di codice sorgente che sono rappresentati, secondo
le normali consuetudini di C, in file aventi estensione
.c, che contengono definizioni di funzioni e di
variabili, e file aventi estensione .h., che
contengono definizioni di macro, prototipi di funzioni, istruzioni
typedef e così via.
I file con estensione .h, detti include
file o header file (file di intestazione), sono di
notevole importanza nell’ambito dello sviluppo di un programma non
banale perché sono impiegati per “condividere” delle informazioni
lì contenute tra altri file di codice sorgente.
Queste informazioni possono riguardare, per esempio, dei nomi di macro, dei nuovi nomi di tipo, delle dichiarazioni di funzioni, delle dichiarazioni di variabili esterne, delle dichiarazioni di tipo struttura e così via.
Ciò detto, uno o più file di codice sorgente che dovesse avere bisogno di queste informazioni dovrebbe avere un modo per poterle utilizzare, ossia dovrebbe poter “incorporare” nel suo contesto quei nomi di tipo, qui prototipi di funzione e così via.
A tal fine lo standard di C mette a disposizione del programmatore una speciale direttiva del preprocessore che consente di “includere” quei file header nell’ambito di uno specifico file sorgente e dunque utilizzarne le relative informazioni.
Questa direttiva è denominata #include e nasce con
lo scopo di poter rintracciare un file sorgente o un file header
che può essere validamente processato dalla corrente
implementazione.
NOTA
La direttiva #include, come detto,
nasce per consentire di includere file di codice sorgente e quindi
nulla vieta di includere in un file .c altri file
.c. Tuttavia, questa è una pratica non utilizzata
perché, in linea generale, un file .c, può contenere,
oltre alla dichiarazione di variabili esterne, anche definizioni di
funzioni. Pertanto se abbiamo due file .c, per esempio
One.c che contiene la funzione main e
Two.c, che entrambi includono un altro file
.c con una definizione di funzione, per esempio
Three.c e la funzione foo, quando
manderemo in compilazione il programma che contiene la funzione
main (One.c), unitamente all’altro file
(Two.c), il linker ci segnalerà l’errore
multiple definition of 'foo'. Quanto detto ha senso
solo perché è prassi consolidata nell’ambito dello sviluppo di un
programma in C usare i file .h per scrivere codice che
contiene delle dichiarazioni di funzioni e i file .c
per scrivere codice che contiene delle definizioni di funzioni.
TERMINOLOGIA
Più precisamente, possiamo dire che un file di
codice sorgente per C è sia un file .c sia un file
.h. In ogni caso, è nella prassi indicare come file di
codice sorgente solo i file .c e come file di
intestazione solo i file .h che sono disgiunti dai
primi. Per quanto riguarda la terminologia adottata in questo testo
essa si avvarrà a volte di un significato più preciso (come è il
caso di quest’unità didattica che tratta dell’inclusione di file
sorgente), mentre altre volte di un significato più snello e
pratico (come è il caso, per esempio, del Capitolo 1).
La direttiva #include
La direttiva del preprocessore #include (Sintassi
10.13, 10.14 e 10.15) permette di incorporare, dal punto dove è
definita e in un file sorgente che ne fa uso, il contenuto di altro
file sorgente da essa riferito.
Sintassi 10.13 La direttiva #include (I forma).
#include <h_char_sequence>
Con la Sintassi 10.13 si include il contenuto del file sorgente
specificato tra una coppia di parentesi angolari <
> e tale contenuto sostituisce quella direttiva che viene
eliminata.
La sequenza di caratteri h_char_sequence definisce
generalmente il nome di un file esterno e può contenere qualsiasi
membro del corrente set di caratteri eccetto i caratteri new line e
> (parentesi angolare chiusa).
Con la direttiva #include scritta in questa forma
il preprocessore cerca il file sorgente indicato in una serie di
locazioni che sono dipendenti dall’implementazione corrente la
quale, a sua volta, a seconda del sistema target, ne ha di
predefinite; per esempio:
- per GCC in ambienti Unix-like i percorsi di ricerca sono
usualmente
/usr/local/include,/usr/includee[libdir]/gcc/[target]/[version]/include(nel nostro sistema GNU/Linux quest’ultimo percorso è espanso come /usr/lib/gcc/x86_64-redhat-linux/4.9.2/include); - per GCC (MinGW) in ambienti Windows i percorsi di ricerca sono
usualmente
C:\MinGW\lib\gcc\mingw32\[version]\include,C:\MinGW\lib\gcc\mingw32\[version]\include-fixed(nel nostro sistema Window 8.1[version]è espanso come4.8.1) eC:\MinGW\include, C:\MinGW\mingw32\include.
I file sorgente inclusi riguardano, tipicamente, i file header
della libreria di funzioni dello standard di C, e la loro corretta
denominazione è quella indicata dalla relativa specifica del
linguaggio (per esempio stdio.h, math.h,
assert.h, stdlib.h, time.h e
così via).
Snippet 10.18 La direttiva #include (I forma).
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <math.h>
#include <stdint.h>
#include <time.h>
#include <stdarg.h>
#include <complex.h>
int main(void)
{
...
}
Lo Snippet 10.18 include una serie di file header propri della
libreria standard del linguaggio C; quando il preprocessore
incontrerà ciascuna direttiva #include la eliminerà
sostituendola con il contenuto effettivo che si troverà nel file
specificato, in accordo anche con quanto è lì indicato (per
esempio, potrà includere o meno dello specifico codice per effetto
della valutazione delle direttive condizionali #if,
#else e via discorrendo).
Sintassi 10.14 La direttiva #include (II forma).
#include "q_char_sequence"
Con la Sintassi 10.14 si include il contenuto di un file
sorgente specificato tra una coppia di doppi apici " "
e tale contenuto sostituisce quella direttiva, che viene
eliminata.
La sequenza di caratteri q_char_sequence definisce
generalmente il nome di un file esterno e può contenere qualsiasi
membro del corrente set di caratteri eccetto i caratteri new line e
" (doppio apice).
Con la direttiva #include scritta in questa forma
il preprocessore cerca il file sorgente in un modo che è definito
dall’implementazione corrente laddove, tuttavia, i correnti
compilatori tipicamente seguono questo procedimento: iniziano a
cercare a partire dalla locazione dove è presente il file sorgente
che fa uso di tale direttiva, e se lì non trovano il file da
includere allora provano a cercarlo nei path utilizzati nel caso la
direttiva #include fosse stata scritta nella I forma
ossia con le parentesi angolari < >.
ATTENZIONE
Con questa II forma di utilizzo della direttiva
#include è possibile utilizzare dei percorsi di
ricerca prestabiliti come, per esempio,
/opt/cl/my_include oppure
d:\cl\my_include. È tuttavia sconsigliato esplicitare
path in modo assoluto per evitare problemi di portabilità del
codice su altri sistemi.
I file sorgente inclusi riguardano, generalmente, i file header di librerie di funzioni scritte dal programmatore stesso e indispensabili per il corretto funzionamento del proprio programma.
Snippet 10.19 La direttiva #include (II forma).
...
#include "stack.h"
int main(void)
{
...
}
Lo Snippet 10.19 include il file header stack.h che
dovrà trovarsi, in accordo con quanto detto, almeno nella stessa
locazione del file di codice sorgente che lo sta includendo.
Sintassi 10.15 La direttiva #include (III forma).
#include pp_tokens
Con la Sintassi 10.15 si indicano dei token pre-elaborazione che
sono usualmente rappresentati dall’identificatore di una macro
semplice, la cui lista di sostituzione deve contenere dei token in
grado di rappresentare una delle due forme della direttiva
#include prima citate; detto in altri termini, la
macro deve espandersi con una coppia di parentesi angolari con il
nome di un header <header_name> oppure con una
coppia di doppi apici con il nome del file sorgente
"file_source_name".
DETTAGLIO
Leggendo quanto appena detto potremmo chiederci
perché nel caso della I forma della direttiva #include
esplicitiamo il “nome” di un header e nel caso della II forma della
stessa direttiva esplicitiamo il “nome di un file” di un sorgente.
Il motivo risiede nel fatto che la specifica di C non richiede
espressamente che il nome di un header sia il nome di un file
sorgente da ricercare in uno specifico filesystem (i dettagli su
come accedere a quell’intestazione dipendono infatti
dall’implementazione corrente). Resta inteso, tuttavia, che quanto
evidenziato è solo per un rigore formale e terminologico; infatti,
nella prassi è lecito indicare la sintassi della I forma della
direttiva #include come #include
<file_source_name>.
Snippet 10.20 La direttiva #include (III forma).
#define VERSION 3
#if VERSION == 1
#define INC_FILE "stack_v1.h"
#elif VERSION == 2
#define INC_FILE "stack_v2.h"
#elif VERSION == 3
#define INC_FILE "stack_v3.h"
#else
#define INC_FILE "stack_beta.h"
#endif
#include INC_FILE /* sarà: #include "stack_v3.h" */
Lo Snippet 10.20 mostra come sia possibile includere un file
sorgente in modo “variabile”, ossia con un valore dipendente da
quanto indicato da un lista di sostituzione di una specifica macro.
Nel nostro caso questa possibilità, definita computed
include, ci ha permesso di scrivere una sola istruzione
#include piuttosto che tante istruzioni
#include ciascuna con un proprio valore di un nome di
un file sorgente lì codificato direttamente.
Strutturazione di programmi complessi
Strutturare un programma complesso, ossia formato da più file di codice sorgente, è di sicuro un’operazione non banale che richiede sia una completa padronanza e consapevolezza di quelli che sono i costrutti e le tecniche di programmazione proprie di C sia un’adeguata conoscenza dei principi di progettazione e di design di un programma.
Costrutti e tecniche di programmazione
Per quanto riguarda i costrutti e le tecniche di programmazione che consentono di strutturare un programma complesso in C, essi sono strettamente legati a una corretta comprensione di quali sono le adeguate metodologie che ci consentono di mettere a disposizione di diversi file di codice sorgente (condividere) le dichiarazioni di variabili, di prototipi di funzioni, di nomi di macro e così via.
Per esempio, per condividere tra più file sorgente una variabile esterna dobbiamo compiere i seguenti passi (Listati 10.6, 10.7 e 10.8):
- definirla come variabile esterna in un file
.cassegnandole eventualmente anche un valore iniziale. - dichiararla in un file
.hutilizzando lo specificatore di classeextern.
Listato 10.6 A_1.h (SharingVariables).
// dichiarazione della variabile data
extern int data;
Listato 10.7 A_1.c (SharingVariables).
// inclusione dell'header A_1.h
#include "A_1.h"
// definizione della variabile data con valore iniziale 100
int data = 100;
Listato 10.8 SharingVariables.c (SharingVariables).
/* SharingVariables.c :: Utilizzo di una variabile definita altrove :: */
#include <stdio.h>
#include <stdlib.h>
// inclusione dell'header A_1.h
#include "A_1.h"
int main(void)
{
printf("Il valore di data e': %d\n", data);
return (EXIT_SUCCESS);
}
Output 10.7 Dal Listato 10.8 SharingVariables.c.
Il valore di data e': 100
Il progetto SharingVariables è costituito da tre
file: A_1.h, che contiene la dichiarazione della
variabile data; A_1.c, che contiene la
definizione della variabile data;
SharingVariables.c, che contiene la funzione
main e che utilizza la variabile
data.
Il programma funziona correttamente perché
SharingVariables.c include il file header
A_1.h, che gli fornisce la dichiarazione della
variabile data permettendo alla funzione
printf di utilizzare l’identificatore
data senza alcun problema (infatti il programma si
compilerà senza errori).
Ricordiamo, a tal fine, che nella fase di compilazione, quella che produce solo un file oggetto e che non fa ancora uso del linker, è sufficiente per il compilatore che vi sia una dichiarazione valida di un identificatore di un oggetto prima del suo utilizzo.
È utile evidenziare che anche il file sorgente
A_1.c include il file header A_1.h e ciò
per consentire al compilatore, durante la fase di compilazione di
A_1.c, di verificare che vi sia una corrispondenza tra
la dichiarazione della variabile data e la sua
definizione (se proviamo infatti a dichiarare data
come extern long data un compilatore come GCC, ci
segnalerebbe il seguente messaggio: error: conflicting types
for 'data').
Per condividere, invece, tra più file sorgente una funzione dobbiamo compiere i seguenti passi (Listati 10.9, 10.10 e 10.11):
- definirla in un file
.c, ossia scriverla indicando il relativo corpo di istruzioni; - dichiararla in un file
.h, ossia scriverla indicando il relativo prototipo.
Listato 10.9 A_2.h (SharingFunctions).
// prototipo di foo
void foo(void);
Listato 10.10 A_2.c (SharingFunctions).
#include <stdio.h>
// inclusione dell'header A_2.h
#include "A_2.h"
// definizione di foo
void foo(void)
{
printf("Elaborazione di foo...\n");
}
Listato 10.11 SharingFunctions.c (SharingFunctions).
/* SharingFunctions.c :: Utilizzo di una funzione definita altrove :: */
#include <stdio.h>
#include <stdlib.h>
// inclusione dell'header A_2.h
#include "A_2.h"
int main(void)
{
// eseguo foo...
foo();
return (EXIT_SUCCESS);
}
Output 10.8 Dal Listato 10.11 SharingFunctions.c.
Elaborazione di foo...
Il progetto SharingFunctions è costituito da tre
file: A_2.h, che contiene il prototipo della funzione
foo; A_2.c, che contiene la definizione
della funzione foo; SharingFunctions.c,
che contiene la funzione main e che utilizza la
funzione foo.
Anche in questo caso la funzione main del file
SharingFunctions.c può lecitamente utilizzare la
funzione foo perché l’identificatore foo
è lì visibile grazie all’inclusione del file header
A_2.h che ne contiene un appropriato prototipo.
Allo stesso tempo il file A_2.c include il file
A_2.h, in modo che quando il compilatore compilerà
A_2.c potrà verificare una corrispondenza tra la
dichiarazione e la definizione della funzione foo.
Infine per condividere tra più file sorgente il nome di una
macro, una dichiarazione typedef, una dichiarazione di
una struttura e così via è sufficiente porle in un apposito file
header e includerlo nei file .c che ne necessitano
(Listati 10.12, 10.13, 10.14).
Listato 10.12 A_3.h (SharingMacroTypedefEtc).
// alcune macro semplici
#define SIZE 100
#define MSG "ELABORAZIONE IN CORSO...\n"
// una dichiarazione typedef
typedef long int BigInt;
// dichiarazione di una struttura
struct point
{
int x;
int y;
};
// dichiarazione di un enum
enum colors
{
RED = 0xF00, GREEN = 0x0F0, BLUE = 0x00F, WHITE = 0xFFF, BLACK = 0x000
};
// prototipo di setPixelAt
void setPixelAt(struct point p, enum colors c);
Listato 10.13 A_3.c (SharingMacroTypedefEtc).
#include <stdio.h>
// inclusione dell'header A_3.h
#include "A_3.h"
// definizione di setPixelAt
void setPixelAt(struct point p, enum colors c)
{
printf(MSG);
printf("Accendo il pixel alle coordinate [%d, %d] con il colore: [%X]\n",
p.x, p.y, c);
}
Listato 10.14 SharingMacroTypedefEtc.c (SharingMacroTypedefEtc).
/* SharingMacroTypedefEtc.c :: Utilizzo di una funzione definita altrove :: */
#include <stdio.h>
#include <stdlib.h>
// inclusione dell'header A_3.h
#include "A_3.h"
int main(void)
{
// uso un alias di tipo e una macro semplice definiti in A_3.h
BigInt numbers[SIZE];
// uso la struttura definita in A_3.h
struct point p = {100, 100};
// uso l'enumerazione definita in A_3.h
enum colors red = RED;
// uso setPixelAt dichiarata in A_3.h e definita in A_3.c
setPixelAt(p, red);
return (EXIT_SUCCESS);
}
Output 10.9 Dal Listato 10.14 SharingMacroTypedefEtc.c.
ELABORAZIONE IN CORSO...
Accendo il pixel alle coordinate [100, 100] con il colore: [F00]
Il progetto SharingMacroTypedefEtc è costituito da
tre file: A_3.h, che contiene la definizione di alcune
macro semplici, una dichiarazione di una struttura di tipo
struct point, una dichiarazione di un’enumerazione di
tipo enum colors e il prototipo di una funzione
denominata setPixelAt; A_3.c, che
contiene la definizione della funzione setPixelAt;
SharingMacroTypedefEtc.c, che contiene la funzione
main che utilizza i tipi, la macro e la funzione
dichiarati nel file header A_3.h per questo
incluso.
Principi di progettazione e di design di un programma
Per quanto riguarda i principi di progettazione e di design di un programma, una trattazione completa ed esaustiva esulerebbe dagli obiettivi didattici del presente libro e pertanto proveremo solo a darne un’indicazione di massima lasciando al lettore un eventuale approfondimento con dei testi opportuni.
Partiamo dicendo subito che un programma complesso richiede un’attenta analisi di quello che è il suo principale obiettivo computazionale, in modo più generico possibile, per poi elaborarlo scomponendolo in tanti sotto-obiettivi più specializzati fino ad arrivare a un livello di granularità che ci soddisfa oppure che non ha più senso estendere.
Questi obiettivi possono essere codificati in appositi “pezzi di software” indipendenti, usualmente indicati con il termine di moduli software, che sono però tra di loro comunicanti perché devono consentire all’unisono il raggiungimento dell’obiettivo computazionale principale del programma.
Ciascuno di questi moduli è tipicamente costituito da due parti di cui una si occupa di descrivere i servizi e le funzionalità disponibili per un generico client utilizzatore, mentre l’altra si occupa di fornire per tali servizi e funzionalità un apposito dettaglio realizzativo.
Dal punto di vista terminologico, la prima parte è denominata interfaccia mentre la seconda parte è denominata implementazione.
Ogni linguaggio di programmazione può offrire opportuni
strumenti e differenti metodologie che consentono di definire e
utilizzare tali moduli; per quanto riguarda C è possibile
realizzare un modulo software avvalendosi dei file header
.h per la definizione della parte interfaccia
(conterrà, per esempio, i prototipi delle funzioni), mentre dei
file di codice sorgente .c per la definizione della
parte implementazione (conterrà, per esempio, la definizione delle
funzioni prototipate).
Il client utilizzatore, invece, è semplicemente un file di
codice sorgente .c che conterrà la funzione
main di ingresso del programma principale attraverso
la quale si invocheranno le funzionalità messe a
disposizione dai moduli software che si desidera utilizzare.
Da questo punto di vista possiamo dire che la libreria standard
del linguaggio C non è altro che un insieme di moduli software
ciascuno deputato a offrire uno specifico servizio; per esempio, se
volessimo utilizzare delle funzioni per la gestione o la
manipolazione ad alto livello delle stringhe potremmo utilizzare il
relativo modulo mediante l’inclusione nel nostro programma del file
header <string.h> che ne rappresenta
l’interfaccia.
Allo stesso modo, se il nostro programma avesse bisogno di
funzioni specializzate per la gestione di date o orari, potremmo
utilizzare i servizi offerti da uno specifico modulo la cui
interfaccia è fornita dal file header
<time.h>.
E così via il procedimento da seguire sarebbe sempre lo stesso, ossia si dovrebbe in primo luogo individuare il modulo software necessario e poi si dovrebbe importare nel programma la relativa interfaccia espressa da un appropriato file header.
NOTA
Per quanto riguarda la parte implementativa di ogni modulo software della libreria standard del linguaggio C, essa è solitamente definita in una serie di appositi file oggetto che vengono utilizzati in automatico dal linker durante la produzione del file eseguibile finale. Per esempio, per quanto riguarda GCC, la libreria standard utilizzata è quella denominata glibc (The GNU C Library), la quale fornisce, sotto forma di una libreria statica oppure di una libreria dinamica, tutti i file oggetto che il linker può utilizzare. Per un dettaglio ulteriore si consulti l’Appendice A.
La possibilità di strutturare un programma in tanti moduli software permette di ottenere i seguenti benefici.
- Riuso: ogni modulo software, se progettato in modo
sufficientemente generico e flessibile, può essere riutilizzato in
differenti programmi permettendo di “non reinventare la ruota” ogni
volta. Così, per esempio, ogni nostro programma, se necessiterà di
utilizzare delle routine per la gestione di date e orari, potrà
semplicemente importare il file header
<time.h>, il quale fornirà già tutte le funzionalità di gestione richieste (non dovremo quindi preoccuparci di scrivere ex novo apposite funzioni di gestione di date e orari). - Semplicità di utilizzo: il fatto che un modulo sia
diviso in una parte interfaccia che è visibile ed è importata per
l’utilizzo e una parte implementazione che è non visibile ed è
tipicamente compilata in un apposito file oggetto permette di far
concentrare il programmatore su “cosa” deve fare per raggiungere un
certo obiettivo computazionale piuttosto che su “come” deve fare
per raggiungerlo. Ciò significa che se nel nostro programma stiamo
usando le funzionalità offerte dal modulo di gestione delle
stringhe (file header
<string.h>) e abbiamo bisogno di comparare una stringa con un’altra stringa per verificare quale delle due è la maggiore, è sufficiente sapere quale funzione offre quella funzionalità e qual è il suo prototipo (come si chiama, cosa ritorna e quali parametri ha). Nel nostro caso potremmo utilizzare la funzionestrcmpche fa proprio quello che ci serve; il come lo fa, tuttavia, non ci deve riguardare, e infatti la sua reale implementazione non è per noi di alcuna importanza (siamo dei semplici utilizzatori).
TERMINOLOGIA
La distinzione tra “come” un modulo è implementato e “cosa” fa è un esempio di quella che viene definita astrazione. Un’astrazione, nella sostanza, consente di utilizzare un oggetto complesso senza essere a conoscenza dei suoi dettagli realizzativi.
- Manutenibilità: se ogni modulo software è progettato e
sviluppato come un componente indipendente, qualsiasi manutenzione
correttiva (eliminazione di bug) oppure evolutiva (aggiunta di
caratteristiche) può essere effettuata senza alcuna interferenza
con altri moduli (a condizione però che le interfacce rimangano
coerenti, ossia che le relative funzioni continuino ad avere lo
stesso prototipo). Per esempio, se è necessario apportare una
correzione alla funzione
strcmpdel modulo di gestione delle stringhe sarà sufficiente, al termine della relativa manutenzione, ricompilare solo tale modulo e poi linkare l’intero programma in modo che il linker colleghi allo stesso questo nuovo modulo aggiornato. - Estensibilità: è sempre possibile migliorare o apportare cambiamenti a un modulo agendo direttamente sulla parte implementazione e mai sulla parte interfaccia, che dovrà continuare a esporre i suoi servizi in modo congruo (i suoi prototipi di funzioni non dovranno subire cambiamenti).
Un esempio di un programma complesso
Mostriamo infine un programma che ha l’obiettivo di implementare un modulo software che definisce una struttura di dato definita stack (pila), la quale rappresenta un gruppo di elementi disposti secondo un criterio LIFO (Last In First Out), in cui l’ultimo elemento inserito sarà anche il primo a essere gestito (considerando un esempio reale di stack come può essere una pila di libri, avremo che l’ultimo libro che si dispone su di essa sarà anche il primo che potrà essere preso senza che tutta la pila di libri cada).
Le operazioni principali associabili con uno stack sono denominate push, con cui si aggiunge un nuovo elemento in cima alla pila, e pop, con cui si rimuove un elemento dalla cima della pila.
TERMINOLOGIA
Il termine struttura di dati indica il modo in cui i dati sono conservati e organizzati nella memoria e le operazioni che si possono compiere su di essi (algoritmi). Esso è pertanto generalizzabile nella seguente forma: STRUTTURA DI DATI = INSIEME DI ELEMENTI + OPERAZIONI.
NOTA
Dal punto di vista della programmazione, finora abbiamo visto e utilizzato solamente l’array, nella sua forma monodimensionale e multidimensionale, come struttura di dati atta a contenere una serie di elementi.
Listato 10.15 stack.h (Stack).
#ifndef STACK_H
#define STACK_H
// Stack è un alias per un puntatore a una struttura di tipo struct stack
typedef struct stack *Stack;
// costruttore di uno stack
Stack newStack(int);
// distruttore di uno stack
void deleteStack(Stack);
// funzionalità dello stack
void push(Stack, int);
int pop(Stack);
int size(Stack);
#endif /* STACK_H */
Listato 10.16 stack.c (Stack).
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include "stack.h"
#define MSG "Errore in "
// dichiarazione della struttura di tipo struct stack
struct stack
{
int size;
int top;
int *elems;
};
// definizione delle funzionalità "private" dello stack
static void message(const char *f, const char *m)
{
printf("%s [%s] :: %s ::\n", MSG, f, m);
exit(EXIT_FAILURE);
}
static _Bool isEmpty(Stack s)
{
return s->top == 0;
}
static _Bool isFull(Stack s)
{
return s->top == s->size;
}
// definizione delle funzionalità "pubbliche" dello stack
Stack newStack(int sz)
{
Stack s = malloc(sizeof (struct stack));
if (s == NULL)
message(__func__, "... creazione fallita ...");
s->elems = malloc(sizeof (int) * (size_t) sz);
if (s->elems == NULL)
{
message(__func__, "... creazione fallita ...");
free(s);
}
s->size = sz;
s->top = 0;
return s;
}
void deleteStack(Stack s)
{
free(s->elems);
free(s);
}
void push(Stack s, int value)
{
if (isFull(s))
{
deleteStack(s);
message(__func__, "... lo stack e' pieno ...");
}
s->elems[s->top++] = value;
}
int pop(Stack s)
{
if (isEmpty(s))
{
deleteStack(s);
message(__func__, "... lo stack e' vuoto ...");
}
return s->elems[--s->top];
}
int size(Stack s)
{
return s->size;
}
Listato 10.17 StackClient.c (Stack).
/* StackClient.c :: Utilizzo di uno stack :: */
#include <stdio.h>
#include <stdlib.h>
#include "stack.h"
// 0 = non fa includere il codice di push o pop che causa un errore
// 1 = fa includere il codice di push o pop che causa un errore
#define DO_ERROR_PUSH 0
#define DO_ERROR_POP 0
int main(void)
{
// crea uno stack con 5 elementi
Stack a_stack = newStack(5);
// popolo lo stack: operazioni di push
int sz = size(a_stack);
for (int i = 0; i < sz; i++)
push(a_stack, i * 2);
#if DO_ERROR_PUSH
// provo a inserire un ulteriore elemento...
push(a_stack, 100);
#endif
printf("Valori estratti: [");
// svuoto lo stack: operazione di pop
for (int i = 0; i < sz; i++)
{
printf("%d, ", pop(a_stack));
}
printf("\b\b]\n");
#if DO_ERROR_POP
// provo a estrarre un ulteriore elemento...
int el = pop(a_stack);
#endif
// distruggo lo stack
deleteStack(a_stack);
return (EXIT_SUCCESS);
}
Output 10.10 Dal Listato StackClient.c.
Valori estratti: [8, 6, 4, 2, 0]
Il progetto Stack è composto dai seguenti file:
stack.h e stack.c, che rappresentano
rispettivamente la parte interfaccia e la parte implementazione del
modulo software che modella la struttura dati stack;
StackClient.c, che rappresenta un client utilizzatore,
ossia il programma principale, fornito di una funzione
main, deputato a utilizzare il tipo
stack.
Per quanto attiene al file header stack.h, la prima
cosa da notare è che il suo contenuto effettivo è incluso tra le
direttive #ifndef e #endif che, così come
sono state codificate, denotano un determinato costrutto definito
in gergo wrapper #ifndef o anche include guards.
Questo costrutto è di notevole importanza nell’ambito dello
sviluppo di un programma complesso composto da più file, perché
consente di evitare un’inclusione multipla dello stesso file header
in un file di codice sorgente che potrebbe causare degli errori di
compilazione del tipo redefinition of '...' se, per
esempio, tale file header contenesse la dichiarazione di una
struttura. In pratica quando il preprocessore elabora il file
stack.h la prima volta ragiona così: “poiché non è
definita la macro STACK_H, devo definirla e devo
includere tutto il sottostante contenuto fino alla successiva
direttiva #endif”. La seconda volta che elabora il
file stack.h ragiona, invece, così: “poiché è già
definita la macro STACK_H salto le rimanenti
righe di codice e non includo nulla”.
Per quanto attiene alla macro utilizzata subito dopo la
direttiva #ifndef, essa è denominata controlling
macro o guard macro e il suo nome, tipicamente,
corrisponde al nome del relativo file header scritto in maiuscolo
nel quale si sostituisce il carattere punto . con il
carattere underscore _ (questa modalità di
denominazione dell’identificatore della macro, se rispettata dai
programmatori, dovrebbe garantire una certa univocità ed evitare
eventuali conflitti con altri nomi simili di macro, visto che in un
filesystem non possono esservi nomi di file uguali).
NOTA
Il problema dell’inclusione multipla dei file
.h è una realtà concreta perché lo standard consente
l’inclusione annidata dei file header, ossia permette che un file
.h includa a sua volta un altro file .h e
così via (lo standard prescrive che un’implementazione deve
garantire almeno 15 livelli di annidamento; GCC ne permette fino a
200). La Figura 10.1 mostra cosa avviene in caso di file
.h innestati quando possono verificarsi inclusioni
multiple di uno stesso file .h senza l’utilizzo di
appositi costrutti di “difesa” #ifndef / #endif.
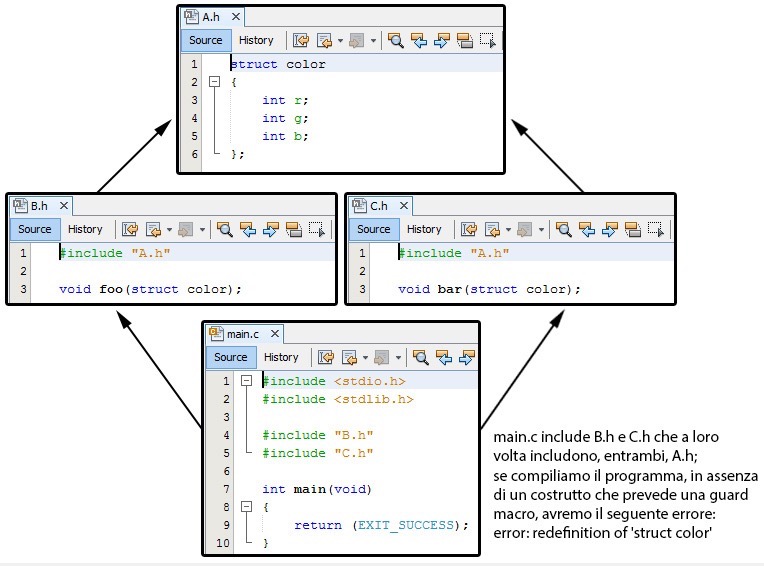
Figura 10.1 Problema dell’inclusione multipla di file header senza una guard macro.
Un’altra “novità” implementativa utilizzata nel file
stack.h riguarda la dichiarazione di
Stack, che è un alias di tipo per un puntatore a una
struttura di tipo struct stack, come “tipo incompleto”
(incomplete type), ossia come un tipo che non è in grado
di fornire sufficienti informazioni al compilatore utilizzabili per
determinarne l’esatta dimensione.
In pratica la dichiarazione di Stack così compiuta,
consente al client utilizzatore di poter solamente dichiarare
oggetti di quel tipo, ma non gli permette di poterli utilizzare
direttamente accedendo, per esempio, ai membri della struttura
relativa.
L’occultamento della reale implementazione della struttura di
tipo struct stack, pratica progettuale definita in
letteratura information hiding, consente di ottenere
almeno i due seguenti importanti benefici.
- Robustezza del codice: se un client utilizzatore non
ha la possibilità di accedere direttamente ai membri della
struttura che definisce uno stack non può invalidarla, corromperla
oppure manipolarla in modo non congruo. Per esempio, se potesse
manipolare direttamente il membro
size, fornendo un valore superiore agli elementi effettivamente memorizzati, questo potrebbe poi creare problemi anche gravi in un eventuale cicloforche scorresse lo stack per accedere agli elementi lì contenuti. - Scalabilità del codice: la struttura di dati
effettivamente impiegata all’interno dello stack per memorizzare
gli elementi potrebbe essere cambiata con il tempo senza per questo
invalidare il codice sorgente che utilizza lo stack. Per esempio,
una prima implementazione potrebbe utilizzare un array, una
successiva implementazione potrebbe utilizzare una lista collegata
(linked list) e così via, senza che ciò influenzi il
client utilizzatore, il quale per manipolare gli elementi dello
stack utilizzerebbe sempre la stessa interfaccia (per esempio le
funzioni
pushepop). In definitiva se avessimo dato la possibilità al client di manipolare direttamente il membro deputato a memorizzare gli elementi dello stack e poi avessimo deciso di cambiarne la rappresentazione avremmo dovuto cambiare il codice anche in quel client, con ovvi problemi di manutenibilità del codice.
TERMINOLOGIA
Una lista collegata o concatenata (linked list) è una struttura di dati che rappresenta un gruppo di elementi, definiti nodi della lista, disposti in modo lineare e sequenziale e atti a formare una collezione ordinata. Ogni nodo della lista è composto sia dal dato che rappresenta, sia da un riferimento verso un altro nodo. Quando i nodi di una lista hanno un solo riferimento verso un altro nodo successivo si parla di lista semplicemente collegata, mentre se i nodi hanno due riferimenti, di cui uno verso un nodo successivo e uno verso un nodo precedente, si parla di lista doppiamente collegata.
Il file di codice sorgente stack.c contiene,
invece, la dichiarazione effettiva della struttura di tipo
struct stack con i suoi membri costitutivi e anche una
serie di funzioni “pubbliche” che sono utilizzabili da un client
utilizzatore e che permettono: la creazione di un tipo
Stack (newStack); la distruzione di un
tipo Stack (deleteStack); l’inserimento
di un elemento in uno stack (push); l’estrazione di un
elemento da uno stack (pop); l’ottenimento della
dimensione di uno stack (size).
Sono poi presenti delle funzioni “private” che sono utilizzabili
solo dalle funzioni presenti nel file stack.c e che
consentono: la visualizzazione di un messaggio diagnostico durante
l’utilizzo di uno stack (message) (per esempio, se la
funzione push rileva che lo stack è pieno viene
visualizzato al client tale messaggio); la rilevazione se uno stack
è vuoto, ovvero se non ha elementi (isEmpty); la
rilevazione se uno stack è pieno, ovvero se ha raggiunto la massima
dimensione di elementi contenibili (isFull).
NOTA
È grazie allo specificatore della classe di
memorizzazione static che le funzioni
message, isEmpty e isFull
sono utilizzabili solo nel file stack.c e dunque sono
a esso “private”.
DETTAGLIO
Una pratica di codifica utilizzata sovente per
dichiarare un oggetto o una funzione come “pubblico” o come
“privato” consiste nel definire delle apposite macro semplici con
identificatori denominati public (o
PUBLIC) e private (o
PRIVATE), i quali sono poi impiegati come se fossero
dei “modificatori specifici per il controllo dell’accesso” al pari
di quelli utilizzati nei linguaggi di programmazione a oggetti,
tipo C++, Java e così via (Snippet 10.21).
Snippet 10.21 Macro private e public.
...
#define public
#define private static
...
private void message(const char *f, const char *m) { ... }
private _Bool isEmpty(Stack s) { ... }
public Stack newStack(int sz) { ... }
public void deleteStack(Stack s) { ... }
public void push(Stack s, int value) { ... }
public int pop(Stack s) { ... }
public int size(Stack s) { ... }
Per quanto attiene invece alla struttura di tipo struct
stack, i suoi membri sono: size, deputato a
contenere la dimensione massima di uno stack; top,
incaricato di tenere traccia dell’indice del corrente elemento di
uno stack da manipolare; elems, utilizzato come
array dinamico atto a contenere gli elementi di uno
stack.
Passiamo, infine, al file di codice sorgente
StackClient.c, che nell’ambito della funzione
main: crea uno stack di massimo cinque elementi;
popola lo stack con una serie di valori (primo ciclo
for che usa la funzione push); svuota lo
stack (secondo ciclo for che usa la funzione
pop); elimina lo stack.
Per quello che concerne lo stack creato ribadiamo ancora una
volta come a_stack sia di un tipo Stack
incompleto ossia, nell’ambito del file StackClient.c,
è possibile solo creare variabili di quel tipo oppure passarle come
argomenti alle funzioni che hanno parametri di tipo
Stack come push, pop,
newStack e così via. In pratica non sarà mai possibile
usare a_stack per compiere operazioni di selezione
diretta dei membri di Stack come
a_stack->top, a_stack->elems[2] e
così via; questo perché il compilatore non ha informazioni
sufficienti che gli consentano di determinare quali siano i membri
della struttura di tipo struct stack e dunque quale
sia la sua effettiva dimensione (nel file stack.c è
invece presente la dichiarazione “completa” della struttura
struct stack, e infatti in quel file di codice
sorgente è possibile accedere direttamente ai membri di tale
struttura).
La direttiva #error
La direttiva del preprocessore #error (Sintassi
10.16) induce la corrente implementazione a produrre un messaggio
diagnostico di errore fatale, formato dalla sequenze di
token specificati, e a interrompere di conseguenza la compilazione
in corso.
Sintassi 10.16 La direttiva #error.
#error [pp_tokens]
Questa direttiva è tipicamente impiegata in unione con le direttive condizionali in modo da far continuare o meno la compilazione del relativo programma in accordo, per l’appunto, con quanto la condizione verificata esprime (Snippet 10.22).
Snippet 10.22 La direttiva #error.
/*
se il preprocessore rileva che la corrente implementazione non è aderente
allo standard C11 interromperà la compilazione e mostrerà in output un messaggio
come il seguente (nel nostro caso è stato generato da GCC): error: #error
Questo programma funziona solo con compilatori aderenti allo standard C11
*/
#if __STDC_VERSION__ != 201112
#error Questo programma funziona solo con compilatori aderenti allo standard C11
#endif
NOTA
Per verificare quanto detto, compilare il file di
snippet 10.22.c passando a gcc il flag
-std=c99.
La direttiva #line
La direttiva del preprocessore #line (Sintassi
10.17 e 10.18) permette di cambiare il numero della corrente riga
di processing del codice e, opzionalmente, di modificare anche il
nome del corrente file di codice sorgente.
Queste informazioni sono utilizzate e mostrate dal compilatore nell’area di output quando nell’ambito del codice sorgente sono presenti, per esempio, degli errori sintattici (Snippet 10.23 e Output 10.11).
Snippet 10.23 Un esempio di errore in un file di codice sorgente.
...
int main(void)
{
a = 10;
...
}
Output 10.11 Informazioni di errore riportate da un compilatore.
10.23.c:6:5: error: 'a' undeclared (first use in this function)
L’Output 10.11 mostra come il compilatore in uso riporti che nel
file 10.23.c alla riga 6 (e colonna
5) del codice sorgente relativo sia occorso l’errore
specificato dalla label error: (la numerazione delle
righe di codice parte da 1 e non da 0).
IMPORTANTE
L’utilizzo di questa direttiva cambia il
risultato delle macro predefinite __LINE__ e
__FILE__ che ritornano, rispettivamente, il numero
della corrente riga di codice sorgente e il nome del corrente file
sorgente.
Sintassi 10.17 La direttiva #line (I forma).
#line digit ["s_char_sequence"]
La Sintassi 10.17 utilizza: digit per fornire il
numero di riga da cambiare, che deve essere un intero compreso tra
1 e 2147483647;
s_char_sequence per fornire il nome di un file
sorgente da sostituire a quello attuale, che deve essere un
letterale stringa formato da una sequenza di caratteri membri del
corrente set che non deve però contenere il carattere doppio apice
", il carattere backslash \ o il
carattere new line.
Snippet 10.24 La direttiva #line (I forma).
#include <stdio.h> // riga 1
#include <stdlib.h> // riga 2
// riga 3
int main(void) // riga 4
{ // riga 5
// cambio la numerazione di riga e il nome // riga 6
// del file di codice sorgente // riga 7
#line 44 "other.c" // riga 8
printf("%d - %s \n",__LINE__, __FILE__); // riga 44
// riga 45
return (EXIT_SUCCESS); // riga 46
} // riga 47
Se mandiamo in esecuzione lo Snippet 10.24 avremo che
__LINE__ riporterà come valore 44 mentre
__FILE__ riporterà come valore
other.c.
Sintassi 10.18 La direttiva #line (II forma).
#line pp_tokens
Con la Sintassi 10.18, invece, si indicano dei token
pre-elaborazione che sono usualmente rappresentati
dall’identificatore di una macro semplice la cui lista di
sostituzione deve contenere dei token che sono in grado di
rappresentare la forma sintattica della direttiva
#line prima citata ovvero, detto in modo più pratico,
la macro deve espandersi in digit
["s_char_sequence"].
Snippet 10.25 La direttiva #line (II forma).
...
#define LINE_AND_FILE 55 "other.c"
int main(void)
{
// cambio la numerazione di riga e il nome del file di codice sorgente
#line LINE_AND_FILE // espansa come 55 "other.c"
printf("%d - %s \n",__LINE__, __FILE__); // 55 - other.c
...
}
Snippet 10.26 La direttiva #line (II forma).
...
// questa macro farà generare al compilatore il seguente messaggio:
// 10.26.c:13:7: error: "other" is not a valid filename
// perché alla riga 13 LINE_AND_FILE non si espanderà nella forma
// sintattica corretta di #line, ossia #line digit ["s_char_sequence"]
#define LINE_AND_FILE 55 other.c
int main(void)
{
// cambio la numerazione di riga e il nome del file di codice sorgente
#line LINE_AND_FILE // espansa come 55 other.c
printf("%d - %s \n",__LINE__, __FILE__); // 55 - other.c
...
}
Analizzando il comportamento della direttiva #line
può sorgere spontanea la seguente domanda: “perché dovremmo voler
cambiare il numero della corrente riga di codice e, nel caso, anche
quello del corrente file sorgente se poi questi valori sono usati
dal compilatore per fornire informazioni utili su dove è occorso un
eventuale errore sintattico?”.
Come risposta possiamo mostrare due esempi di casi d’uso tipici; il primo consente di personalizzare l’output mostrato dal compilatore in caso di emissione di messaggi diagnostici al fine di renderli più significativi (Listato 10.18), mentre il secondo è legato all’uso di appositi tool che generano come output codice sorgente in C (Output 10.13).
Un esempio di un tool del tipo indicato può essere Yacc, il
quale, a partire da un file di input, diciamo parse.y,
che contiene dei token scritti secondo le regole di Yacc e anche
istruzioni proprie di C, genererà un file sorgente in C come
proprio output, diciamo parse.tab.c, che conterrà
delle direttive #line che faranno riferimento, laddove
opportuno, al file di codice parse.y che conterrà le
istruzioni in C lì indicate. In questo modo, se durante la
compilazione di parse.tab.c dovesse occorrere un
errore di compilazione per quelle istruzioni, il compilatore ci
segnalerebbe che le stesse provengono da parse.y
piuttosto che da parse.tab.c (chiaramente questo
favorisce e facilita il debugging del codice perché un
programmatore viene informato che gli errori provengono dal file di
input, ossia parse.y, e non dal file di output
generato, ossia parse.tab.c).
NOTA
Yacc, acronimo di Yet Another Compiler-Compiler, è un generatore di analizzatori sintattici (parser), ovvero un programma che a partire da una grammatica context-free, scritta secondo delle specifiche regole sintattiche, genera del codice sorgente in C di un parser in grado di analizzare il linguaggio proprio della grammatica esplicitata. Di Yacc, sviluppato per Unix agli inizi del 1970 da Stephen Curtis Johnson, è disponibile un porting in ambiente GNU/Linux, scritto da Robert Corbett e Richard Stallman, denominato GNU Bison.
Listato 10.18 LineDirective.c (LineDirective).
/* LineDirective.c :: Un caso d'uso della direttiva #line :: */
#include <stdio.h>
#include <stdlib.h>
void foo(void);
void bar(void);
int main(void)
{
foo();
bar();
return (EXIT_SUCCESS);
}
#line __LINE__ "void foo(void)"
void foo(void)
{
int a = j;
}
#line __LINE__ "void bar(void)"
void bar(void)
{
int a = j;
}
Output 10.12 Dal Listato 10.18 LineDirective.c.
...
void foo(void):17:13: error: 'j' undeclared (first use in this function)
...
void bar(void):22:13: error: 'j' undeclared (first use in this function)
...
Il Listato 10.18 applica delle direttive #line in
testa alle definizioni delle funzioni foo e
bar in modo che quando saranno generati degli errori
da parte del compilatore potremo avere dei dettagli maggiori su
quelle funzioni, che nel nostro caso indicheranno qual è la loro
segnatura completa (Output 10.12).
Output 10.13 File parse.tab.c generato da Yacc a partire dal file parse.y.
...
switch (yyn)
{
case 2:
#line 19 "parse.y" /* yacc.c:1646 */
{
printf("Procedure : %s\n", (yyvsp[-1].sval));
}
#line 1206 "parse.tab.c" /* yacc.c:1646 */
break;
case 6:
#line 30 "parse.y" /* yacc.c:1646 */
{
printf("\tPart : %s\n", (yyvsp[-1].sval));
}
#line 1212 "parse.tab.c" /* yacc.c:1646 */
break;
case 10:
#line 41 "parse.y" /* yacc.c:1646 */
{
printf("\t\tKeyword : %s\n", (yyvsp[0].sval));
}
#line 1218 "parse.tab.c" /* yacc.c:1646 */
break;
#line 1222 "parse.tab.c" /* yacc.c:1646 */
default: break;
}
L’Output 10.13 riporta in modo reale come sono state poste delle
direttive #line all’interno di un file di output di
codice C generato da Yacc a partire da un altro file di input. Per
esempio, una direttiva come #line 19 "parse.y"
farà credere al compilatore che starà processando il file
sorgente parse.y alla cui riga 19 è scritta la
sottostante istruzione printf, sicché se ci sarà un
problema con quest’istruzione, l’output relativo genererà quelle
informazioni piuttosto che il numero di riga corrente del file
parse.tab.c.
Allo stesso tempo, subito dopo, la direttiva #line 1206
"parse.tab.c" “ripristina” le corrette informazioni di
numero di riga e nome di file sorgente in modo che a partire da
quel punto le eventuali informazioni di errore riportino
correttamente che le istruzioni successive provengono, come è
giusto che sia, dal file parse.tab.c.
La direttiva #pragma
La direttiva del preprocessore #pragma (Sintassi
10.19) fornisce al compilatore in uso determinate istruzioni che
gli permettono di eseguire o meno specifiche azioni o comportamenti
(tale direttiva causa, nella pratica, alla corrente implementazione
di comportarsi in un modo a essa dipendente, ossia di usare
caratteristiche a essa specialistiche).
CURIOSITÀ
Il termine pragma si dice che stia per pragmatic (pragmatico) e indica la volontà di far eseguire al compilatore in uso azioni a esso specifiche e che possono essere nella pratica utili per il corrente contesto, in modo per l’appunto pragmatico, che però non sono conformi in modo “dogmatico” a quanto asserito dallo standard di C.
Sintassi 10.19 La direttiva #pragma.
#pragma pp_tokens
Nella Sintassi 10.19 pp_tokens indica i token
specifici per il compilatore in uso (ma anche, se previsti, per il
preprocessore stesso) che indicano le azioni o i comandi che esso
deve eseguire (ogni compilatore può averne di propri e dunque per
ognuno di essi è opportuno riferirsi alla relativa documentazione
che illustra quali sono e come si utilizzano).
ATTENZIONE
L’utilizzo della direttiva #pragma,
essendo strettamente legata alla corrente implementazione, è
sconsigliata se serve scrivere codice portabile tra diverse
piattaforme e/o implementazioni.
Snippet 10.27 La direttiva #pragma.
...
// istruisco il compilatore affinché ogni membro di una struttura sia allineato
// single-byte; non vi saranno mai byte di padding!
#pragma pack(1)
int main(void)
{
// senza la direttiva #pragma pack(1) questa struttura peserebbe in memoria
// 8 byte perché il compilatore porrebbe 3 byte di padding dopo c_data in modo
// che data, di tipo int a 32 bit sul corrente sistema, sia allineato a
// un indirizzo di memoria multiplo di 4
struct S
{
char c_data;
int data;
} s = {'Z', 122};
printf("%zu\n", sizeof (s)); // 5
...
}
Lo Snippet 10.28 mostra l’uso della direttiva
#pragma con il token pack, riconosciuto
dal compilatore in uso, ossia GCC, il quale accetta tra le
parentesi tonde ( ) un valore che indica la quantità
di byte di allineamento dei membri di una struttura (questo valore
di allineamento, tipicamente, è una piccola potenza di 2).
A partire da C99 sono comunque state introdotte le seguenti pragma standard, il cui effetto sarà illustrato nel Capitolo 11:
#pragma STDC FP_CONTRACT ON | OFF | DEFAULT;#pragma STDC FENV_ACCESS ON | OFF | DEFAULT;#pragma STDC CX_LIMITED_RANGE ON | OFF | DEFAULT.
L’operatore _Pragma
L’operatore del preprocessore _Pragma (Sintassi
10.20), introdotto a partire da C99, consente di generare una
direttiva #pragma con i token ricavati dal
corrispettivo letterale stringa passato come operando.
Sintassi 10.20 L’operatore _Pragma.
_Pragma (string_literal)
Cosa si intende, dunque, per generazione di una direttiva
#pragma? Per comprenderla in modo adeguato vediamo
quali sono i passi che il preprocessore compie per elaborare
un’espressione come _Pragma("GCC error \"Errore: usare un
compilatore C11 compliant\"").
- Converte il letterale stringa in una sequenza di token
pre-elaborazione eliminando dal letterale i doppi apici
"iniziali e finali e sostituendo ogni sequenza di escape\"con un doppio apice"e ogni sequenza di escape\\con un singolo backslash\. - Processa i token pre-elaborazione risultanti come se fossero
parte della direttiva
#pragma.
TERMINOLOGIA
Il processo di conversione di un letterale
stringa, operando di _Pragma, in una sequenza di token
pre-elaborazione, è definito dallo standard come
destringizing.
Ritornando alla nostra espressione _Pragma, al
termine dei suddetti passi, la stessa sarà equivalente a una
direttiva #pragma espressa come #pragma GCC
error "Errore: usare un compilatore C11 compliant".
In sostanza, quest’operatore è stato introdotto per aggirare la
limitazione che non è possibile costruire delle direttive per il
preprocessore per effetto dell’espansione di macro (non è in
pratica possibile definire una macro come #define PACK(v)
#pragma pack(v)).
Snippet 10.28 L’operatore _Pragma.
...
#define MAKE_STR(s) #s
#define M_ALIGN(b) _Pragma(MAKE_STR(pack(b)))
int main(void)
{
M_ALIGN(1) // M_ALIGN(1) sarà espansa come: #pragma pack(1)
struct S
{
char c_data;
int data;
} s ={'Z', 122};
printf("%zu\n", sizeof (s)); // 5
...
}
La direttiva nulla
Una direttiva del preprocessore espressa come la Sintassi 10.21 esprime una direttiva che non fa nulla, ossia non ha alcun effetto sull’output generato dal preprocessore.
Sintassi 10.21 La direttiva nulla.
# new_line
Questa direttiva è a volte usata dai programmatori per dare uno stile di formattazione alle altre direttive utilizzate in modo che non vi siano mai spazi bianchi verticali di separazione tra le stesse (Snippet 10.29).
Snippet 10.29 La direttiva nulla.
#if !defined WINDOW
# /* definiamo WINDOWS */
#define WINDOWS
#
#endif
# /* definiamo SYS64 */
#define SYS64
Nomi di macro predefinite
Lo standard di C prevede una serie di macro predefinite alcune
delle quali sono obbligatorie mentre altre sono opzionali. Nelle
macro che seguono, un programmatore non dovrebbe ridefinirle con la
direttiva #define oppure rimuoverle con la direttiva
#undef (GCC emette degli appositi warning di
avviso).
In più queste macro hanno le seguenti caratteristiche: i loro
nomi iniziano con un carattere underscore (_) cui
segue una lettera maiuscola oppure un secondo carattere underscore
(_); il loro valore, eccetto che per le macro
__FILE__ e __LINE__, rimane costante per
tutta l’unità di traduzione.
NOTA
Un’implementazione non dovrebbe definire la macro
riservata __cplusplus.
Macro obbligatorie
Le macro che seguono devono essere obbligatoriamente definite da un’implementazione.
__DATE__: fornisce come letterale stringa e nel formato"Mmm dd yyyy"la data di compilazione della relativa unità di traduzione pre-elaborazione.__FILE__: fornisce come letterale stringa il nome del corrente file sorgente.__LINE__: fornisce come costante intera il numero di riga della corrente riga di codice sorgente.__STDC__: fornisce come costante intera il valore1se la corrente implementazione è conforme allo standard di C.__STDC_HOSTED__: fornisce come costante intera il valore1, se la corrente implementazione è una hosted implementation, e il valore0se è una freestanding implementation.__STDC_VERSION__: fornisce come costante intera un valore di tipolong intche esprime l’anno e il mese del corrente standard. Per esempio, il valore199901Lidentifica lo standard C99; il valore201112Lidentifica lo standard C11.__TIME__: fornisce come letterale stringa e nel formato"hh:mm:ss"l’orario di compilazione della relativa unità di traduzione pre-elaborazione.
TERMINOLOGIA
Una hosted implementation è
un’implementazione di C che fa girare i programmi in un ambiente di
esecuzione host come un sistema operativo e che mette a
disposizione il supporto completo delle funzionalità della libreria
standard. Una freestanding implementation, invece, è
un’implementazione di C che fa girare i programmi senza il supporto
di un sistema operativo e che fornisce solo un limitato set di
funzionalità della libreria standard (header:
<float.h>, <iso646.h>,
<limits.h>, <stdalign.h>,
<stdarg.h>, <stdbool.h>,
<stddef.h>, <stdint.h> e
<stdnoreturn.h>) e di eventuali altri librerie
implementation-defined.
Listato 10.19 MandatoryMacros.c (MandatoryMacros).
/* MandatoryMacros.c :: Macro obbligatorie :: */
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
printf("__DATE__ = %s\n", __DATE__);
printf("__FILE__ = %s\n", __FILE__);
printf("__LINE__ = %d\n", __LINE__);
printf("__STDC__ = %d\n", __STDC__);
printf("__STDC_HOSTED__ = %d\n", __STDC_HOSTED__);
printf("__STDC_VERSION__ = %ld\n", __STDC_VERSION__);
printf("__TIME__ = %s\n", __TIME__);
return (EXIT_SUCCESS);
}
Output 10.14 Dal Listato 10.19 MandatoryMacros.c.
__DATE__ = Nov 26 2014
__FILE__ = MandatoryMacros.c
__LINE__ = 9
__STDC__ = 1
__STDC_HOSTED__ = 1
__STDC_VERSION__ = 201112
__TIME__ = 15:22:58
Macro di ambiente
Le macro che seguono possono essere opzionalmente definite da un’implementazione.
__STDC_ISO_10646__: fornisce come costante intera un valore di tipolong intnella formayyyymmL(per esempio199712L) che indica la data della versione dello standard Unicode utilizzato per la codifica dei caratteri per il tipowchar_t.__STDC_MB_MIGHT_NEQ_WC__: fornisce come costante intera il valore1se nella codifica di un tipowchar_tun membro di un set di caratteri basico può avere un codice che differisce dal suo valore come letterale carattere ordinario. Per esempio, se su un sistema è definita la macro__STDC_ISO_10646__ma non questa macro, una comparazione tra i letterali'\12'e'\n'deve essere uguale a true, ossia entrambi devono avere lo stesso valore, ovvero il valoreU+000Aproprio del set di caratteri Unicode.__STDC_UTF_16__: fornisce come costante intera il valore1per indicare che valori di tipochar16_tsono codificati in UTF-16. Se è utilizzato un altro sistema di codifica questa macro non deve essere definita.__STDC_UTF_32__: fornisce come costante intera il valore1per indicare che valori di tipochar32_tsono codificati in UTF-32. Se è utilizzato un altro sistema di codifica questa macro non deve essere definita.
NOTA
Nel Capitolo 11 analizzeremo il sistema di
codifica Unicode e i tipi wchar_t,
char16_t e char32_t.
Listato 10.20 EnvironmentMacros.c (EnvironmentMacros).
/* EnvironmentMacros.c :: Macro di ambiente :: */
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
#if defined (__STDC_ISO_10646__) && (__STDC_ISO_10646__ > 0L)
printf("__STDC_ISO_10646__ = %ld\n", __STDC_ISO_10646__);
#else
printf("__STDC_ISO_10646__ = %s\n", "not defined!");
#endif
#if defined (__STDC_MB_MIGHT_NEQ_WC__) && (__STDC_MB_MIGHT_NEQ_WC__ == 1)
printf("__STDC_MB_MIGHT_NEQ_WC__ = %d\n", __STDC_MB_MIGHT_NEQ_WC__);
#else
printf("__STDC_MB_MIGHT_NEQ_WC__ = %s\n", "not defined!");
#endif
#if defined (__STDC_UTF_16__) && (__STDC_UTF_16__ == 1)
printf("__STDC_UTF_16__ = %d\n", __STDC_UTF_16__);
#else
printf("__STDC_UTF_16__ = %s\n", "not defined!");
#endif
#if defined (__STDC_UTF_32__) && (__STDC_UTF_32__ == 1)
printf("__STDC_UTF_32__ = %d\n", __STDC_UTF_32__);
#else
printf("__STDC_UTF_32__ = %s\n", "not defined!");
#endif
return (EXIT_SUCCESS);
}
Output 10.15 Dal Listato 10.20 EnvironmentMacros.c.
__STDC_ISO_10646__ = 201103
__STDC_MB_MIGHT_NEQ_WC__ = not defined!
__STDC_UTF_16__ = 1
__STDC_UTF_32__ = 1
Macro per caratteristiche opzionali
Le macro che seguono possono essere opzionalmente definite da un’implementazione.
__STDC_ANALYZABLE__: fornisce come costante intera il valore1se la corrente implementazione è conforme alle specifiche dell’Allegato L presente nella specifica di C11 (Annex L Analyzability). In breve, un compilatore conforme alle norme dell’Allegato L dovrebbe garantire che i comportamenti non definiti di un programma, ossia i “temibili” undefined behaviour, siano limitati a quelli definiti come bounded, cioè a quelli che sono in qualche modo prevedibili, quindi non critici, e per i quali un’implementazione può fare qualcosa di ragionevole. In ogni caso l’Allegato L enumera anche una serie di operazioni per le quali è permessa la possibilità di far risultare un tipo di undefined behaviour critico. Quanto sopra è stato standardizzato al fine di garantire una migliore robustezza e sicurezza dei programmi in C.__STDC_IEC_559__: fornisce come costante intera il valore1se la corrente implementazione è conforme alle specifiche dell’Allegato F presente nella specifica di C11 (Annex F IEC 60559 floating-point arithmetic). Se, dunque, un’implementazione definisce questa macro, si può assumere che essa aderisce all’importante standard IEEE 754 (conosciuto anche come IEC 60559), il quale definisce delle regole per i sistemi di computazione in virgola mobile, ovvero formalizza come devono essere rappresentati, quali operazioni possono essere compiute, le conversioni operabili e come devono essere gestite le condizioni di eccezione come, per esempio, la divisione per 0.__STDC_IEC_559_COMPLEX__: fornisce come costante intera il valore1se la corrente implementazione è conforme alle specifiche dell’Allegato G presente nella specifica di C11 (Annex G IEC 60559-compatible complex arithmetic). In questo caso un’implementazione che definisce tale macro garantisce la possibilità di utilizzare l’aritmetica “complessa” così come formalizzata dallo standard IEEE 754.__STDC_LIB_EXT1__: fornisce come costante intera di tipolong intun valore espresso nel formato201ymmLche indica il supporto per le estensioni definite nell’Allegato K presente nella specifica di C11 (Annex K Bounds-checking interfaces). Questo allegato specifica una serie di estensioni opzionali che sono utili per migliorare la sicurezza dei programmi in C definendo una serie di nuove funzioni, macro e tipi dichiarati nei correnti header file della libreria standard.__STDC_NO_ATOMICS__: fornisce come costante intera il valore1se la corrente implementazione non supporta i tipi atomici (non dispone del qualificatore di tipo_Atomice dell’header<stdatomic.h>).__STDC_NO_COMPLEX__: fornisce come costante intera il valore1se la corrente implementazione non supporta i tipi complessi e non dispone dell’header<complex.h>.__STDC_NO_THREADS__: fornisce come costante intera il valore1se la corrente implementazione non supporta i thread e non dispone dell’header<threads.h>.__STDC_NO_VLA__: fornisce come costante intera il valore1se la corrente implementazione non supporta gli array di lunghezza variabile.
Listato 10.21 ConditionalFeatureMacros.c (ConditionalFeatureMacros).
/* ConditionalFeatureMacros.c :: Macro per caratteristiche opzionali :: */
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
#if defined (__STDC_ANALYZABLE__) && (__STDC_ANALYZABLE__ == 1)
printf("__STDC_ANALYZABLE__ = %ld\n", __STDC_ANALYZABLE__);
#else
printf("__STDC_ANALYZABLE__ = %s\n", "not defined!");
#endif
#if defined (__STDC_IEC_559__) && (__STDC_IEC_559__ == 1)
printf("__STDC_IEC_559__ = %d\n", __STDC_IEC_559__);
#else
printf("__STDC_IEC_559__ = %s\n", "not defined!");
#endif
#if defined (__STDC_IEC_559_COMPLEX__) && (__STDC_IEC_559_COMPLEX__ == 1)
printf("__STDC_IEC_559_COMPLEX__ = %d\n", __STDC_IEC_559_COMPLEX__);
#else
printf("__STDC_IEC_559_COMPLEX__ = %s\n", "not defined!");
#endif
#if defined (__STDC_LIB_EXT1__) && (__STDC_LIB_EXT1__ > 0)
printf("__STDC_LIB_EXT1__ = %ld\n", __STDC_LIB_EXT1__);
#else
printf("__STDC_LIB_EXT1__ = %s\n", "not defined!");
#endif
#if defined (__STDC_NO_ATOMICS__) && (__STDC_NO_ATOMICS__ == 1)
printf("__STDC_NO_ATOMICS__ = %d\n", __STDC_NO_ATOMICS__);
#else
printf("__STDC_NO_ATOMICS__ = %s\n", "not defined!");
#endif
#if defined (__STDC_NO_COMPLEX__) && (__STDC_NO_COMPLEX__ == 1)
printf("__STDC_NO_COMPLEX__ = %d\n", __STDC_NO_COMPLEX__);
#else
printf("__STDC_NO_COMPLEX__ = %s\n", "not defined!");
#endif
#if defined (__STDC_NO_THREADS__) && (__STDC_NO_THREADS__ == 1)
printf("__STDC_NO_THREADS__ = %d\n", __STDC_NO_THREADS__);
#else
printf("__STDC_NO_THREADS__ = %s\n", "not defined!");
#endif
#if defined (__STDC_NO_VLA__) && (__STDC_NO_VLA__ == 1)
printf("__STDC_NO_VLA__ = %d\n", __STDC_NO_VLA__);
#else
printf("__STDC_NO_VLA__ = %s\n", "not defined!");
#endif
return (EXIT_SUCCESS);
}
Output 10.16 Dal Listato 10.21 ConditionalFeatureMacros.c.
__STDC_ANALYZABLE__ = not defined!
__STDC_IEC_559__ = 1
__STDC_IEC_559_COMPLEX__ = 1
__STDC_LIB_EXT1__ = not defined!
__STDC_NO_ATOMICS__ = not defined!
__STDC_NO_COMPLEX__ = not defined!
__STDC_NO_THREADS__ = 1
__STDC_NO_VLA__ = not defined!
Tabella di riepilogo delle macro predefinite
| Identificatore della macro | C90 | C99 | C11 |
|---|---|---|---|
__DATE__ |
√ | ||
__FILE__ |
√ | ||
__LINE__ |
√ | ||
__STDC__ |
√ | ||
__STDC_HOSTED__ |
√ | ||
__STDC_VERSION__2 |
√ | ||
__TIME__ |
√ | ||
__STDC_ISO_10646__ |
√ | ||
__STDC_MB_MIGHT_NEQ_WC__ |
√ | ||
__STDC_UTF_16__ |
√ | ||
__STDC_UTF_32__ |
√ | ||
__STDC_ANALYZABLE__ |
√ | ||
__STDC_IEC_559__ |
√ | ||
__STDC_IEC_559_COMPLEX__ |
√ | ||
__STDC_LIB_EXT1__ |
√ | ||
__STDC_NO_ATOMICS__ |
√ | ||
__STDC_NO_COMPLEX__ |
√ | ||
__STDC_NO_THREADS__ |
√ | ||
__STDC_NO_VLA__ |
√ | ||
| 1 Il segno di spunta √ indica a partire da quale standard di C la macro è stata introdotta. | |||
2 La macro __STDC_VERSION__
è stata in effetti introdotta nel I emendamento di C90, ossia nel
documento ISO/IEC 9899/AMD1:1995. |
|||